
RAGによる社内データ利活用〜社内FAQシステム編

はじめに
多くの企業が生成AIの導入を検討する中で、最も要望の多い事例として、社内ナレッジの活用に挙げられるのではないでしょうか。本記事では、企業固有の情報に基づいた社内FAQシステムについてご紹介します。このシステムは、Retrieval-Augumented-Generation(RAG)を活用し、汎用AIでは難しい、企業独自情報に基づいた、質問に即した回答を提供します。
社内ドキュメント活用の現状と課題
要望が多い背景として、多くの企業で膨大な社内ドキュメントやナレッジを蓄積していますが、効果的な活用ができていないのが現状です。
経費精算の手順や有給休暇の申請方法など、社員にとって重要度の高い情報であっても、迅速に答えを見つけられない経験は、どなたでもお持ちでないでしょうか。この問題を引き起こす具体的な要因について、既存の社内FAQツールやチャットボットを例に分析していきましょう。
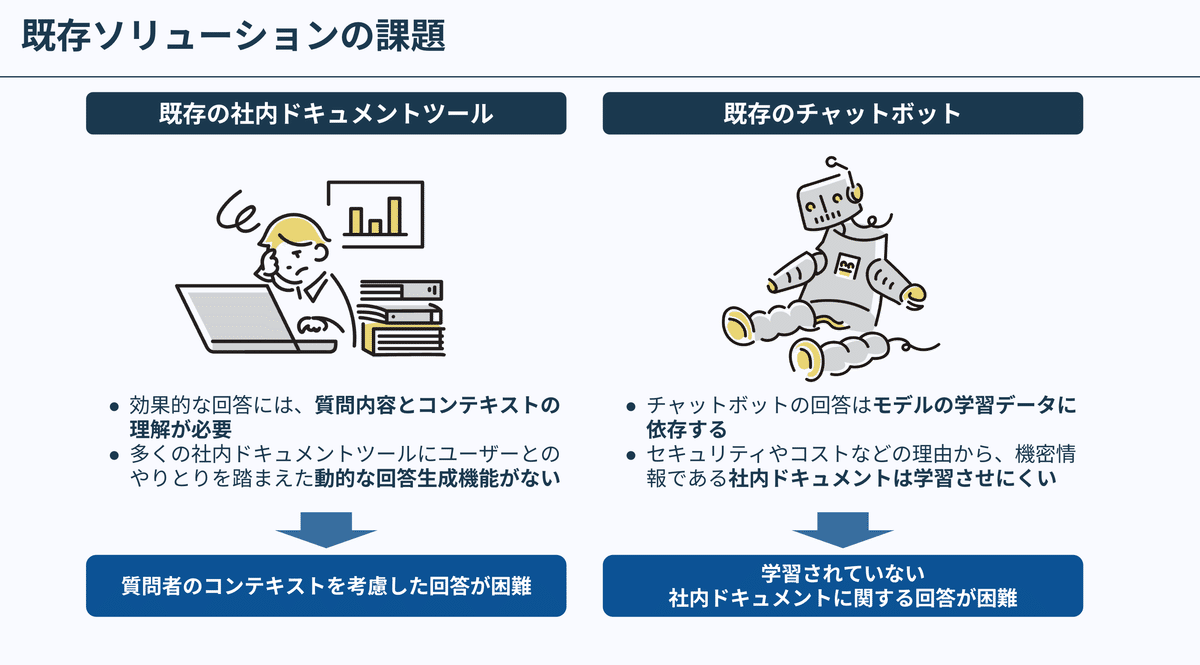
既存の社内ドキュメントツールにおける課題
wikiをはじめとするAI未活用の社内ドキュメントツールにおける課題について解説していきます。
効果的な回答には、「質問者情報」「背景・意図」「質問内容」の3要素の理解が不可欠です。
質問者情報:誰が質問しているか(役職、年齢、性別、部署など)
背景・意図:なぜその質問をしているか(直面している問題、目的など)
質問内容:具体的に何を知りたいのか
しかし、既存システムの多くは「質問内容」のみに焦点を当てており、他2要素を十分に考慮できていません。この結果、質問者のニーズを捉えて、的確な回答を提供することが困難になっています。
例えば、同じ「休暇申請の方法」という質問でも、質問者の観点から、勤続年数によって利用可能な休暇の種類・長さが変わってきたり、所属部署によって申請プロセスが変わってきます。また、背景・意図の観点からも、急な体調不良で休暇を取りたいのか、育児のためなのか、代休なのか、で休暇申請プロセスが変わってきます。
このように、既存のFAQツールは、事前に用意された質問と回答のセットに依存しているため、想定にない質問は、ユーザーの具体的な状況に応じた適切な情報を提供することが難しいです。結果として、ユーザーは、検索結果のうち、得られたいくつかの回答を参考に、自分の状況に当てはめて解釈する必要があります。
既存のチャットボットにおける課題
既存のチャットボットは、会話からコンテキスト情報を考慮した回答を生成する能力を持っています。この特性により、会話を通じて、ユーザーの質問の意図をある程度理解して、関連した情報を提供できます。しかしながら、チャットボットにも課題があります。
チャットボットの課題は、学習データに含まれていない情報にまつわる回答はできないことです。チャットボットの回答はモデルの学習データに依存しています。そして、企業特有の情報は一般的には公開されていません。よって、既存のチャットボットには学習されていない可能性が高く、既存のチャットボットに学習されていない社内ドキュメントに関する回答は得られません。
もちろん、モデルに、社内データを学習させれば、社内データを理解したチャットボットを作ることも可能です。しかしながら、現状、このアプローチには高いコストがかかり、投資対効果が見合わないため最適解とはいえません。
解決策としてのRAG
そこで、RAG(Retrieval-Augmented Generation)技術を提案します。RAGは外部データソース(この場合は社内ドキュメント)を活用して、AIモデルの回答生成を強化します。ユーザーが質問を入力すると、システムは関連する社内情報を検索し、それをもとに適切な回答を生成します。
RAGアーキテクチャ


RAGの利点
RAGの利点としては、前述した「コンテキストを考慮した回答ができる」、「企業固有の情報に対応できる」以外にも「拡張性が高い」ことと「生成結果の信頼性が高まる」ことが挙げられます。
拡張性が高い
拡張性の面では、一度外部データソースを構築すれば、それを元に幅広い質問に答えることができます。外部データソースに新しい情報や文書を追加していくことで、システムの知識ベースを容易に拡張できるため、常に最新の情報を提供することも可能です。
生成結果の信頼性が高まる
RAGではLLMが外部データソースから検索した情報を基に回答を生成するため、より正確で信頼性の高い情報を提供できます。また、回答の根拠となる情報ソースを明示できるため、ユーザーは必要に応じて元の文書を参照し、情報の確認や深掘りを行うことができます。
RAG導入における検討項目
実際に導入を進めていく上で、何に考慮すべきかについて記載していきます。
いくつか上げていきます。参考になれば幸いです。

データの質と量
大前提として、そもそもRAGが組織にとって最適なソリューションなのかを検討すべきです。ここでいうと、そもそも検索に工数がかかっていない(≒データ量が少ない)場合はわざわざ外部DBが必要でないため、RAGを構築する必要はありません。
RAG導入の期待効果が最も高い企業は、高品質かつ大量のデータを保有しています。データの品質が高いため、前処理工数が少なく、データ量が多い(検索に工数がかかっている可能性が高い)ため、業務効率化によるアップサイドが大きいからです。一方でそういった企業は稀なので、段階的なRAG導入を検討すべきです。一般的には、クイックにデータの前処理をしやすいように、データ量を制限し、RAGしやすい環境を用意した上で、PoCを始める案件が多いです。
RAG導入によるビジネスインパクト
また、技術的精度のみに注力するのではなく、RAG導入によるビジネスインパクトの測定すべきです。一般的には、RAGの目的は業務効率化です。
測定の一例として、マッチ率があります。これはRAGが質問に対して適切な情報を提供できた割合を示します。この指標が向上すれば、ユーザーが必要な情報を素早く見つけられるようになり、結果として検索として検索時間の短縮につながります。この指標を用い、ユーザーが検索にかけていた工数の削減時間、削減されたコストなどを算出することができます。
セキュリティ
最後にセキュリティです。おそらく、RAGで活用したいデータには機密性の高い情報が含まれるため、適切なセキュリティ対策が必要です。
世の中には、環境構築不要で簡単に利用できるRAGチャットツールが存在します。しかし、それらの多くは、第三者の環境に情報を置くため、機密情報が多い社内データの保管場所としては適切ではありません。セキュリティが担保されている環境でのRAGを構築することを推奨します。
おわりに
本記事では、社内ドキュメント活用に向けたRAGについて解説しました。RAGを活用することで、社内の膨大な知識を効率的に活用し、必要な情報を迅速かつ正確に提供できます。本記事であげた社内FAQ以外にも、カスタマーサポートや分析レポート作成など様々な場面で適用可能であり、業務の効率化に寄与します。
弊社のAI Transformation(AX)事業部では、RAGの実装にとどまらず、経営層の課題解決に直結する戦略的AI導入と、現場のニーズに即したユースケース開発を両輪に、AI活用による業務変革(AX)をご支援しております。
ご興味ある人は下記からご連絡ください。