
わんコメ/棒読みちゃんでのコメント読み上げでユーザ名は日本語エンジンを使いつつ、本文は英語と日本語エンジンを使い分ける

最近配信の読み上げにわんコメを導入して、棒読みちゃんと連携させながら使い始めました。
それまで使っていたTwitchTalkAppと棒読みちゃんの連携では英語と日本語で勝手に音声エンジンが使い分けられていたのですが、わんコメ導入時にすべて日本語用の音声エンジン(ずんだもん)で読み上げられるようになっててました。英語のときは英語の音声エンジンに読み上げられたい(唐突に流暢な英語で読まれるのが気に入ってるらしい)というヒトがいたので、ちょっと対応することにしました。
実現したい要件
英語でコメントしたときは英語の音声エンジンで読ませたい
日本語でコメントしたときは日本語の音声エンジンで読ませたい
日本語と英語が混在したコメントは日本語の音声エンジンで読ませたい
読み上げ時にはユーザ名とコメント内容を同時に読み上げたい
ユーザ名は日本語の音声エンジンで読ませたい
ただ英語と日本語を読み分けさるだけなら結構色んな人が解説していて難しくなかったりするんですが、わんコメのtwitchユーザ名を読み上げに含める機能を使おうとしたせいで少しややこしくなりました。
設定
わんコメから終端文字を含めたコメントを棒読みちゃんに流す
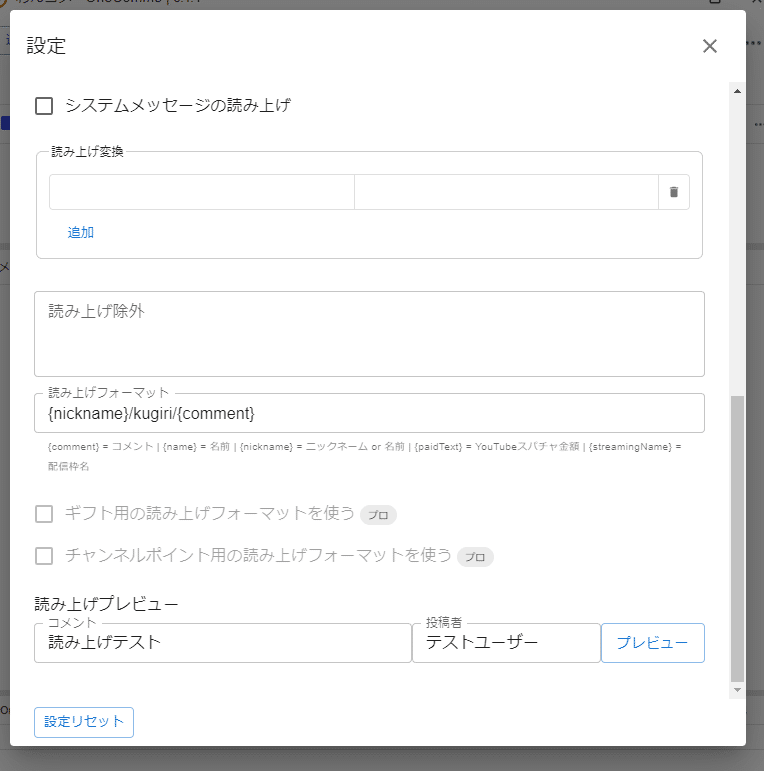
わんコメから棒読みちゃんにわたすコメント内容のフォーマットをある程度自由に決められるので、その中に正規表現で処理するための区切りになる終端文字を含めることにします。これはわんコメや棒読みちゃんで何か定義しているわけではないので、コメントされないであろう文字列ならなんでもいいです。
今回は適当に `/kugiri/` という終端文字を勝手に定義してわんコメの設定で指定します。最初は記号のみで区切ろうとしましたが、扱いずらかったのでやめました。
棒読みちゃんに音声エンジンと正規表現を設定する
とりあえず設定 => SAPI / Speech Platformから `日本語用エンジンのみをリストアップする` の設定をfalseにします。これで英語の音声エンジンも選択可能になります。

システム => 音声合成エンジンから使いたいエンジンのIDを確認しておきます。

棒読みちゃんでは正規表現を使って読み上げる音声エンジンを指定することが出来ます。辞書登録 => タグ => 正規表現から以下のように正規表現を設定します。
優先度: 100
正規表現: ^(.+)/kugiri/([a-zA-Z0-9!-/:-@[-`{-~\s]+)$
置換後: (Voice ${日本語のエンジンのID})$1 (Voice ${英語のエンジンのID})$2優先度: 99
正規表現: ^(.+)/kugiri/(.+)$
置換後: (Voice ${日本語のエンジンのID})$1 (Voice ${日本語のエンジンのID})$2
優先度は最初の正規表現の方が高ければ具体的な数値はなんでもいいです。
最初の正規表現では終端文字以前の部分を日本語のエンジンで読むように置換し、本文が英数字と記号で構成されている場合は英語のエンジンで読むように指定しています。
2つ目の優先度の低い正規表現では、前半部分は同じで、終端文字以降の部分を無条件で日本語の音声エンジンに読ませています。優先度を低くしているので、この英語のみのコメント内容がこの正規表現でマッチすることはないため無条件に日本語エンジンに渡すシンプルな設定で問題ないです。
この記事が気に入ったらサポートをしてみませんか?