
【初心者でも安心!】Stable DiffusionでAI美女画像を生成する方法【入門編】

このNoteについて
このNoteではStable Diffusion web UIを使用した画像生成の初歩について説明しています。
続きのNote「応用編」では複数のプロンプトを連続して実行したり、大量の単語の組み合わせで画像を生成する方法や雰囲気の似た画像を生成する方法などを紹介します
Stable Dffusion web UIの公式リポジトリ
Stable Diffusion について
使用する環境について説明・注意
Stable DiffusionはWindows, Macのどちらでも実行可能だが、VRAM8GB以上のNVIDIA製グラフィックボードが搭載されたメモリ16GB以上のWindowsでの実行が推奨されている。
推奨される理由は以下の通り。
VRAM8GB以上のNVIDIA製GPUが推奨される理由
Stable DiffusionはNVIDIA製GPUを使用して実行する想定で開発されていてAMD製のGPUを使用している環境では導入方法が異なる。
VRAMの8GB以上推奨に関しては、不足していると大きな解像度の画像を生成できなかったりそもそも生成が不安定でエラーになったりする事があるため。
Windowsが推奨される理由
M1以上のMacではCLIP interrogatorと学習がものすごく遅い。
さらに追加でアップルシリコンが搭載されたMacをおすすめしない理由
GPUが搭載されていないWindowsマシンやMacでもGPUを使えるようにするeGPUというハードウェアがあるが、M1以降のAppleシリコンを搭載したMac用のNVIDIAドライバーはまだリリースされていない。
そのため推奨GPUであるNVIDIA製のGPUはM1以降を搭載したMacでは使用出来ない。
とはいってもGPUコア自体は搭載されているので画像の生成は可能。GPUを搭載してるWindowsマシンと比べたら拡張性と画像生成速度で勝てないだけで試しに触ってみる分にはAppleシリコンのMacでも全く問題は無い(個人的には!)
※CLIP interrogatorは日本語化したwebUI上では「CLIPによる解析」と表示される、これについては応用編で
つまりどういう事?自分の環境はどうなの?もうわかんない
GPU搭載Windowsマシン
強い、RTX20番台以上であればなお強い。
SSDとHDDの合計容量があればあるほど更に強い。
家とかで無限に画像生成ぶん回すのに最適。冬は暖房いらず。
GPU搭載してないWindowsマシン & Intel CPU Mac
まだ諦めるには早い、eGPUとGPUを買えば強くなれる。
PCケースが大きくて拡張性能があるならeGPUを買わずGPUだけで強くなれる。スリムPCとかならeGPUも買わないといけない。
メモリが16GB以上ある事を祈る。
Appleシリコン Mac
生成速度で勝てないなら持ち運べる手軽さで勝つしかない、ポータブル性能において最強。Mac miniとかはちょっとわからないです…
eGPUを繋いでもNVIDIA製のGPUが使えないからドライバーリリース待ちかAMDのGPUで頑張るかのどちらか。AMD製GPUは多分情報も少なくてきっと茨の道、多分。
画像生成に必要なモデルを用意する
モデルについて
Stable Diffusionで画像生成するためにはモデルが必要。
生成したい画像の系統によって使用するモデルも変わってくる。
実写系で有名なモデル
イラスト系で有名なモデル
ダウンロードしたモデルファイルは、この後の章でweb UIをインストールしてから指定の場所に配置。
webUI起動までしてあとは生成ボタン押すだけなのにモデルが無いってなると悲しいので今のうちにダウンロードしておきます。
モデルファイルはStable Diffusion web UI関連のファイルの中でもそこそこ大きいファイルサイズ(1ファイル数GB)なのでストレージがカツカツの人は生成する画像の分も合わせて余裕を持って容量確保しておいたほうが良い。
高解像度化とかしてると時間とまあまあな容量持っていかれる。
Stable Diffusion web UIのインストール
Stable DiffusionのGitHubリポジトリ
Windows
公式手順
https://github.com/AUTOMATIC1111/stable-diffusion-webui#automatic-installation-on-windows
Pythonの3.10.6をインストール
インストール時に「"Add Python to PATH"(パスに追加)」をチェック
gitをインストール
git cloneを使ってweb UIリポジトリをローカル環境にダウンロード もしくは githubページ上部にある緑色の「Code」ボタンから「Download Zip」
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
webui-user.bat を実行する
Appleシリコン Mac
公式手順
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Installation-on-Apple-Silicon
Homebrewを使用するのでインストールされていない場合は先にbrewをインストール
「terminal」を起動、brewを使用して必要な物をインストール
brew install cmake protobuf rust python@3.10 git wget
web UIのリポジトリをクローン
web UIフォルダに移動してwebui.shを実行
cd stable-diffusion-webui
./webui.sh
モデルファイルの配置
web UIをインストールする前にダウンロードしておいたモデルファイルを下記フォルダに配置。
/stable-diffusion-webui/models/Stable-Diffusion
※webuiを起動してからモデルファイルを追加した場合は、画面左上のモデル選択欄にあるリフレッシュボタンを押してモデルファイル一覧を更新する。
Stable Diffusion web UIの画面の説明
もう画像生成したくてたまらない人もいるとは思うけど、一応画面内の各項目がどういうものかざっくりと説明。
Prompt(プロンプト)
生成したいもの、画像内に含みたい要素
Negative Prompt(ネガティブプロンプト)
生成したくないもの、画像内に含みたくない要素
Step(サンプリングステップ数)
SDではノイズ画像を徐々に綺麗に(デノイズ)して画像生成を行う
そのデノイズを何回行うか
少なくても15回くらい、30回くらいあれば十分。
それでも画像の一部が不鮮明になる時はステップ数を増やしたりプロンプトを見直す。
Sampling method(サンプリング方法)
サンプリング方法によって生成される画像が異なる。
ものによってはほとんど変わらなかったり、大幅に違う結果になるものもある。
相性問題なのか時々とんでもないノイズ画像が吐き出されてびっくりすることがあるのでその時はサンプリング方法を変更する。
幅、高さ
デフォルトは512x512、モデルの学習にこれくらいの解像度の画像が使用されているため。
あまり大きい解像度にするとメモリが不足するので値はパソコンのスペックと相談して設定する。RTX3080だと512x1200くらいまではいける。
大きい解像度で生成したい時は、その解像度の縦横半分(面積的に1/4サイズ)で出力して好みの画像が生成されたら同じ設定で画像を出力してHires. fixを使用して高解像度の画像を生成する。
高解像度化は結構時間がかかるので大量に画像生産するときに有効化すると純粋に時間がかかるようになってしまう。
バッチカウント
画像生成を実行する回数。
100に設定するとそのプロンプトで100枚画像を生成するまで画像を生成し続ける。
バッチサイズ
一度に生成する画像の枚数。
枚数が大きくなるとメモリが足りなくなるので基本的に1枚で実行する。
CFGスケール(Classifier Free Guidance)
どれくらいプロンプトに忠実に画像を生成するか。
デフォルトは7、値が小さいとプロンプトとは関係ない画像が生成されて、大きいと要素が強いおかしい画像が生成される。
シード値
-1でランダム
画面の右側にすでに生成された画像がある時、リサイクルマークを押すとその画像で使用されたシード値が入力される。
プロンプトもシード値も変更せず画像生成すると同じ画像が生成される。
同じシード値のままプロンプトを変更して画像生成するとプロンプトの影響を確認できる。
画像の生成
まずは画像を生成してみる
やっと画像生成だ!
ここまできたら「とりあえずなにか生成したい!」っていう状態になってると思うので、最低限の設定だけして画像を生成してみる。
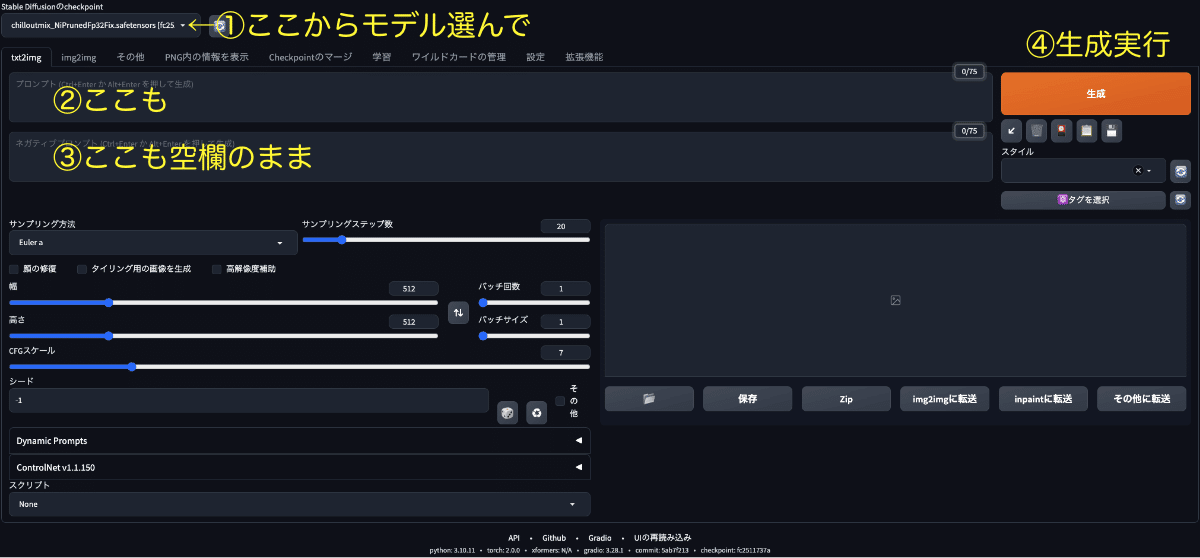
モデル選択欄からモデル選択
選択肢がなければリフレッシュボタンを押す
それでもモデルが出てこなければ/stable-diffusion-webui/models/Stable-Diffusionにモデルを配置する
モデルをDLしてない人は「画像生成に必要なモデルを用意する」まで戻る
「Prompt」欄は空欄
実はなにも入力しなくても生成可能、"概念"みたいな物が生成されて不思議な気分になる
「Generate」を押して生成開始
画像生成にかかる時間はスペックや生成設定によって異なる
[Shift + Enter]か[Command(Ctrl) + Enter]でもGenerate可能
プロンプト編集したらマウスに持ち変える事無く[Shift + Enter]で連続生成出来るのが便利
生成された画像はoutputsフォルダに保存される
ローカルストレージがいっぱいだからってAIで生成したセンシティブな画像をGoogleドライブなどに保存するとアカウントを停止される事があるみたいなので注意が必要。
同様の理由でGoogle Colabを使用してwebUIを動作させるのはおすすめしない、なのでこのNoteではColabでのweb UIの使用方法は紹介しない余談:webUI拡張機能の「sdweb-eagle-pnginfo」を使用して外部ツール「Eagle」に画像を保存すると生成画像が2箇所に保存されるので、ストレージに不安がある人はHDDなどを拡張しておいたほうが良い
プロンプトを入力して画像生成してみる
「Prompt」欄に以下のプロンプトを入力して画像生成してみる
[dog, park]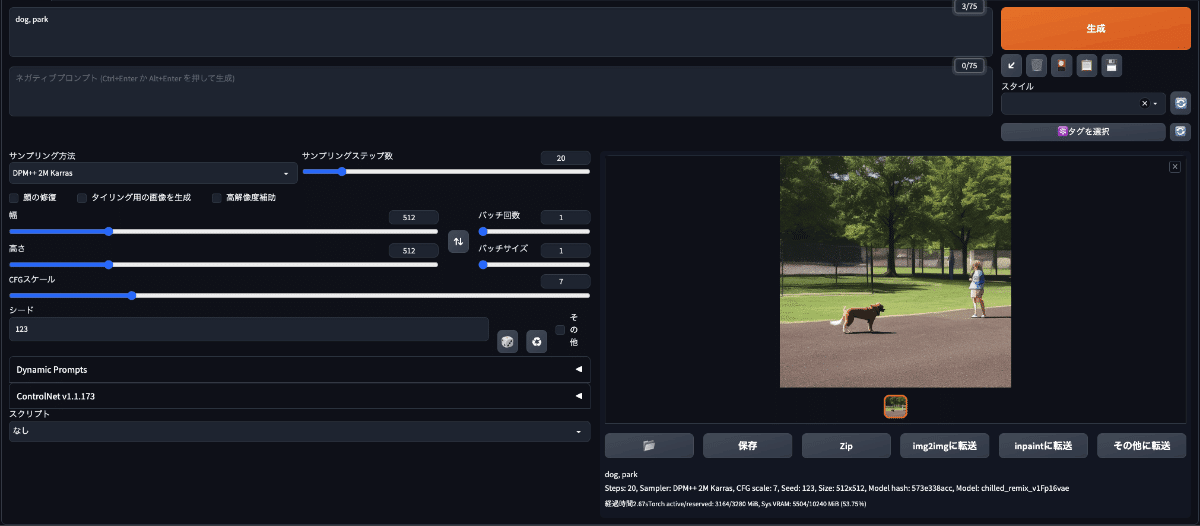

若干イラストっぽい不思議な雰囲気の画像が生成された
実はStable Diffusionで画像を生成するときに「プロンプトのみ」で実行するより、「プロンプト+ネガティブプロンプト」で生成するほうが品質の高い画像を作れる
ネガティブプロンプトって何?
プロンプトが「画像に含みたい要素」で、
ネガティブプロンプトは「画像に含みたくない要素」
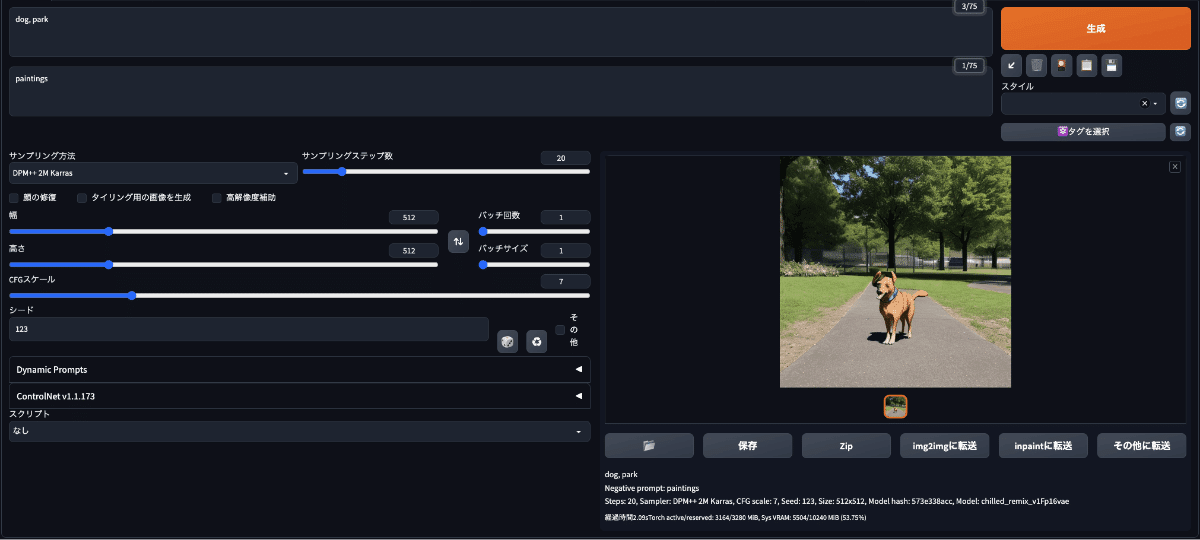
じゃあ今度はネガティブプロンプトも入力して画像生成してみる
生成画像のクオリティアップのために、ネガティブプロンプト欄に「paintings」を入力してGenerate(Shift + Enter or Ctrl + Enter)

今度はプロンプトに「best quality」を追加、ネガティブプロンプトは「worst quality」を追加して重みを2に設定
// Prompt
best quality, dog, park
// Negative Prompt
(worst quality:2), paintings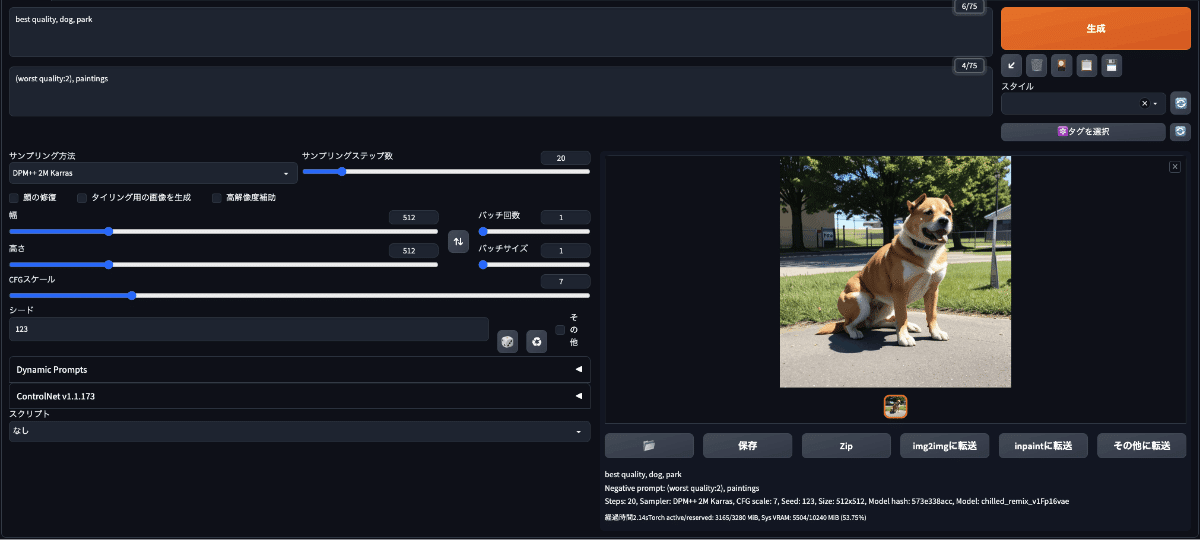

だいぶマシな犬の画像になってきた
最後に高画質化のおまじないでよく使われている単語をこれでもかと追加して画像生成
// プロンプト
beautiful, 8K, RAW photo, masterpiece,
best quality, photo realism, photo realistic, sharp focus,
dog, park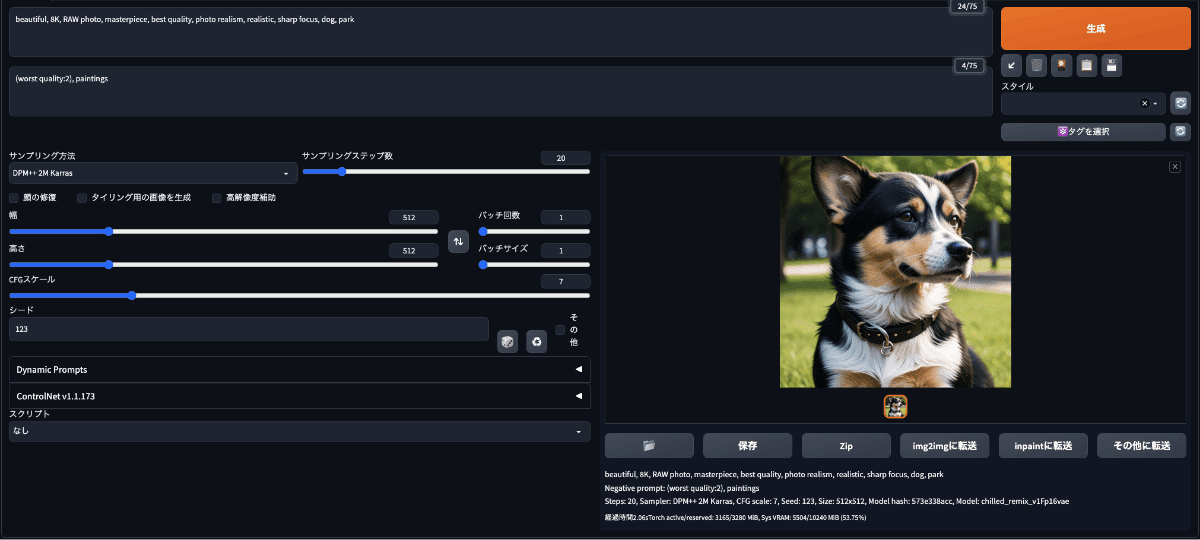

こんな感じで高画質化の単語はかなり効くことがわかった。
想定していない要素を除外するネガティブプロンプト例
// リアル系を生成したい時は二次元要素を除外する
illustration, illust, painting
// イラスト系の時はリアル系要素を除外する
photo, photoreal, photo-realisticプロンプト欄に入力すると画質が向上するワードの例
beautiful, 8K, RAW photo, masterpiece, best quality,
photo realism, realistic, sharp focusなどなど
その他にもカメラ名を含めたり、それぞれの単語の重みを変更することで生成画像を編集できる
プロンプトの仕様について
プロンプトは単語や区切り文字毎に1トークンという単位でカウントされる
画像生成時に一度に渡せるトークンの上限は75個まで
「Prompt」欄の右上に現在のトークン数が表示される
トークン数の枠が赤色になっているとカッコの数などでエラーになっている
75トークンのうち最初のトークンのほうが影響度が高い
76個以上のトークンがある時は75個毎に分割されて処理される
75個目のトークンより76個目のトークンのほうが影響度が高い
「BREAK」を使用することで任意の場所でプロンプトを分割できる
カッコで囲んだ単語は数字で重要度(重み)を編集できる
プロンプトだけで思ったような画像が生成出来ない時は
画質が向上するプロンプトを使用する
不要な要素を除外するネガティブプロンプトを指定する
Seed値を固定して画像生成すると、プロンプトが画像生成にどのような影響を与えているかが確認できる
人を生成したい時は以下のようなプロンプトを使用する
// Prompt
best quality, ultra high res, (photorealistic:1.4),
1girl, looking at viewer, // Negative Prompt
paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2),
lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes,
skin blemishes, age spot, glans, bad legs, error legs, bad feet,
malformed limbs, extra limbs
PNG infoで表示される情報はこれ
best quality, ultra high res, (photorealistic:1.4),
1girl, looking at viewer,
Negative prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2),
lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes,
skin blemishes, age spot, glans, bad legs, error legs, bad feet,
malformed limbs, extra limbs
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 123, Size: 512x512, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix最初はどんなプロンプトにすればいいのか右も左もわからないと思うので、初めのうちはCivitaiなどにアップロードされている画像の生成情報を参考にして少しずつ試すのが良い。
Seed値を固定すればプロンプトの効果を確認できるのでぜひ。
web UIを触ってみて
自分も最初のうちはメインの要素は固定して、画質に関する単語を一つずつ追加したり、一気に追加したり、並び順を入れ替えてみたりして自分の好みの画像が生成されるようになるまで試行錯誤してた。
全然効かない単語があったり逆にものすごく効果のある単語を見つけたりすると楽しいので、そういうのが楽しめる人にとっては時間が溶ける楽しいおもちゃだと思う。
続き:応用編について
このNoteをここまで読んで画像生成出来るようになった人の中にはこんなことを思ってる人もいるかもしれない。
好きな画像が生成出来たけどその時のプロンプトが思い出せない。
プロンプトの一部だけを変更して画像を生成しまくりたい、プロンプトを修正するたびに一枚ずつ画像を生成して確認するのはめんどくさいから効率化したい。予め指定した単語を順番に使って生成してくれたらいいのに
複数の単語同士の組み合わせを複数試してみたい、自分で組み合わせを考えるとどうしても偏ってしまうのでランダムに組み合わせたい。
ある写真と似たような画像を生成したいけどどういうプロンプトで生成すればいいかわからない。
上記の内容については続きのNote「【応用編】AI美女画像生成ツール、Stable Diffusionの活用術:プロンプト探索の効率化と画像の制御【美女プロンプトおまけ有り】」で、解説しているので気になる方はぜひそちらも見てみてください。
この記事が気に入ったらサポートをしてみませんか?