
LogstashやFluentdで、正規表現の書き方による性能問題を防ぐには

こんにちは!
Airitechビッグデータ・AI活用グループのニャンリンアウンです。データ分析用Logstashの設定開発や、Logstashの設定のメンテナンスなどを作業しております。
LogstashやFluentdは、ログのフォーマットを正規表現で指定して、必要な値を取り出すことができます。
正規表現でデータ抽出ルールを記載することで柔軟な処理ができますが、正規表現の書き方が悪いと、性能問題を引き起こしてしまい、データの流れが詰まってしまう場合もあります。
本記事では
● 性能問題を起こさないための、正規表現の書き方の注意点
● 正規表現の書き方によってどれくらい性能が変わってしまうかの比較をご紹介します。
なお、ここから先は、Logstashの設定の仕方をベースにご説明します。
Logstashのgrok filterについて
Logstashのgrok filterは、正規表現でログのフォーマットを指定し、必要な部分を抽出することができるものです。
2021-01-01T12:11:35.123Z INFO process started
”^(?<timestamp>\S+) (?<level>\S+) (?<log_message>.*)$”
※「\S」は、空白文字以外の文字を表します。
これによって、元のメッセージから、以下のfieldを抽出することができます。
{
"timestamp": "2021-01-01T12:11:35.123Z",
"level": "INFO",
"log_message": "process started"
}
正規表現は、非常に複雑な表記になる場合もあり、そういったものを毎回書くと非常に見づらくなります。
例えば、IPv4のアドレスを表す正規表現は以下のようになります。
(?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
Logstashのgrok filterでは、こういった、よく使う正規表現を事前に定義した、grok pattern が利用可能です。
2021-01-01T12:11:35.123Z INFO process started
grok patternを使うと、先ほどの例は以下のような書き方になります。
^%{NOTSPACE:timestamp} %{NOTSPACE:Level} %{GREEDYDATA:log_message}$
{
"timestamp": "2021-01-01T12:11:35.123Z",
"level": "INFO",
"log_message": "process started"
}
grok filterを書く際の注意点
grok filterを書く際は、処理効率の悪い正規表現の書き方にならないように注意する必要があります。
例えば、「GREEDYDATA(.*)はできるだけ使用を避けるべき」ということがあります。
GREEDYDATAをなぜ使ってはいけないか
aaa bbb ccc ddd eee
のような、スペース区切りで5つの要素がある形のデータを扱う際に、
^(?<field1>.*) (?<field2>.*) (?<field3>.*) (?<field4>.*) (?<field5>.*)$
このような書き方をしてはいけません。
これでも正しく5つのfieldが抽出されますが、非常に効率の悪い処理になってしまいます。
「.*」というのは、「任意の文字が0文字以上」という意味ですが、「できるだけ長い文字列にマッチするものを優先する」という判定処理になります。
正規表現による文字列マッチの処理は、上記の書き方の場合、以下のように行われます。
(1)「field1」をできるだけ長く抽出したいので、
"field1": "aaa bbb ccc ddd eee"
としてみる。これだと、field1の後ろにスペースがなくて、マッチしないので、一文字ずつ減らしていく。
field1: “aaa bbb ccc ddd“
(2)「field1」 後ろにスペースがあるので、次に「field2」を抽出する。
field1: “aaa bbb ccc ddd“
field2: “eee“
これだと「field2」後ろにスペースがなくてマッチしないので、一文字ずつ減らしていく。field2を0文字まで減らしてもマッチしないので、field1の取り方が悪かったことになるので、field1を短くする。
"field1": "aaa bbb ccc"
(3) 「field1」後ろにスペースがあるので、次に「field2」を抽出する。
"field1": "aaa bbb ccc"
"field2": "ddd eee"
これだと後ろにスペースがなくてマッチしないので、減らしていく。
"field1": "aaa bbb ccc"
"field2": “ddd“
次に、field3を抽出する。
field3: “eee“
これだと、「field3」後ろにスペースがなくてマッチしないので、field2をさらに減らす。field2を減らしてもマッチしないので、field1をさらに減らす。
….
このように、何度も後戻りする処理(バックトラック)が発生してしまい、特に、field数が増えるにしたがって、チェック処理の回数が指数関数的に増えてしまいます。
上記の説明を図で表したものがこちらになります。
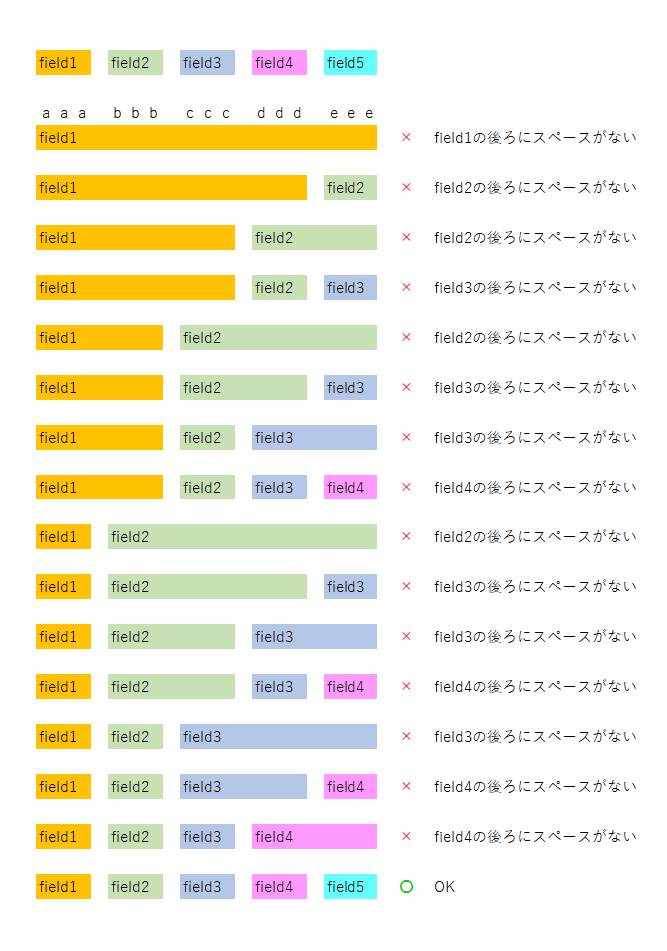
そのため、GREEDYDATAは使ってはいけないのです。
先ほどの抽出条件を、以下のように、GREEEDYDATAではなくDATA(.*?)に変えると、高速化します。
^(?<field1>.*?) (?<field2>.*?) (?<field3>.*?) (?<field4>.*?) (?<field5>.*?)$
「.*?」は、「.*」と違って「できるだけ短い文字列でマッチするものを優先する」となります。
このため、判定処理が以下のようになります。
(1)「field1」を、直後にスペースがあるところまで、できるだけ短く抽出したいので、
field1: aaa
とする。
(2)「field2」を、直後に直後にスペースがあるところまで、できるだけ短く抽出したいので、
field2: bbb
とする。
(3)「field3」を、直後に直後にスペースがあるところまで、できるだけ短く抽出したいので、
field3: ccc
とする。
同様に進んで、field1, field2, field3, field4, field5 が無駄な繰り返し処理をすることなく抽出できます。
DATAの利用もできる限り避ける必要がある
上記の通り、GREEDYDATAではなくDATAを使えば、判定処理が効率化するのですが、DATAを使うと、想定したフォーマットではない文字列(例えば、スペース区切りの要素の数が少ないもの)が来た場合に、性能問題を引き起こす場合があります。
マッチしないことの判定もスムーズに行われるようにするために、DATAではなく、NOTSPACE(\S+)または0文字の場合も許容するのであれば「\S*」にするのが望ましいです。
^(?<field1>\S+) (?<field2>\S+) (?<field3>\S+) (?<field4>\S+) (?<field5>\S+)$
grok patternを使って書くと、以下のようになります。
^%{NOTSPACE:field1} %{NOTSPACE:field2} %{NOTSPACE:field3} %{NOTSPACE:field4} %{NOTSPACE:field5}$
想定したフォーマットではない文字列が来た場合に性能問題が発生するメカニズムについては、別の機会に書きたいと思いますが、ここでは、「マッチして欲しい文字列をできるだけ曖昧さのない書き方で表現するべき」と覚えておいてください。
grok filter以外の選択肢
dissect filterや、区切り文字がはっきりしている場合はcsv filterを使うこともできます。正規表現ほど複雑な指定はできませんが、その代わり、効率の良い処理になります。
パフォーマンスの比較
同じデータをInputとして、各fieldを
・GREEDYDATA ⇒ .*
・DATA ⇒ .*?
・NOTSPACE ⇒ \S+
で抽出した場合を比較しました。
スペース区切りのfield数が5個の場合、10個の場合、20個の場合と、
field数が20個のデータの中に、1%だけfield数が足りない不正なデータが混ざっている場合の、4つのパターンでそれぞれ計測しました。
(計測は、AWS のEC2インスタンス t3.medium で、Logstash 7.10.3 を用いました)

今回の結果から、以下が分かります。
(1) GREEDYDATAを使うと、field数が増えるにしたがって極端に性能が悪くなる。
(2) DATAとNOTSPACEはどちらも高速に処理されるが、DATAだと想定外のメッセージ(field数が足りない)が来た場合に性能が劣化する。
LogstashやFluentdは、ログのフォーマットを正規表現で指定して、必要な値を取り出すことができますが、正規表現の書き方によって処理性能が大きく変わることがあります。マッチする/しないが明確に判定できるように、曖昧さのない書き方にすることが望ましいです。
特に、GREEDYDATA(.*)やDATA(.*?)の使い方には注意しましょう。
Airitechではビッグデータ解析ツール導入・支援のほか、トラブルシュートやシステム性能サービスなど、さまざまなサービスを提供しております。
UiPathユーザー向けElasticsearch・Kibanaのオンライントレーニングも行っています。Elasticsearch・Kibanaに興味のある方は、ぜひご参加ください。
Elasticsearch・Kibanaトレーニング(オンライン)
また、Elasticsearchエンジニアの募集も行っていますので興味のある方はぜひご応募ください。
Airitechの採用情報はこちら
ホームページ
この記事が気に入ったらサポートをしてみませんか?