
paperspaceでLora学習する方法

このページではpaperspaceというクラウドサービスを利用してLoraを作る方法を説明します。
参考にさせていただいたサイトはこちらです。
↓
なお、めちゃくちゃ独学で自分でも何やってるのかいまいち分かってないので、あくまで参考程度にしてください・・・
【ノートブックの導入】
まず、RTX5000かA4000のグラボを借りてください。それ以下だとメモリ不足で学習できません。
そうしたら、左のメニューアイコンの一番下にあるオレンジのやつ(ジュピターラボ)をクリックしてください。
するとこんな画面になります。

ここのFiler files by nameの下にこのデータをドラッグ&ドロップします。
入れ方はこのコードをコピペして、メモ帳に貼り付けて保存して、メモ帳の拡張子を.ipynbにするだけです。
無事に入れたらジュピターラボから脱出したいので、ブラウザを閉じてこの画面に戻ります(戻り方を知らないw)
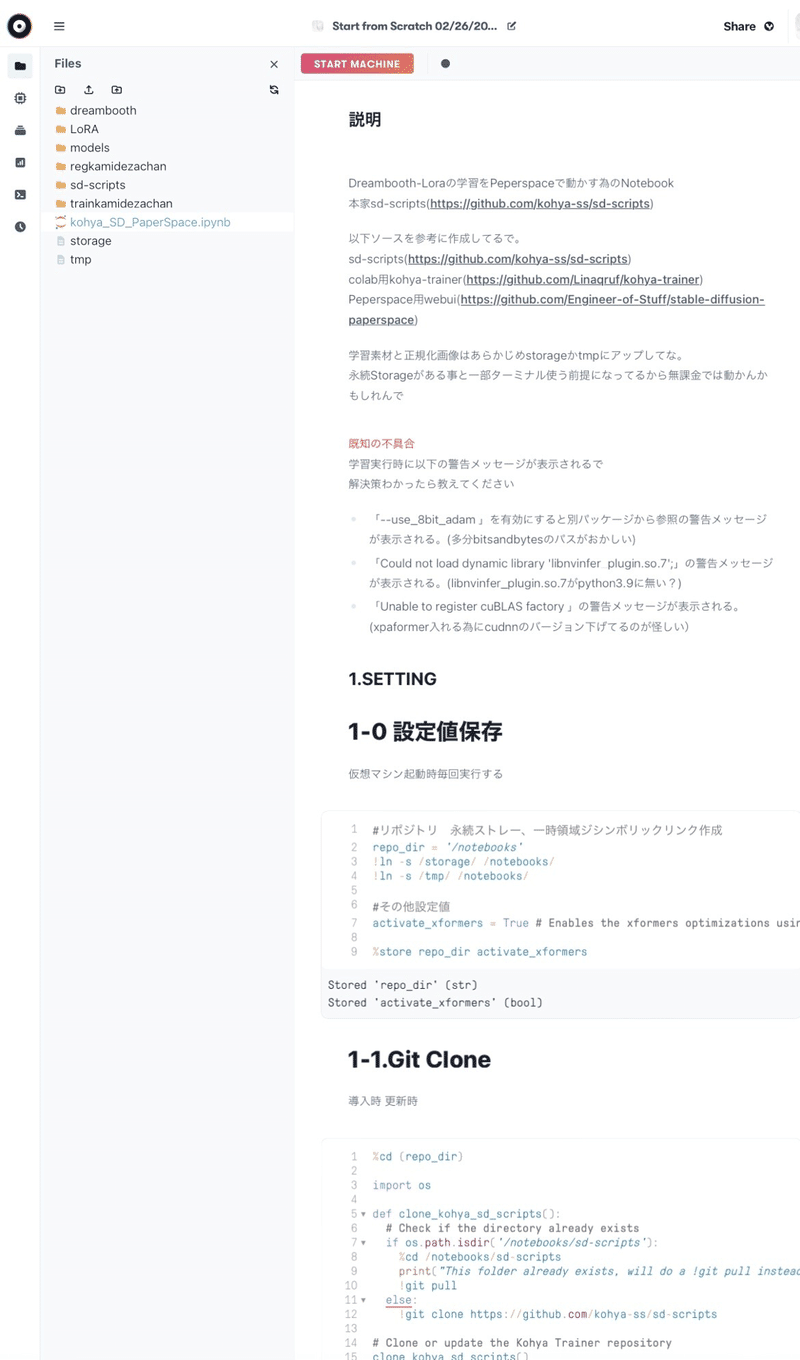
さて、次にAIイラストで使っているモデルをアップロードします。
私は「models」というフォルダを作ってその中に入れました(上の画像にmodelsってありますよね?それです)
ちなみに、モデルをアップロードする時は、このコードを打ち込んで実行すると速いです。
直接アップロードすると30分かかりますが、google driveにあるモデルをダウンロードすると30秒で終わります。
↓
①
#googleドライブからダウンロードするのに必要なものをインストールする
!pip install gdown
!pip install --upgrade gdown
②
#googleドライブからファイルをダウンロードする "[ここにファイルIDを入力]"をファイルIDに置き換えてから実行
#!gdown "https://drive.google.com/uc?export=download&id=[ここにファイルIDを入力]"
%cd /notebooks/models
!gdown "https://drive.google.com/uc?export=download&id=○○○"
○○○はgoogle driveで共有(制限付き→リンクを知っている全員に変える)する時のリンクの、「file/d/○○○/view?」の部分ですよ!
【データセットについて】
そうしたら、いよいよデータセットを用意します。画像は20〜30枚くらいが良いです。
もっと多い方がたくさん学習できるんじゃないの?と思うかもしれませんが、学習回数を多くすれば良いだけなので、必要ないです。
あまり多いと過学習といって、まともな絵が生成されなくなります。
今回は私のオリジナルキャラクターである神デザちゃんの画像を30枚用意しました。
↓
サイズと解像度はバラバラでOKです。
一応全部PNGに揃えました(JPEGで良いかどうかは知らない)
あとはpaperspaceにフォルダを作るのですが、これがめちゃくちゃ重要です。
基本的にこの画像の通りに作ればOKです。
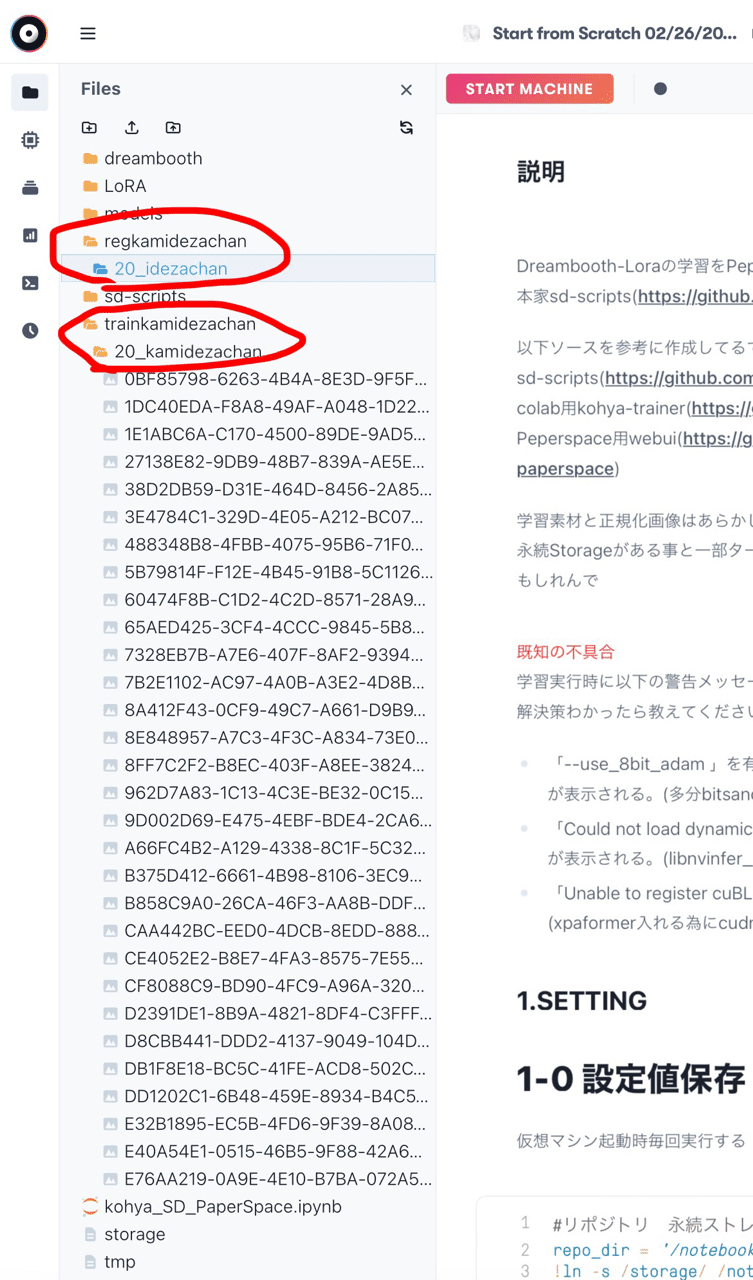
「trainkamidezachan」というファイルの中に「20_kamidezachan」があり、その中に画像が入っています。
「regkamidezachan」というファイルの中に「20_idezachan」があります。
この構造は絶対に変えないでください。
【identifierとclassについて】
ここから話が少し難しくなりますが、重要な部分なのでしっかり読んで理解してください。
Loraの学習には「identifier」と「class」を決める必要があります。
神デザちゃんのidentifierは「kam」で、classは「idezachan」です。
なぜ変なところで区切られるのかというと、kam / ide / zach / an でトークンが区切られてAIが認識するので、最初の1トークン目である「kam」がidentifier、残り「idezachan」が classになるからです。
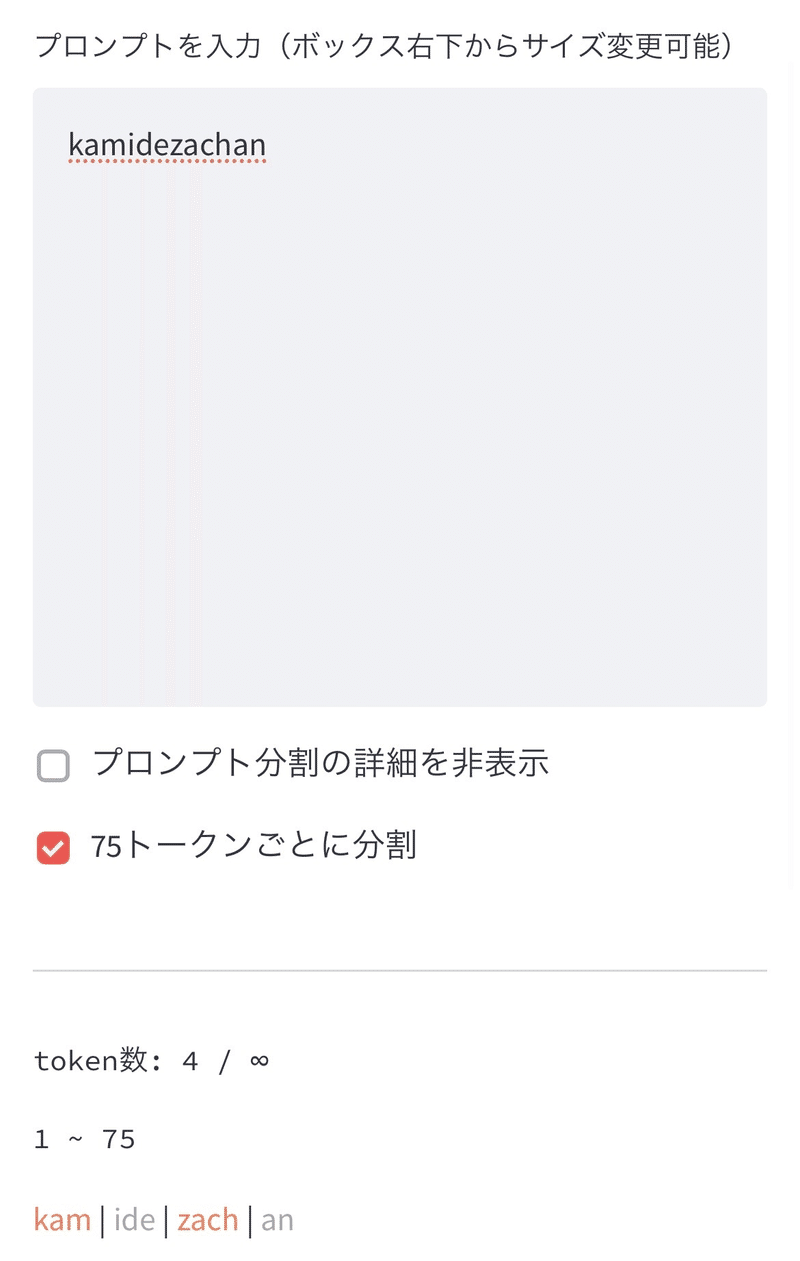
↑chiliさんのトークナイザーで確認しよう!
ファイル名の話に戻りますが、trainkamidezachanとregkamidezachanは何でも良いです。
trainが学習、regが正則化なので適当に付けました。
大事なのはその中に作るファイル名で、trainkamidezachanの中のファイルには「繰り返し回数_(identifier)(class)」という法則で名前を付けます。
つまり、今回なら「20_kamidezachan」になります。
regkamidezachanの中のファイルには「繰り返し回数_class」という法則で名前を付けます。
つまり、今回なら「20_idezachan」になります。
繰り返し回数とは学習する回数のことで、私は20にしました。
Loraを作って使ってみたところ、これがちょうど良いと思いました。
それと、「dreambooth」という名前のフォルダも作ってください。この中に学習結果が保存されます。
ちなみに、20_idezachanのファイルの中には何の画像も入ってないです。
ここに画像を入れると正則化できるんですけど、今回は必要ないです。
正則化とは、classの概念を学習させる作業です。つまり、「idezachan」とはなんなのかを教えることができます。
真っ黒なPNGをデータセットと同じ数用意すると学習精度が上がる・・・気がするんですけど、別になくてもちゃんと学習できるのでどっちでもいいです。
【学習の手順】
※初回の手順を説明します。2回目以降は最後に書いてあります。
さて、ファイルを作って20_kamidezachanの中にデータセットをアップロードしたら、ついに学習スタートです!
Terminalを開いてこのコードを順番に打ち込んでいきます。
↓
①mkdir LoRA
②cd LoRA
③apt update -y
④apt upgrade -y
⑤git clone https://github.com/kohya-ss/sd-scripts.git
⑥git clone https://github.com/derrian-distro/LoRA_Easy_Training_Scripts.git
⑦cd sd-scripts
⑧apt -y install python3.9
⑨pip install -U -r requirements.txt
⑩pip install -U --pre triton
↑
このコードを上から順番に実行していきます。
もちろん①〜⑩は入れなくていいですよ。便宜上見えやすいように付番してるだけですから。
つまり、「mkdir LoRA」をコピペして実行して、処理が終わったら「cd LoRA」をコピペ実行して・・・みたいな感じですね。
全て終わったら左のメニューアイコンからファイルを開いて、先程ドラッグ&ドロップしたDBLora/kohya_SD_PaperSpace.ipynbをクリックします。
実行するのは以下の2つです。
1-0 設定値保存
1-1.Git Clone
ちなみに、1-2はxformersをインストールするコードなんですけど、今は仕様が変わってこのコードを実行してもxfromersはインストールされないです。
そのため、以下のコードを自分で打ち込んで実行してください。
↓
!pip uninstall -y torch torchvision torchaudio
!pip install xformers==0.0.16rc425
!python -c "import launch; launch.prepare_environment()"
!pip uninstall -y lxml
!pip install lxml accelerate
!pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
終わったらまたTerminalsを開いて、以下のコードを順に実行します。
↓
①cd ..
②accelerate config
↑
accurate configを実行するとなんか質問されます。
基本的に全部そのままEnter押せばいいんですけど、6個目の質問で3つ選択肢出てきて、真ん中に「fp16」ってやつがあるので、矢印キーで選択します。
終わったら、このコードを順に実行します。
↓
①cp
②cp LoRA_Easy_Training_Scripts/ArgsList.py sd-scripts
③cd sd-scripts
最後にこのコードを実行して終わりです。これ全部で1文です。
↓
accelerate launch --num_cpu_threads_per_process 12 train_network.py --pretrained_model_name_or_path=/notebooks/models/モデル名 --train_data_dir=/notebooks/trainkamidezachan --reg_data_dir=/notebooks/regkamidezachan --output_dir=/notebooks/dreambooth --resolution=320,960 --train_batch_size=1 --learning_rate=8e-5 --max_train_epochs=エポック数 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --network_module=networks.lora --keep_tokens=7 --enable_bucket
太字のところは自分で変えてください。
エポック数は最初は1で良いです。
A4000なら6分、RTX5000なら9分で学習が終わります。
無事に学習できたらエポック数を20にしてみてください。
1〜20までの学習結果が保存されます。
大事なことなので2回言いますけど、「dreambooth」という名前のフォルダも作ってくださいね。この中に学習結果が保存されますからね。
上のコードにも「--output_dir=/notebooks/dreambooth」ってありますよね?これと対応してます。
はい、説明は以上です。
Loraの使い方は、作ったsafetensorsを「stebale-diffusion-webui → models → Lora」に入れます。
あとは、プロンプトの冒頭に
<lora:○○○(付けたファイル名):1>kamidezachan,
と付けるだけです(1の部分は強調で、数字を変えられます)
どのepochを使えばいいの?って話なんですけど、正直よく分からないです。
epoch3の強調0.8がちょうど良いような気もしますし、epoch20の強調0.5でも普通に出ます。
皆さんも独自のLoraを作ってみましょう!世界が変わりますよ!

【2回目以降の手順】
Terminalsを開いて以下のコードを順に実行してください。
↓
①cd LoRA
②apt update -y
③apt upgrade -y
④cd sd-scripts
⑤pip install -U -r requirements.txt
⑥pip install -U --pre triton
DBLora/kohya_SD_PaperSpace.ipynbを開いて、以下の3つを実行してください。
↓
1-0 設定値保存
1-1.Git Clone
!pip uninstall -y torch torchvision torchaudio
!pip install xformers==0.0.16rc425
!python -c "import launch; launch.prepare_environment()"
!pip uninstall -y lxml
!pip install lxml accelerate
!pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
再びTerminalsを開いて以下のコードを順に実行してください。
↓
①cd ..
②accelerate config
③cd sd-scripts
④accelerate launch --num_cpu_threads_per_process 12 train_network.py --pretrained_model_name_or_path=/notebooks/models/モデル名 --train_data_dir=/notebooks/trainkamidezachan --reg_data_dir=/notebooks/regkamidezachan --output_dir=/notebooks/dreambooth --resolution=320,960 --train_batch_size=1 --learning_rate=8e-5 --max_train_epochs=エポック数 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --network_module=networks.lora --keep_tokens=7 --enable_bucket
エラーが出たらChatGPTに聞けばOK!(たぶん)
この記事が気に入ったらサポートをしてみませんか?