
Stable Diffusionを使ってVRoid動画をアニメ風動画に変える

この記事では、VRoidから、Stable Diffusionを使ってのアニメ風動画の作り方の解説をします。いずれこの方法は、いろいろなソフトに搭載され、もっと簡素な方法になってくるとは思うのですが。今日現在(2023年5月7日)時点でのやり方です。目標とするのは下記のような動画の生成です。(センシティブ設定を受けているので、Youtubeのリンクも貼っておきます)
m2mのt2iでControlNetのtile、Openpose、Lineartの合わせ技で初めて手の形状を維持する出力ができた。m2mの指定動画で、3種のControlNet全てに別々に同じ動画を指定する必要がある。これがわからなくて、t2iでControlNetがうまく動かなくて悩んだ。3回ぐらい実施して前2回は失敗 #VRM #AIイラスト pic.twitter.com/1pZHOZMl0M
— Alone1M (@Alone1Moon) May 6, 2023
しばらく前から、Stable Diffusionを使って、Gif画像での生成を試されている方がいて、やってみたいなと思っていました。VRoidのような3Dアバターキャラをアニメ風に変えると、面白い映像が作り出せるのではないかと考えていました。
852話さんや、toyxyzさんがしばらく前から何度も投稿されているのを見ていて、自分の環境でもやってみたいなと。なかなか時間かかるので、今回のGWでやっと試せたという感じです。
#7 Setting the denoising strength lower than 1.0 can reduce flicker more, but it causes the color problem, just like the loopback script. Left : 1.0 / Right : 0.9 pic.twitter.com/sQeVwrKYL1
— toyxyz (@toyxyz3) March 18, 2023
方法はいろいろなアプローチがあると思うのですが、私の方法は4つのステップで行いました。
素材動画をVRoid Hubと、OBSを使って用意
Stable Diffusionに使いやすいようにDaVinci Resolveを利用して加工
Stable DiffusionでControlNetのm2m(Movie-to-Movie)を設定して、連番画像を出力
連番画像を、DaVinci Resolveで動画に統合
順を追って説明していきます。
1. 素材動画をVRoid Hubと、OBSを使って用意
まずは、素材とする動画を用意する必要があります。Stable Diffusionでの連番作成は10秒程度でも4000番台のGPUでも、かなり時間がかかるので、今回は10秒の動画を作成するのを目標とします。
元となる動画はなんでもいいのですが、何枚も連番で出すときには、Stable DiffusionのAIでの判定がミスりやすく、まるで違う画像を生成しやすいので、シンプルな画像がよいだろうと予想していました。そのため、あまり装飾が付いていないアバターで、背景が白のものを素材として意識しました。
素材ネタをいくつか考えるうちに、VRoid Hubのプレビュー画面で十分なのではと気がつきました。Vroid Studioを使って、以前、自分のキャラを作成したことがあり、そのキャラクターを表示させました。
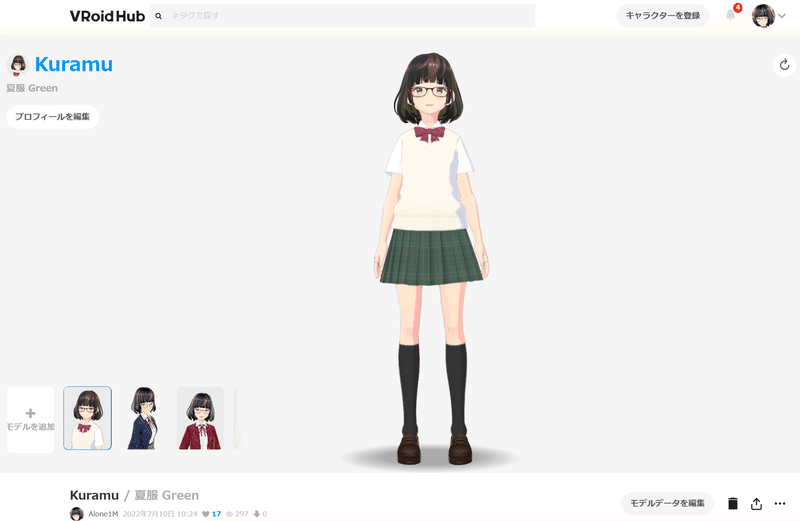
自キャラを登録している場合、表示状態で選択式のディフォルトのループアニメーションが付いています。全身で撮影してもいいのですが、解像度が低いと顔が潰れそうだなという予感がしたので、上半身が写るように設定し、全画面表示にしました。

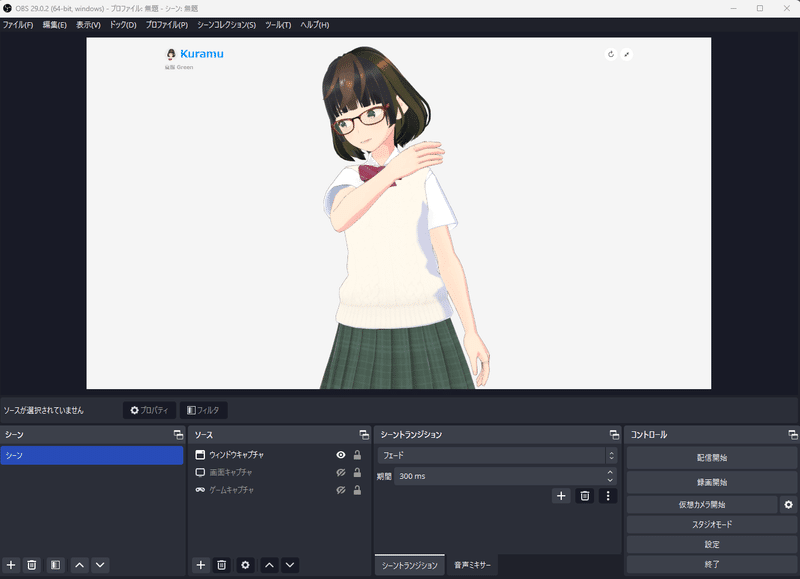
動画の撮影は、ゲーム配信でよく使われるOBS Studioを使いました。
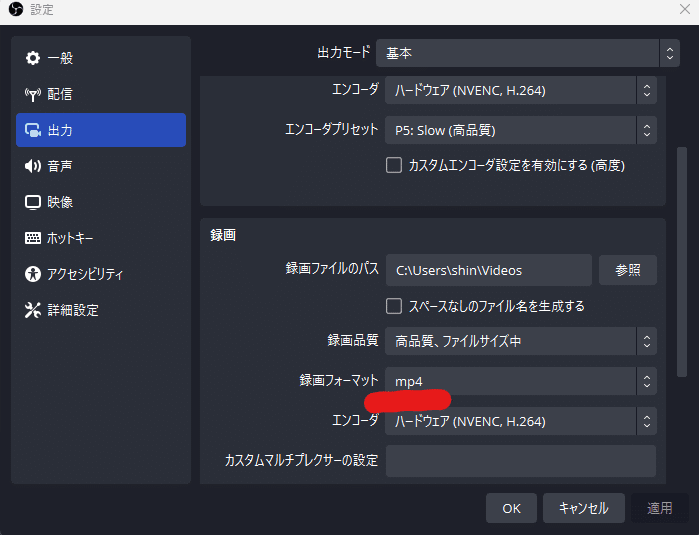
OBS、そのまま撮影すると1秒60フレームで撮影されます。そうすると、生成時に1秒間で60枚生成されるので、あまりに処理にかかる時間がかかるので、20フレーム(3分の1)にしています(もしかすると、もっと適切な数値があるかもしれません)。録画フォーマットもmp4に設定しておきます。
それでループモーションが1周する10秒ほど撮影しました(ループモーションによって長さは違います)。

2.Stable Diffusionに使いやすいようにDaVinci Resolveを利用して加工
撮影が完了したら、横長の白い部分は必要ないのと、縦で動画を作りたかったので、動画編集ソフトのDaVinci Resolve(無料)を使って、縦長画像に修正します(横長でもよければ、そのままでも問題ありません)。いろいろなサイトに解説されているので、混乱したのですが、以下の説明がわかりやすかったです。
プロンプトを確定させるために、検証用に2~3秒程度の短いものの書き出しをしておくといいです。
また、動画からやはり検証用に、動画プレイヤーのVLCなどを使って1枚スナップショットを作っておくのもおすすめです。

3.Stable DiffusionでControlNetのm2m(Movie-to-Movie)を設定して、連番画像を出力
素材動画ができたら、Stable Diffusionのm2mの機能を使っていよいよ連番画像の作成を行います。m2mはすでにControlNetのプログラムの中に同梱されているようで、Settingの以下のチェックボックスを設定するだけで機能するようになります。
やり方については、謎技研様のサイトを参考にしました。
作業はt2iで実施します。
まずは、セットしたものが適切に動くか、1枚スクショでプロンプトを検証します。アニメ風の絵柄を出すことが目的なので、チェックポイントは、BreakDomain_m1808 を使いました。ファイルサイズは、元の動画よりも小さ目の半分のサイズの540x960(縦横は同じ比率である必要があります)。DPM++SDE Karras、Sampling Stepは20で、実施しました。
プロンプトは以下のような感じですが、Interrogateで作成したものに、いつも使っているアニメ風に寄せるためのものです。
1girl, solo, artist_name, bangs, black_hair, bob_cut, (red bow, red bowtie: 1.2), brown_hair, closed_mouth, collared_shirt, eyebrows_visible_through_hair, glasses, green_eyes, green_skirt, multicolored_hair, pleated_skirt, red_bow, red_bowtie, school_uniform, shirt, short_hair, short_sleeves, (green skirt :1.5), solo, streaked_hair, (white cream sweater_vest :1.5), white_shirt, (simple background, white background: 1.5),(beautiful detailed face, beautiful detailed eyes), High contrast, (best illumination, an extremely delicate and beautiful) , (cel shading, bold outlines, flat colors, sharp shadows, manga influence, clean linework, striking visuals:1.2), (pale hues smeared watercolor:1)
Negative prompt: 2girls, nipples,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, (worst quality, low quality:1.4), monochrome, zombie,
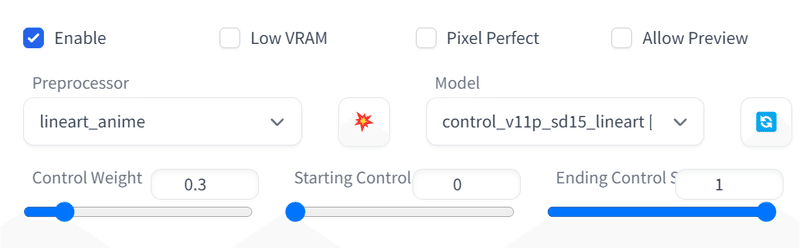
ControlNetのかけ方ですが、いろいろ試したのですが、私の場合は、3つのControlNetを使っています。ControlNetのTile、Openpose、LineartAnimeの3つ掛けを組み合わせています。
Tileを使うことで元の素材の色を引き継いでくれます。

Openposeは、元絵が動き回ったときの体型崩れを減らす効果があり、
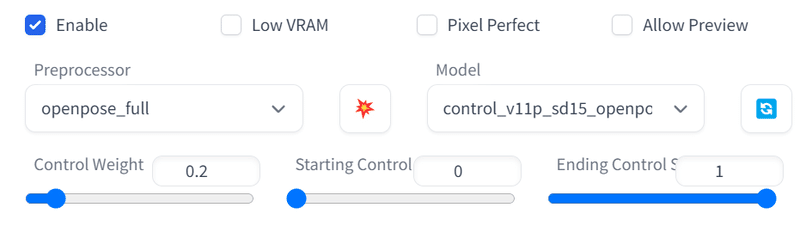
LineartAnimeは、指などの解釈違いを減らす効果があります。
その結果、1枚画像では下記のような結果になりました。

それで満足する結果が出た場合、今度は2~3秒の検証用の動画で生成してみます。その際に、Seed値をなんでもいいので、入力をしておいてください。画像のばらつきを抑える効果があります。「123456」みたいな適当なので問題ありません。
動画生成する際に、注意が必要なのは、ControlNetのm2mの設定です。ControlNetでは、すべて空欄にしておく必要があり、またm2mのところにはそれぞれにすべて同じ動画を設定しておく必要があります。そうでないと適切に動作しません。

また、生成途中で中断した場合、Stable Diffusionの挙動がおかしくなるので、Stable Diffusionの再起動が必要になります。
そして、生成終了後に、連番画像以外に以下のフォルダに自動的にGIFが生成されます。
/stable-diffusion-webui/outputs/txt2img-images/controlnet-m2m/
ただし、これは、あらかじめフォルダを用意しておかないと書き出されないようなので、新規フォルダを作成して、「controlnet-m2m」に名前を変えておいてください。
GIFを見て、それなりに狙ったとおりの品質が出ていると思ったら、10秒版の長いバージョンをControlNetに設定して、いよいよ本番の作成です。GPUの能力で生成にかかる時間が決まるので、環境によりますが、かなり時間がかかるので、別のことをして暇を潰していましょう。
計測してみたところ、筆者のRTX4090環境で3秒間を生成するのに30分。1秒あたり10分という計算なので、10秒だと100分かかる計算になります。あまりに時間がかかるという方は、生成サイズを小さくして計算量を抑えるのをおすすめします。

4.連番画像を、DaVinci Resolveで動画に統合
連番画像の出力が終了したら、DaVinci Resolve持っていき、動画に出力する工程になります。
DaVinci Resolveは連番であると認識すると、ソフト内でGIFのように自動的に扱ってくれます。そのため、Windowsの機能を使って全ファイルのリネームをするのがおすすめです。対象となるファイルを全選択した状態で、「名前の変更」を行うだけで、同一の名前の連番にファイル名を変えてくれるので、とても便利です。

このサイトに解説がありました。
DaVinci Resolveでの連番画像を動画に変換する方法は、以下の方法がわかりやすかったです。操作が初めてだとちょっと迷いますが、難しくはありません。
それで動画は完成です。
一応狙ったとおりのものにはなりました。
どうしても一部、判定がミスったりするのが出てくるので、そこだけ別画像を生成して、修正したりするとより品質も上がると思います。このテクニックを応用するだけで、いろいろな画像が出せるようになるはずです。背景付きの動画であっても、Depthなどを組み合わせるとうまくいくということもあるそうです。
5. おまけ
バニーガール風でも作成してみました。(多分センシティブ設定が出てしまうので、リンクを表示してみてください)
15秒。かなり長かった(計算時間がw)今回は頭の3秒だけを切り出してまず試して、プロンプトやらControlNetの数値を確定させてから、15秒全体の計算に入ったのでやり直し時間がだいぶ減少。次にやるときには、部分的なミス数コマを再生成できるように、CNの画像も残そう #AIイラスト #VRM pic.twitter.com/ozIvL9wRNX
— Alone1M (@Alone1Moon) May 6, 2023
さらには、Depthを使って生成した画像をまとめてフォルダごとのBatch処理を施すことで、Looking Glass Portraitで立体視可能な画像にすることもできます。
背景がなかったりするので期待したほどの驚く品質ではなかったもののちゃんと立体感を感じられる表示にはなってました #LookingGlassPortrait #AIイラスト pic.twitter.com/GtBaggkryo
— Alone1M (@Alone1Moon) May 7, 2023
一応、動画も上げておきます。どうにかダウンロードして頂いて、突っ込んで頂ければ、そのまま立体になります。#LookingGlassPortrait pic.twitter.com/06ZggiCkKV
— Alone1M (@Alone1Moon) May 7, 2023
まだ、色々手間がかかるのですが、そのうち、いろんな動画系ソフトには標準装備されるようになって、手軽に出力できるようになるだろうなあと思うのですが、今、Stable Diffusionを使って、動画を作ってみたい人は試してみてください。
この記事が気に入ったらサポートをしてみませんか?