
複数のデータソースを管理する方法

こんにちは!
Airitechのビッグデータ・AI活用グループのドゥックです。
この記事では、複数のデータソースを管理する方法について書きたいと思います。
1. 複数なデータソースとは?
データソースというのは、データを保存したり取得したりするものです。
例えば:MySQL、Elasticsearch、Redis、APIなど、2つ以上のデータソースを複数なデータソースと言います。
2. 背景
ここでは、3つのデータソースを扱ってみます。
MySQL、Elasticsearch、Redisです。2つの設計方法で、MySQLとElasticsearchの情報を取得して、Redisに書き込んでみましょう。
データ構成は、次のとおりです。
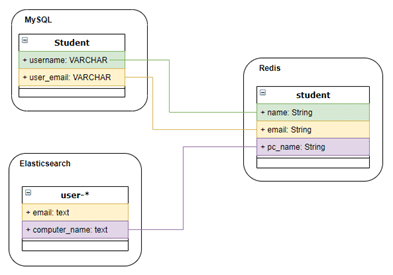
※上記の図では、属性ごとに色分けしています。
※説明コード言語は、Pythonです。
設計1 : データソースごとにクラスを割り当てる
データソースに応じて、専用クラスを作成します。
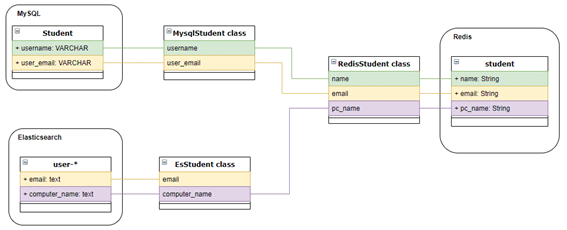
Redisに書き込む流れは、次のとおりです。
# MySQLの情報: mysql_result = {"username": "Duc", "user_email": "trieuduc1996@gmail.com"}
# MysqlStudentオブジェクト化
1. mysql_student = MySqlStudent(**mysql_result)
# mysql_studentのuser_emailを基にElasticsearchで検索します
# Elasticsearchの情報: es_result = {"email": "trieuduc1996@gmail.com", "computer_name": "pc1"}
# EsStudentオブジェクト化
2. es_student = EsStudent(**es_result)
# RedisStudentオブジェクトを作成
3. RedisStudent(name=mysql_student.username,
email=mysql_student.user_email,
pc_name=es_student.computer_name)設計1の問題
1. RedisStudentオブジェクトを作成するとき、属性を一個ずつ割り当てなければならないです。
2. データソース変更や属性の追加があると、影響が大きいです。
※説明コード言語は、Pythonです。
次の設計で、解決してみましょう!
設計2 : コンバータ(Converter)
設計2は、設計1と似ていますが、コンバータで属性が一括変換できます。
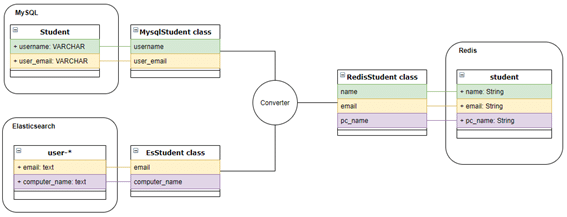
やり方は、後ほど説明します。まず、コンバータを使ったらどうなるかを説明します。
# MySQLの情報: mysql_result = {"username": "Duc", "user_email": "trieuduc1996@gmail.com"}
# MysqlStudentオブジェクト化
1. mysql_student = MySqlStudent(**mysql_result)
# mysql_studentのuser_emailを基にElasticsearchで検索します
# Elasticsearchの情報: es_result = {"email": "trieuduc1996@gmail.com", "computer_name": "pc1"}
# EsStudentオブジェクト化
2. es_student = EsStudent(**es_result)
# RedisStudentオブジェクトを作成
3. converter = Converter()
4. converter.add(mysql_student)
5. converter.add(es_student)
6. redis_student = converter.export(RedisStudent)設計2は、設計1のステップ2まで同じですが、設計1のステップ3における属性を、一個ずつ割り当てる必要がありません。
設計2の解説
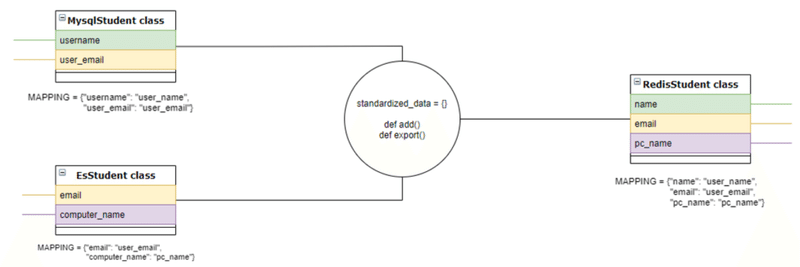
上記のとおり、2つの部分から構成されています。
1. MAPPING クラス属性
データクラスに追加するDictionary(クラス属性)です。役割は、属性名を標準すれば何になるかと定義します。MAPPINGは{クラスの属性名:標準化名}というペアを保存します。
2. Converterクラス
Dictionaryとadd関数とexport関数を含めます。Dictionaryで{標準化名:インプットの値(mysql_student.usernameとか)}というペアを保存します。
Add関数が呼ばれると、インプットのMAPPINGでデータを変換して、Dictionaryに書き込みます。Export関数が呼ばれると、アウトプットのMAPPINGで、Dictionaryのデータを変換してオブジェクト化します。
Converterクラスは次のとおりです。
class Converter:
def __init__(self):
self.standardized_data = {}
def add(self, datasource):
for field_name, field_value in datasource.__dict__.items():
standardized_field_name = datasource.MAPPING.get(field_name)
if standardized_field_name:
self.standardized_data[standardized_field_name] = field_value
def export(self, targetClass):
localized_data = {}
for localized_field_name, standardized_field_name in targetClass.MAPPING.items():
localized_data[localized_field_name] = self.standardized_data.get(standardized_field_name)
return targetClass(**localized_data)設計1の問題が解決できました。データソースごとに事前定義MAPPING を確定すれば、自動的に変換できます。データソースと属性を追加したり外したりしても、影響が小さいと思います。
しかし、この設計を使用するとき弱点も感じていました。
1. 柔軟すぎるので、converterで保存している値は何か曖昧です。
2. 1-n対応が不便です。
3. データソースの順序がなければ、手動で対応しないといけません。
実行できるサンプルも投稿しました。ぜひご覧ください。
最後までお読みいただきありがとうございました。
Airitech株式会社について
システムのトラブルシュートや性能改善/ビッグデータの活用/システム開発支援を主な事業とし、ITシステムのダウンや性能劣化など、難度の高い問題の解決をしています。その実績を活かして、お客様の環境に合わせたシステムの導入と保守サービスの提案を広く行っています。
採用情報はこちら
/assets/images/7140406/original/66b0d4f5-28a5-43df-898a-22aff4125059?1625481943)
/assets/images/6991340/original/3ac8c41b-88a7-4bf0-8a16-e52f1ea2a648?1625458984)
/assets/images/7195466/original/a0b7e8a6-1f89-4af7-bcb3-83dc4adb61e0?1626662853)
この記事が気に入ったらサポートをしてみませんか?