
画像を高機能に読みとろう。MiniGPT-VをAPI化しプログラムから使うー(1)

注)(2)の開発中にエリア指定マスクの処理に間違いがあって、上手く指定できない問題があったため、こちらのコードにも反映させています。
MiniGPT-v2 (V) はMiniGPT-4を更に高性能にしたマルチモーダルLLMです。以下の記事でローカルでDEMOを動かし確認をしました。今回から2回に分けてプログラムから使えるようにAPI化した、記事を書きます。2回に分けた理由は、個人で専有して動かす場合とサーバ化して複数クライアントからアクセスできる2種類のAPIを実装したからです。API化に当たってはいつもどおりFastAPIを利用しています。直接プログラムから利用する場合は、FastAPIを起動せず、ルーティングで記述している関数を呼ぶことで利用できますが、引数の形合わせなどに注意が必要です。
次回は実用的でプログラムの見通しが良いバージョンを公開予定です。
環境
以下の記事を参考にしてください
demo_v2.pyはgradioと連携してマルチモーダル特有の多様な入力と、入力画像に対するアクションとしてタスクの概念が導入されています。タスクは以下の5種類が準備されており、何を聞きたいかで使わけることが出来ます。
[grounding] 全体的なイメージや物体を検出
[refer] 画像を参照してプロンプトに沿う文章を作成
[detection] 指定した物体の検出
[identify] 指定した物体の説明
[vqa] 画像や指定部分など、様々な質問と回答をチャット形式で行う
指定は[grounding] で検出したラベルや、[detection]で検出したエリア、あるいは位置を指定することもできます。demo_v2.pyだとアップロードした画像にペイントで枠を書くことで対応しています。もちろん文字だけでも大丈夫です。w
demo_v2.pyを起動した画面
下に簡単に機能を確認できるサンプルが準備されています。
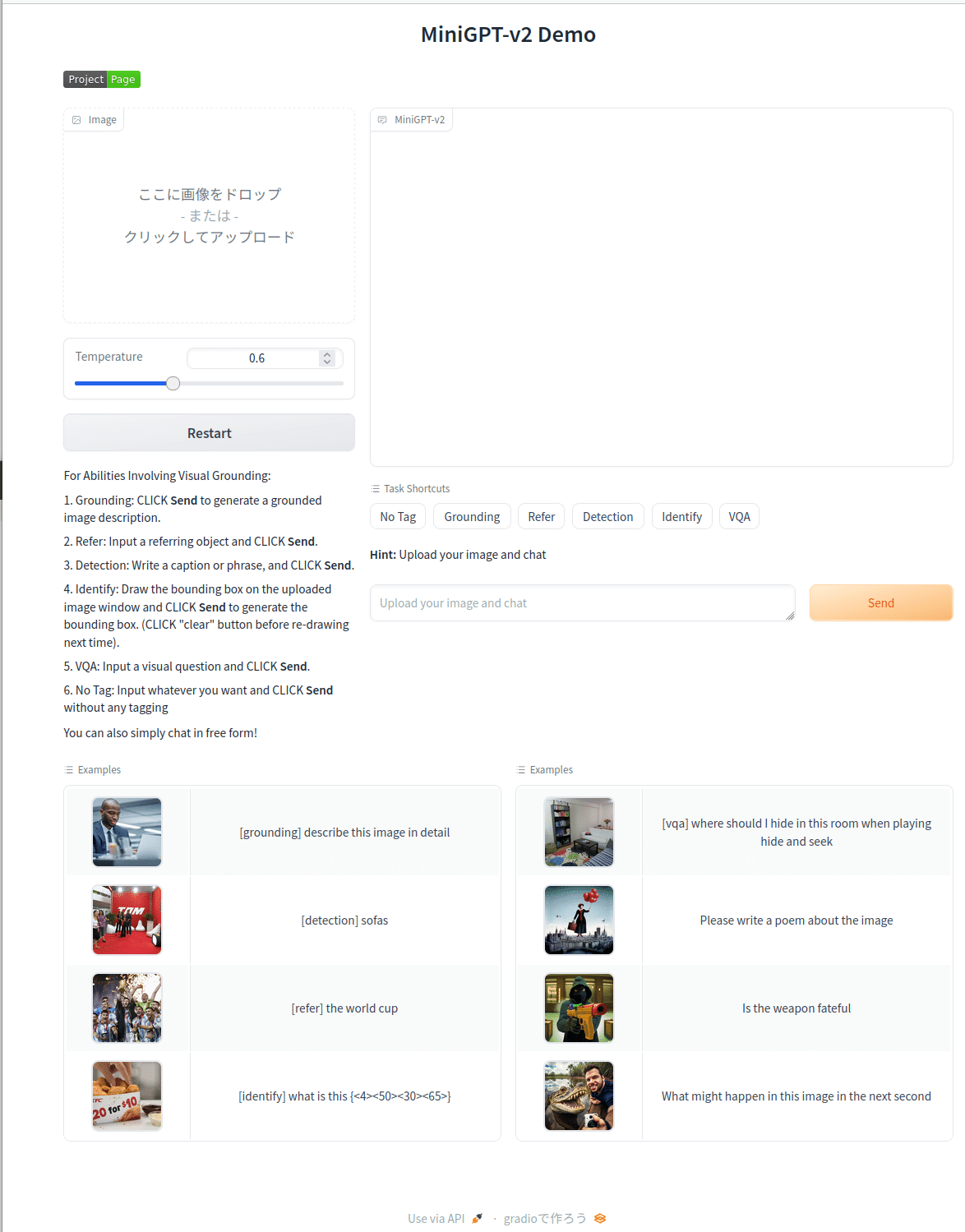
左上のサンプルをクリックして実行した結果
プロンプトは自動で入ります。そのご[send]ボタンをクリックするかテキストBOXでEnterを入力します。どちらも内部の動作は同じです。
[grounding] 全体的なイメージや物体を検出
いくつかの物体が検出され、色分けしたバウンディングボックスとラベル、及び色付きで説明文が出力されます。実はこの色付き出力を求めるためのコードが半分以上を占めています。
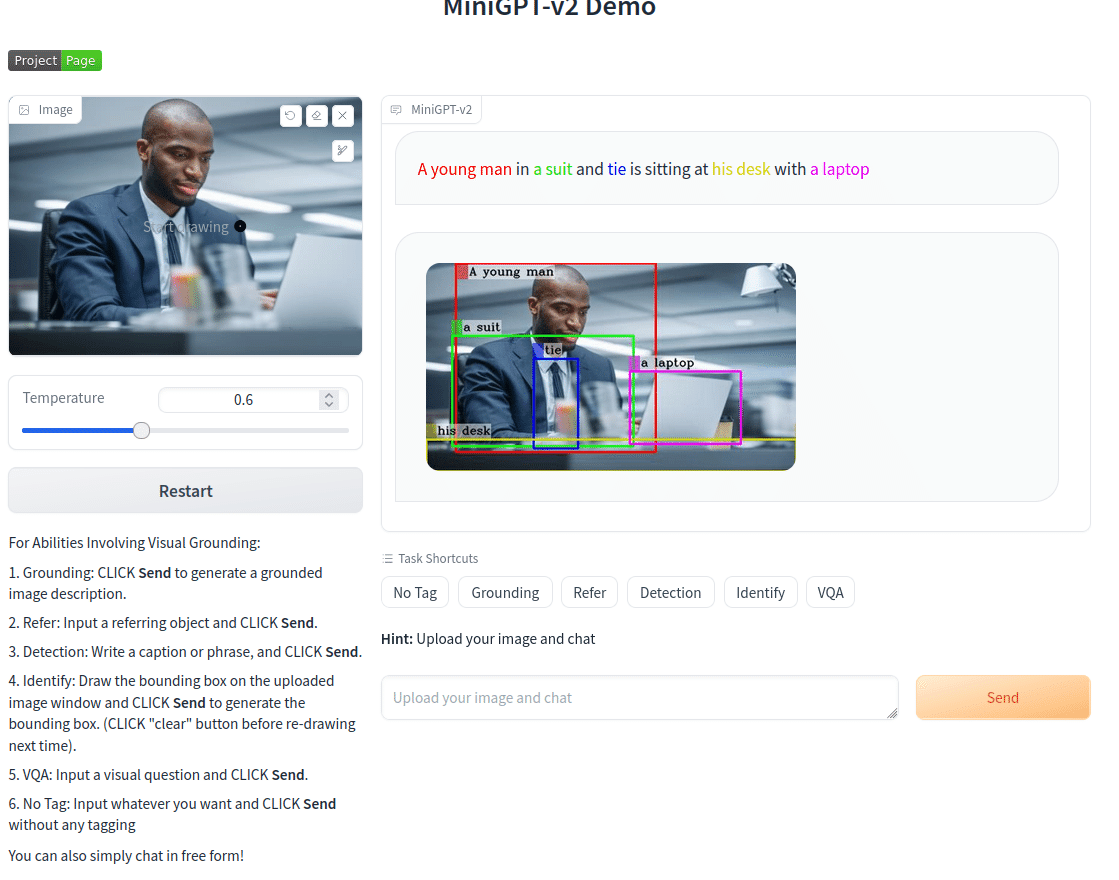
[identify] 範囲をしてした認識の例です。
画像をアップロードし、右上にあるペンで認識させたい部分を囲みます。identifyタスクボタンをクリックすると自動的に
[identify] what is this
と入ります。以下の例では風船を囲み、[send]をクリックして実行した結果です。選択エリアが画像上で赤いバウンディングボックスが作成され、結果はその下に
balloons
と表示されています。わざわざ複数形になってますね。
他にもプロンプトを変更すると色々なタスクを実行できます。
プログラムから使う
DEMOが素晴らしいのでプログラムから呼び出して使いたいところですが、このDEMOではAPIは無いようでした。demo_v2.pyを詳細に解析して、利用しているコード本体を呼び出せば確実でしょうが、多彩入力に対応しているマルチモーダル故に、呼び出す前に色々な処理が必要です。ということで利用できる部分はそのまま利用し、FastAPIを用いてAPI化することにしました。解析の結果、大まかな処理は以下のようになっています。
REST→アップロード→ASK→stream_answer→Visiaraization
ここでstream_answerが推論になります。文字出力をstreamingで得るためにこのような名称になっています。代わりにanswerという関数も準備されていますが、エラーになります。適切に出力を処理すれば使えるはずですが、demo_v2.pyではstreamingが前提になっているのでそのままでは動きません。
gradioが呼んでいる関数は以下のとおりです。
gradio_reset(chat_state, img_list)
image_upload_trigger(upload_flag, replace_flag, img_list)
example_trigger(text_input, image, upload_flag, replace_flag, img_list)
gradio_ask(user_message, chatbot, chat_state, 以下省略
gradio_answer(chatbot, chat_state, img_list, temperature)
gradio_stream_answer(chatbot, chat_state, img_list, temperature)
gradio_visualize(chatbot, gr_img)
gradio_taskselect(idx)
これらをAPIに変えます。
ここで、example_triggerはサンプルの自動ロードなので必要ななく、gradio_taskselectもタスク選択ボタンによる自動入力なので不要です。さらにgradio_answerもエラーになるので今回は扱いません。以下の5があれば全ての機能を使えます。
gradio_reset(chat_state, img_list)
image_upload_trigger(upload_flag, replace_flag, img_list)
gradio_ask(user_message, chatbot, chat_state, 以下省略
gradio_stream_answer(chatbot, chat_state, img_list, temperature)
gradio_visualize(chatbot, gr_img)
reset
変数の初期化です。
# >>>>>>>>>>>>>>> リセット <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
@app.post("/reset/")
def reset( ):
print(">>>>> reset(")
global chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag, out_image
#chat_state .messages = []
chatbot=[]
chat_state=None
gr_img=[]
img_list=[]
upload_flag=0
replace_flag=0
out_image=None
return {'message': "complete"}upload
画像をアップロードします。
# >>>>>>>>>>>>>>> LLMへ イメージのアップロード <<<<<<<<<<<<<<<<<<<<<<<<<<
@app.post("/uploadfile/") #def uploadfile(file: UploadFile ):
def upload_file(file: UploadFile = File(...), mask:UploadFile=File(...)):
global chatbot, chat_state, gr_img, img_list,upload_flag, replace_flag
print(">>>>> uploadfile")
if file:
image_data = file.file.read()
pil_img = Image.open(BytesIO(image_data)) # バイナリデータをPIL形式に変換
mask_img = mask.file.read()
pil_mask= Image.open(BytesIO(mask_img)) # バイナリデータをPIL形式に変換
else:
return {"message":"Error"}#"Error"
#元画像と同じサイズのマスクを作成
#w , h = pil_img.size
#mask = Image.new('RGB', [w,h], (0,0,0))
gr_img = {"image" :pil_img ,"mask":pil_mask}
upload_flag = 1 # set the upload flag to true when receive a new image.
if img_list: # if there is an old image (and old conversation), set the replace flag to true to reset the conv later.
replace_flag = 1
return {"message": "Uploadded","chatbot": chatbot}Ask
プロンプトです。ここで
タスク+命令+指定エリア
の形式で呼び出します。指定エリアはタスクにより必要で合ったり無くても良かったりします。このあたりがややこしい所です。
save_tmp_img(visual_img)という関数はgradioで必要なために準備しています。
# >>>>>>>>save_tmp_img
def save_tmp_img(visual_img):
file_name = "".join([str(random.randint(0, 9)) for _ in range(5)]) + ".jpg"
file_path = "/tmp/gradio" + file_name
visual_img.save(file_path)
return file_path
# >>>>>>>>>>>>>>> LLMへ ask <<<<<<<>>><<<<<<<>><<<<<<<<<<<<<<<<<<<<<<<<<
class Ask(BaseModel):
user_message: str
@app.post("/ask/")
def ask(gen_request:Ask):
global chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag, out_image
print(">>>>> ask")
user_message = gen_request.user_message
#if len(user_message) == 0:
# text_box_show = 'Input should not be empty!'
#else :
# text_box_show = ''
if isinstance(gr_img, dict): #gr_imgが辞書型か ?
gr_img, mask = gr_img['image'], gr_img['mask'] #辞書型ならimageとmaskを抜き出す
else:
mask = None #辞書型でないなら gr_imgはimageであり、maskはなし
# ユーザーが[identify]でバウンディングboxの位置を指定している時の処理
if '[identify]' in user_message: # ユーザーがバウンディングboxの位置を指定しているかどうか
##-?: ハイフン(-)が0回または1回現れることを示す. \d+: 1つ以上の数字(0から9までのいずれか)が1回以上現れることを示します
integers = re.findall(r'-?\d+', user_message) #txtから数字列を探し 、その数字をintegersにリストで記録
if len(integers) != 4: # ユーザーが4箇所のbboxを指定していない場合
bbox = mask2bbox(mask)
user_message = user_message + bbox
if chat_state is None:
chat_state = CONV_VISION.copy()
if upload_flag:
if replace_flag:
chat_state = CONV_VISION.copy() # new image, reset everything
replace_flag = 0
chatbot = []
img_list = []
llm_message = chat.upload_img(gr_img, chat_state, img_list)
upload_flag = 0
chat.ask(user_message, chat_state)
chatbot = chatbot + [[user_message, None]]
if '[identify]' in user_message:
visual_img, _ = visualize_all_bbox_together(gr_img, user_message,colors)
if visual_img is not None:
file_path = save_tmp_img(visual_img)
#chatbot = chatbot + [[(gr_img), None]]
chatbot = chatbot + [[(file_path,), None]]
out_image=visual_img #バウンディングbox付きの画像をout_imageに保管
result="Accepted"
return {'message':result, "chatbot":chatbot}Steram_answer
推論を実行します。必要なパラメータはtemperatureですが、デフォルトで0.6に設定しています。
# >>>>>>>>>>>>>>> LLMからの結果をストリームで取得 <<<<<<<>>>>>>>>>>
@app.post("/get_stream/")
async def get_stream( temperature:float=0.6):
global chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag, out_image
print(">>>>> get_stream")
generator_obj = stream_answer(chatbot, chat_state, img_list, temperature)
try:
for result in generator_obj:
output= result
print(".", end="")
except:
return {'message':"Generate error, try ask"}
print(output)
html_txt=reverse_escape(chatbot[-1][1])
print("html_txt=", html_txt)
text=html_txt.replace("<p>","").replace("</p","").replace("{","").replace("}","")
# 数値と特殊記号を除去する正規表現
clean_text = re.sub(r"[<>0-9]", "", text)
print("clean_text=",clean_text)
result="Generated"
return {'message':result, "chatbot":chatbot, "html_txt":html_txt,"text":text,"clean_text":clean_text}visualize
推論された出力からバウンディングポックスやラベル色付きの文字列生成などを行っています。要はAnswerの出力では文字や位置情報などが混在していて見にくので視覚化しようと言うわけです。前にも書きましたがこの部分に関係する関数などを含めると、コードの半分以上を占めています。
# >>>>>>>>>>>>>>> LLMからの結果を視覚化 <<<<<<<>>>>>>>>>>>>>>>
@app.post("/visualize/")
def visualize():
global chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag, out_image
print(">>>>> visualize")
if isinstance(gr_img, dict): # gr_imgはも元の画像, maskはイメージと同じサイズの黒い画像, 画像はPLIオブジェクト
gr_img, mask = gr_img['image'], gr_img['mask']
try:
unescaped = reverse_escape(chatbot[-1][1])
except:
return {'message':"visualize error ,try ask"}
visual_img, generation_color = visualize_all_bbox_together(gr_img, unescaped,colors)
print("0-unescaped-",unescaped)
if '[identify]' in chatbot [0][0]:
visual_img=out_image
print("generation_color =",generation_color )
if visual_img is not None:
if len(generation_color):
chatbot[-1][1] = generation_color
chatbot = chatbot + [[None, "file_path"]]#DUMMY
try:
html_colored_list=chatbot[-2]
except:
html_colored_list=""
else:
visual_img = gr_img
html_colored_list=["None",unescaped]
print("html_colored_list",html_colored_list)
#jesonで返信するためにbase64にエンコード
try:
img_byte_array = BytesIO()
visual_img.save(img_byte_array, format="PNG")
img_base64 = base64.b64encode(img_byte_array.getvalue()).decode()
result="Created"
except:
img_base64=""
result="error"
return {'message':result, "chatbot": chatbot ,"html_colored_list":html_colored_list,"visual_img":img_base64}これら以外にvisualize用の関数や出力文字の整理用の関数など、7種類が続きますが、割愛します。最後にコード全体は公開して置きます。
テスト
先程の実行順序を個別にテストするプログラムを準備しました。
REST→アップロード→ASK→stream_answer→Visiaraization
各プログラムはURL経由でFastAPIのエンドポイントを呼び出すようになっています。各コードをコピーして適切なpythonファイルとして保存し実行してください。実行順が違ったり、タスクによってはエラーになる場合もあります。オリジナルのDEMOでも同様に正しく操作をしないとエラーになります。
REST
初期化を行います
import requests
from PIL import Image
from io import BytesIO
# 送信するPIL形式の画像データ
image_file_path = '00016-331097358.png'
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/reset/' # FastAPIサーバーのURLに合わせて変更してください
# POSTリクエストを送信
response = requests.post(url)
# レスポンスを表示 return {"message": "Image received ","chatbot": chatbot}
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答message:", result.get("key"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)アップロード
画像をアップロードします。MAskデータの処理が追加されています。
import requests
from PIL import Image
from io import BytesIO
# 送信するPIL形式の画像データ
image_file_path = '00016-331097358.png'
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/uploadfile/' # FastAPIサーバーのURLに合わせて変更してください #Maskを作成 。IDENTIFYタスクで使う。その他の場合はイメージと同じ大きさのファイルを作成
pil_image=Image.open(image_file_path )
width, height = pil_image.size
mask = Image.new('L', (width, height), 0)
# ファイルデータをバイナリ形式に変換
img_byte_arr_m = BytesIO()
mask.save(img_byte_arr_m, format='PNG')
mask_img = img_byte_arr_m.getvalue()
# ファイルデータをバイナリ形式で読み込む
file_data = open(image_file_path, "rb").read()
# ファイルをアップロードするためのリクエストを作成
files = {
"file": ("img.png", BytesIO(file_data), "image/png"),
"mask": ("mask.png", BytesIO(mask_img), "image/png"),
}
# POSTリクエストを送信
response = requests.post(url, files=files)
# レスポンスを表示
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答chatbot:", result.get("chatbot"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)ASK
タスクを指定して何を実行すべきか指示をします。
import requests
from PIL import Image
from io import BytesIO
import json
# 送信するデータを準備
data = {
"user_message": "[grounding] describe this image in detail",
} #data ={
# "user_message": "[refer] clock tower",
# } #data ={
# "user_message": "[detection] clock tower",
# } #data ={
# "user_message": "[identify] clock tower",
# } #data ={
# "user_message": "[vqa]Please explaine colore of a clock tower",
# }
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/ask/' # FastAPIサーバーのURLに合わせて変更してください
# POSTリクエストを送信
response = requests.post(url, json=data)
# レスポンスを表示 return {"message": "ask_completed ","chatbot":chatbot}
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答chatbot:", result.get("chatbot"))
print("サーバーからの応答text_box_show:", result.get("text_box_show"))
else:
stream_answer_ans
推論を実行し結果を得ます。厄介な出力です。
import requests
from PIL import Image
from io import BytesIO
import json
# 送信するデータを準備
data = {
"temperature": 0.6,
}
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/get_stream/' # FastAPIサーバーのURLに合わせて変更してください
# POSTリクエストを送信
response = requests.post(url, json=data)
# レスポンスを表示 return {"message": "ask_completed ","chatbot":chatbot}
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答chatbot:", result.get("chatbot"))
print("サーバーからの応答html_txt:", result.get("html_txt"))
print("サーバーからの応答text:", result.get("text"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)Visiaraization
stream_answerからの出力を視覚化出来るようにデータを再編します。このテストではバウンディングボックスとラベル付き画像及びhtml形式のカラー説明文とバウンディングボックス位置を含むテキスト文が得られます。
import requests
from PIL import Image
from io import BytesIO
import json
import base64
from PIL import Image
# 送信するデータを準備
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/visualize/' # FastAPIサーバーのURLに合わせて変更してください
# POSTリクエストを送信
response = requests.post(url)
# レスポンスを表示
if response.status_code == 200:
result = response.json()
if result.get("message")=="Created":
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答chatbot:", result.get("chatbot"))
print("サーバーからの応答html_colored_list:", result.get("html_colored_list"))
decoded_image_data = base64.b64decode(result.get("visual_img"))
pil_image = Image.open(BytesIO(decoded_image_data ))
print("サーバーからの応答visual_img:", pil_image)
pil_image.show()
else:
print(result.get("message"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)GUIを動かす
今回の改造で、オリジナルのDemo同様にgradioいよるGUIを動かすことが出来ます。オリジナルとの違いは画像のアップロードが自動で出来ないことと、LLMからの生のメッセージがストリームで表示出来ないことです。一方で[grounding] や[detection] などのタスクで検出した物体の位置情報を表示する機能を追加しています。この機能は[identify] や[vqa]のときに位置情報を追加できるので便利です。
クライアント側APIモジュール
4つのテストプログラムを統合して、個別の関数として読み出せるようにしたモジュールです。アプリでimportとして利用します。
import requests
from PIL import Image
from io import BytesIO
import json
import base64
def reset(url ):
url = url+"/reset/" # FastAPIエンドポイントのURL
response = requests.post(url) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message") , result.get("key")
else:
return response.status_code,"None","None"
def upload(url , pil_image="",mask=""): # image_file_path 送信するPIL形式の画像データ
#バイナリストリームに画像を保存
img_byte_arr = BytesIO()
pil_image.save(img_byte_arr, format='PNG')
img_data = img_byte_arr.getvalue()
if mask=="":
width, height = pil_image.size
mask = Image.new('L', (width, height), 0)
img_byte_arr_m= BytesIO()
mask.save(img_byte_arr_m, format='PNG')
mask_img = img_byte_arr_m.getvalue()
# ファイルをアップロードするためのリクエストを作成
files = {
"file": ("img.png", BytesIO(img_data), "image/png"),
"mask": ("mask.png", BytesIO(mask_img), "image/png"),
}
url =url+"/uploadfile/" # FastAPIエンドポイントのURL
response = requests.post(url, files=files) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message") , result.get("chatbot")
else:
return response.status_code,"None","None"
def ask(url , task , user_message):
data = {
"user_message": task + user_message,
}
url =url+"/ask/" # FastAPIエンドポイントのURL
response = requests.post(url, json=data) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message"), result.get("chatbot")
else:
return response.status_code,"None","None"
def generate(url , key, temperature=0.6):
data = {
"temperature": temperature,
}
url =url+"/get_stream/" # FastAPIエンドポイントのURL
response = requests.post(url, json=data) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message"), result.get("clean_text"), result.get("text"), result.get("html_txt") , result.get("chatbot")
else:
return response.status_code,"None","None","None","None","None"
def visualize(url ):
url =url+"/visualize/" # FastAPIエンドポイントのURL
response = requests.post(url) # レスポンス
if response.status_code == 200:
result = response.json()
if result.get("message")=="Created":
decoded_image_data = base64.b64decode(result.get("visual_img"))
pil_image = Image.open(BytesIO(decoded_image_data ))
chatbot=result.get("chatbot")
return response.status_code, result.get("message"), result.get("html_colored_list"), pil_image , chatbot
else: #通信は成功したが上手く生成出来なかった時
print(result.get("message"))
return response.status_code, result.get("message"),"None","None","None"
else:
return response.status_code, "None","None","None","None"
GUIアプリ
オリジナルを最大現に尊重してクライアントアプリの見本となるように大幅に書き換えています。
import numpy as np
from PIL import Image
import re
import torch
import html
import gradio as gr
from client_api import reset, upload, ask, generate, visualize
url = "http://0.0.0.0:8001"
def gradio_reset():
responce, message , key = reset(url)
chatbot=[]
image="white.png"
text_input=""
return chatbot, image, text_input
def gradio_upload(image):
#image = {'image': <PIL.Image.Image image mode=RGB size=767x432 at 0x7F66A983F160>,
# 'mask': <PIL.Image.Image image mode=RGB size=767x432 at 0x7F6692691D60>}
print("upload=",image)
pil_image=image["image"]
mask=image["mask"]
responce, message, chatbot = upload(url , pil_image , mask)
return
def gradio_ask(user_message):
if len(user_message) == 0:
text_box_show = 'Input should not be empty!'
else:
text_box_show = ''
task_name=matched = re.findall(r'\[(.*?)\]', user_message)
if len(task_name)==0:
task = ""
else:
task_name=task_name[0]
if task_name=="":
task = ""
else:
task = "[" + task_name + "]"
user_message=user_message.replace(task,"")
responce, message , chatbot = ask(url , task , user_message)
return text_box_show
def gradio_stream_answer( temperature):
print("gradio_stream_answer")
responce, message, clean_text, text, html_txt , chatbot = generate(url , temperature)
print( chatbot )
genatae = str(chatbot[0][1])
genatae = genatae.replace("\\","")
print(genatae)
return genatae
def gradio_visualize():
print("gradio_visualize")
responce, message , html_colored_list , pil_image , chatbot = visualize(url )
html_txt=html_colored_list[1]
return pil_image,html_txt
def gradio_taskselect(idx):
prompt_list = [
'',
'[grounding] describe this image in detail',
'[refer] ',
'[detection] ',
'[identify] what is this ',
'[vqa] '
]
instruct_list = [
'**Hint:** Type in whatever you want',
'**Hint:** Send the command to generate a grounded image description',
'**Hint:** Type in a phrase about an object in the image and send the command',
'**Hint:** Type in a caption or phrase, and see object locations in the image',
'**Hint:** Draw a bounding box on the uploaded image then send the command. Click the "clear" botton on the top right of the image before redraw',
'**Hint:** Send a question to get a short answer',
]
return prompt_list[idx], instruct_list[idx]
def example_trigger(text_input, image):
# set the upload flag to true when receive a new image.
# if there is an old image (and old conversation), set the replace flag to true to reset the conv later.
return
title = """<h1 align="center">MiniGPT-v2 API Demo by Megu channel</h1>"""
introduction = '''
For Abilities Involving Visual Grounding:
1. Grounding: CLICK **Send** to generate a grounded image description.
2. Refer: Input a referring object and CLICK **Send**.
3. Detection: Write a caption or phrase, and CLICK **Send**.
4. Identify: Draw the bounding box on the uploaded image window and CLICK **Send** to generate the bounding box. (CLICK "clear" button before re-drawing next time).
5. VQA: Input a visual question and CLICK **Send**.
6. No Tag: Input whatever you want and CLICK **Send** without any tagging
You can also simply chat in free form!
'''
text_input = gr.Textbox(placeholder='Upload your image and chat', interactive=True, show_label=False, container=False, scale=8)
with gr.Blocks() as demo:
gr.Markdown(title)
gradio_reset()
with gr.Row():
with gr.Column(scale=0.5):
if gr.Image!="":
image = gr.Image(type="pil", tool='sketch', brush_radius=20)
temperature = gr.Slider(
minimum=0.1,
maximum=1.5,
value=0.6,
step=0.1,
interactive=True,
label="Temperature",
)
clear = gr.Button("Restart",variant='primary' )
img_upload = gr.Button("Image Uplad")
gr.Markdown(introduction)
with gr.Column():
text_output = gr.Markdown()
genatae = gr.Markdown()
pil_img = gr.Image(label="画像")
dataset = gr.Dataset(
components=[gr.Textbox(visible=False)],
samples=[['No Tag'], ['Grounding'], ['Refer'], ['Detection'], ['Identify'], ['VQA']],
type="index",
label='Task Shortcuts',
)
task_inst = gr.Markdown('**Hint:** Upload your image and chat')
with gr.Row():
text_input.render()
send = gr.Button("Send", variant='primary', size='sm', scale=1)
with gr.Row():
with gr.Column():
gr.Examples(examples=[
["examples_v2/office.jpg", "[grounding] describe this image in detail"],
["examples_v2/sofa.jpg", "[detection] sofas"],
["examples_v2/2000x1372_wmkn_0012149409555.jpg", "[refer] the world cup"],
["examples_v2/KFC-20-for-20-Nuggets.jpg", "[identify] what is this {<4><50><30><65>}"],
], inputs=[image, text_input], fn=example_trigger,
outputs=[])
with gr.Column():
gr.Examples(examples=[
["examples_v2/glip_test.jpg", "[vqa] where should I hide in this room when playing hide and seek"],
["examples_v2/float.png", "Please write a poem about the image"],
["examples_v2/thief.png", "Is the weapon fateful"],
["examples_v2/cockdial.png", "What might happen in this image in the next second"],
], inputs=[image, text_input], fn=example_trigger,
outputs=[])
clear.click(gradio_reset, queue=False) #reset リセット & GETキー
img_upload.click(gradio_upload, [image],[], queue=False) #アップロードイメージ
dataset.click(
gradio_taskselect,
inputs=[dataset],
outputs=[text_input, task_inst],
show_progress="hidden",
postprocess=False,
queue=False,
)
#text - boxでenterをした時
text_input.submit(
gradio_ask,
[text_input],
[text_input], queue=False
).success(
gradio_stream_answer,
[temperature],
[genatae ]
).success(
gradio_visualize,
[],
[pil_img, text_output],
queue=False,
)
#send ボタンをクリックした時
send.click(
gradio_ask,
[text_input],
[text_input], queue=False
).success(
gradio_stream_answer,
[temperature],
[genatae]
).success(
gradio_visualize,
[],
[pil_img,text_output],
queue=False,
)
demo.launch(share=False, enable_queue=True)
サーバ側の全体コード
とても長いです。次回はコードを3ファイルに分割し、改良して見通しの良いプログラムへ仕上げます。
import argparse
import os
import random
from collections import defaultdict
import cv2
import re
import numpy as np
from PIL import Image
import torch
import html
import torchvision.transforms as T
import torch.backends.cudnn as cudnn
from minigpt4.common.config import Config
from minigpt4.common.registry import registry
from minigpt4.conversation.conversation import Conversation, SeparatorStyle, Chat
# imports modules for registration
from minigpt4.datasets.builders import *
from minigpt4.models import *
from minigpt4.processors import *
from minigpt4.runners import *
from minigpt4.tasks import *
# ========== args
def parse_args():
parser = argparse.ArgumentParser(description="Demo")
parser.add_argument("--cfg-path", default='eval_configs/minigptv2_eval.yaml', help="path to configuration file.")
parser.add_argument("--gpu-id", type=int, default=0, help="specify the gpu to load the model.")
parser.add_argument("--options", nargs="+", help="override some settings in the used config, the key-value pair "
"in xxx=yyy format will be merged into config file (deprecate), "
"change to --cfg-options instead.", )
args = parser.parse_args()
return args
#========== INIT
random.seed(42)
np.random.seed(42)
torch.manual_seed(42)
cudnn.benchmark = False
cudnn.deterministic = True
print('Initializing Chat')
args = parse_args()
cfg = Config(args)
device = 'cuda:{}'.format(args.gpu_id)
model_config = cfg.model_cfg
model_config.device_8bit = args.gpu_id
model_cls = registry.get_model_class(model_config.arch)
model = model_cls.from_config(model_config).to(device)
bounding_box_size = 100
vis_processor_cfg = cfg.datasets_cfg.cc_sbu_align.vis_processor.train
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
model = model.eval()
CONV_VISION = Conversation(
system="",
roles=(r"<s>[INST] ", r" [/INST]"),
messages=[],
offset=2,
sep_style=SeparatorStyle.SINGLE,
sep="",
) #バウンディングboxで使用する色を定義
colors = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (210, 210, 0), (255, 0, 255), (0, 255, 255), (114, 128, 250), (0, 165, 255),
(0, 128, 0), (144, 238, 144), (238, 238, 175), (255, 191, 0), (0, 128, 0), (226, 43, 138), (255, 0, 255), (0, 215, 255),]
color_map = {
f"{color_id}": f"#{hex(color[2])[2:].zfill(2)}{hex(color[1])[2:].zfill(2)}{hex(color[0])[2:].zfill(2)}" for
color_id, color in enumerate(colors )
}
used_colors = colors
chat = Chat(model, vis_processor, device=device)
# =================================== FastAPI ==============================
from fastapi import FastAPI, File, UploadFile, Form
from fastapi.responses import HTMLResponse,StreamingResponse,JSONResponse
from pydantic import BaseModel
from io import BytesIO
import json
import base64
from function import mask2bbox, reverse_escape , escape_markdown, visualize_all_bbox_together
app = FastAPI()
global chatbot
global chat_state
global gr_img
global img_list
global upload_flag
global replace_flag
global out_image
# >>>>>>>>>>>>>>> リセット <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
@app.post("/reset/")
def reset( ):
print(">>>>> reset(")
global chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag, out_image
chatbot=[]
chat_state=None
gr_img=[]
img_list=[]
upload_flag=0
replace_flag=0
out_image=None
return {'message': "complete"}
# >>>>>>>>>>>>>>> LLMへ イメージのアップロード <<<<<<<<<<<<<<<<<<<<<<<<<<
@app.post("/uploadfile/") #def uploadfile(file: UploadFile ):
def upload_file(file: UploadFile = File(...), mask:UploadFile=File(...)):
global chatbot, chat_state, gr_img, img_list,upload_flag, replace_flag
print(">>>>> uploadfile")
if file:
image_data = file.file.read()
pil_img = Image.open(BytesIO(image_data)) # バイナリデータをPIL形式に変換
mask_img = mask.file.read()
pil_mask= Image.open(BytesIO(mask_img)) # バイナリデータをPIL形式に変換
else:
return {"message":"Error"}#"Error"
#元画像と同じサイズのマスクを作成
#w , h = pil_img.size
#mask = Image.new('RGB', [w,h], (0,0,0))
gr_img = {"image" :pil_img ,"mask":pil_mask}
upload_flag = 1 # set the upload flag to true when receive a new image.
if img_list: # if there is an old image (and old conversation), set the replace flag to true to reset the conv later.
replace_flag = 1
return {"message": "Uploadded","chatbot": chatbot}
# >>>>>>>>save_tmp_img
def save_tmp_img(visual_img):
file_name = "".join([str(random.randint(0, 9)) for _ in range(5)]) + ".jpg"
file_path = "/tmp/gradio" + file_name
visual_img.save(file_path)
return file_path
# >>>>>>>>>>>>>>> LLMへ ask <<<<<<<>>><<<<<<<>><<<<<<<<<<<<<<<<<<<<<<<<<
class Ask(BaseModel):
user_message: str
@app.post("/ask/")
def ask(gen_request:Ask):
global chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag, out_image
print(">>>>> ask")
user_message = gen_request.user_message
#if len(user_message) == 0:
# text_box_show = 'Input should not be empty!'
#else :
# text_box_show = ''
if isinstance(gr_img, dict): #gr_imgが辞書型か ?
gr_img, mask = gr_img['image'], gr_img['mask'] #辞書型ならimageとmaskを抜き出す
else:
mask = None #辞書型でないなら gr_imgはimageであり、maskはなし
# ユーザーが[identify]でバウンディングboxの位置を指定している時の処理
if '[identify]' in user_message: # ユーザーがバウンディングboxの位置を指定しているかどうか
##-?: ハイフン(-)が0回または1回現れることを示す. \d+: 1つ以上の数字(0から9までのいずれか)が1回以上現れることを示します
integers = re.findall(r'-?\d+', user_message) #txtから数字列を探し 、その数字をintegersにリストで記録
if len(integers) != 4: # ユーザーが4箇所のbboxを指定していない場合
bbox = mask2bbox(mask)
user_message = user_message + bbox
if chat_state is None:
chat_state = CONV_VISION.copy()
if upload_flag:
if replace_flag:
chat_state = CONV_VISION.copy() # new image, reset everything
replace_flag = 0
chatbot = []
img_list = []
llm_message = chat.upload_img(gr_img, chat_state, img_list)
upload_flag = 0
chat.ask(user_message, chat_state)
chatbot = chatbot + [[user_message, None]]
if '[identify]' in user_message:
visual_img, _ = visualize_all_bbox_together(gr_img, user_message,colors)
if visual_img is not None:
file_path = save_tmp_img(visual_img)
#chatbot = chatbot + [[(gr_img), None]]
chatbot = chatbot + [[(file_path,), None]]
out_image=visual_img #バウンディングbox付きの画像をout_imageに保管
result="Accepted"
return {'message':result, "chatbot":chatbot}
# >>>>>>>>>>>>>>> LLMからの結果をストリームで取得 <<<<<<<>>>>>>>>>>
@app.post("/get_stream/")
async def get_stream( temperature:float=0.6):
global chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag, out_image
print(">>>>> get_stream")
generator_obj = stream_answer(chatbot, chat_state, img_list, temperature)
try:
for result in generator_obj:
output= result
print(".", end="")
except:
return {'message':"Generate error, try ask"}
print(output)
html_txt=reverse_escape(chatbot[-1][1])
print("html_txt=", html_txt)
text=html_txt.replace("<p>","").replace("</p","").replace("{","").replace("}","")
# 数値と特殊記号を除去する正規表現
clean_text = re.sub(r"[<>0-9]", "", text)
print("clean_text=",clean_text)
result="Generated"
return {'message':result, "chatbot":chatbot, "html_txt":html_txt,"text":text,"clean_text":clean_text}
# >>>>>>>>>>>>>>> LLMからの結果を視覚化 <<<<<<<>>>>>>>>>>>>>>>
@app.post("/visualize/")
def visualize():
global chatbot, chat_state, gr_img, img_list, upload_flag, replace_flag, out_image
print(">>>>> visualize")
if isinstance(gr_img, dict): # gr_imgはも元の画像, maskはイメージと同じサイズの黒い画像, 画像はPLIオブジェクト
gr_img, mask = gr_img['image'], gr_img['mask']
try:
unescaped = reverse_escape(chatbot[-1][1])
except:
return {'message':"visualize error ,try ask"}
visual_img, generation_color = visualize_all_bbox_together(gr_img, unescaped,colors)
print("0-unescaped-",unescaped)
if '[identify]' in chatbot [0][0]:
visual_img=out_image
print("generation_color =",generation_color )
if visual_img is not None:
if len(generation_color):
chatbot[-1][1] = generation_color
chatbot = chatbot + [[None, "file_path"]]#DUMMY
try:
html_colored_list=chatbot[-2]
except:
html_colored_list=""
else:
visual_img = gr_img
html_colored_list=["None",unescaped]
print("html_colored_list",html_colored_list)
#jesonで返信するためにbase64にエンコード
try:
img_byte_array = BytesIO()
visual_img.save(img_byte_array, format="PNG")
img_base64 = base64.b64encode(img_byte_array.getvalue()).decode()
result="Created"
except:
img_base64=""
result="error"
return {'message':result, "chatbot": chatbot ,"html_colored_list":html_colored_list,"visual_img":img_base64}
#LLMからの結果をストリームで表示
def stream_answer(chatbot, chat_state, img_list, temperature):
if len(img_list) > 0:
if not isinstance(img_list[0], torch.Tensor):
chat.encode_img(img_list)
streamer = chat.stream_answer(conv=chat_state,
img_list=img_list,
temperature=temperature,
max_new_tokens=500,
max_length=2000)
output = ''
for new_output in streamer:
escapped = escape_markdown(new_output)
output += escapped
chatbot[-1][1] = output
yield chatbot, chat_state
chat_state.messages[-1][1] = '</s>'
return chatbot, chat_state
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8001)
サーバで使う関数をまとめています。 ファイル名:function.pyで作成して置きます。
from collections import defaultdict
from PIL import Image
import numpy as np
import cv2
import html
import re
# ******************* 内部関数 ************************** #LLMからの結果をストリームで表示
def stream_answer(chatbot, chat_state, img_list, temperature):
if len(img_list) > 0:
if not isinstance(img_list[0], torch.Tensor):
chat.encode_img(img_list)
streamer = chat.stream_answer(conv=chat_state,
img_list=img_list,
temperature=temperature,
max_new_tokens=500,
max_length=2000)
output = ''
for new_output in streamer:
escapped = escape_markdown(new_output)
output += escapped
chatbot[-1][1] = output
yield chatbot, chat_state
chat_state.messages[-1][1] = '</s>'
return chatbot, chat_state
#2つの矩形 (Rectangle) rect1 と rect2 が重なっているかどうかを判定する
def is_overlapping(rect1, rect2):
x1, y1, x2, y2 = rect1
x3, y3, x4, y4 = rect2
return not (x2 < x3 or x1 > x4 or y2 < y3 or y1 > y4)#矩形が重なっている場合、返される値は True であり、重なっていない場合は False
#この関数 computeIoU(bbox1, bbox2) は、2つのバウンディングボックス(Bounding Box) bbox1 と bbox2 の間の交差部分の面積と、 #それらのバウンディングボックスのIoU (Intersection over Union)スコアを計算するための関数です。 #2つのバウンディングボックスの重なり具合を数値化して比較することができます 。
def computeIoU(bbox1, bbox2):
x1, y1, x2, y2 = bbox1
x3, y3, x4, y4 = bbox2
#intersection_x1 、intersection_y1、intersection_x2、intersection_y2 を計算、2つのバウンディングボックスの交差部分の左上隅 と右下隅
intersection_x1 = max(x1, x3)
intersection_y1 = max(y1, y3)
intersection_x2 = min(x2, x4)
intersection_y2 = min(y2, y4)
#交差部分の面積
intersection_area = max(0, intersection_x2 - intersection_x1 + 1) * max(0, intersection_y2 - intersection_y1 + 1)
#各バウンディングボックスの面積
bbox1_area = (x2 - x1 + 1) * (y2 - y1 + 1)
bbox2_area = (x4 - x3 + 1) * (y4 - y3 + 1)
#IoUスコアを計算します 。これは、交差部分の面積をバウンディングボックスの合計面積から引いた後、合計面積で割った値です。
#IoUは常に0から1の間の値を取り 、0は重なりがないことを、1は完全に重なっていることを示します。
union_area = bbox1_area + bbox2_area - intersection_area
iou = intersection_area / union_area
return iou
#ユーザー指定のバウンディングbox部分のマスクを作成 ***** サンプルではここが呼ばれることはない *****
def mask2bbox(mask):
print("----- mask2bbox")
print(mask)
if mask is None:
return ''
mask = mask.resize([100, 100], resample=Image.NEAREST)#mask を100x100に縮小し、リサンプリングには最も近い隣接ピクセルの値を使用する
#mask多次元配列から 、非ゼロ行と、非ゼロ列を抽出。マスク内で実際に物体が存在する領域を特定する
mask = np.array(mask)[:, :, 0]
rows = np.any(mask, axis=1)
cols = np.any(mask, axis=0)
#非ゼロ行と非ゼロ列から 、バウンディングボックスの情報を抽出
if rows.sum():
#非ゼロ行の最小インデックス rmin と最大インデックス rmax、および非ゼロ列の最小インデックス cmin と最大インデックス cmax を取得
rmin, rmax = np.where(rows)[0][[0, -1]]
cmin, cmax = np.where(cols)[0][[0, -1]]
#抽出したバウンディングボックス情報を文字列としてフォーマット
#フォーマットは {{<left><top><right><bottom>}} の形式で、バウンディングボックスの左上隅と右下隅の座標
bbox = '{{<{}><{}><{}><{}>}}'.format(cmin, rmin, cmax, rmax)
else:
bbox = ''
return bbox
def escape_markdown(text): #文字列に "<" → "\<" に変換
md_chars = ['<', '>']
for char in md_chars:
text = text.replace(char, '\\' + char)
return text
def reverse_escape(text): # '\<' を '<' に変換
md_chars = ['\\<', '\\>']
for char in md_chars:
text = text.replace(char, char[1:])
return text
def extract_substrings(string):
import re
print("----- extract_substrings")
# first check if there is no-finished bracket 最後に現れる } のインデックスを検索、 index 変数に格納さ、 } が見つからなければ、indexには -1 が設定される
index = string.rfind('}')
if index != -1:
string = string[:index + 1]
#<p> 文字列に続き、最短一致(non-greedy)任意文字列(.*?)が続き、その後に }があるパターンでを設定。ただし、 } の後に < が続いていない場合
pattern = r'<p>(.*?)\}(?!<)'
#パターンに一致する部分文字列を matches というリストとして抽出す。
matches = re.findall(pattern, string)
substrings = [match for match in matches]#matchesと同じLISTが得られるが、COPYではないのでお互いに依存はしない、
#例 :['A young man</p> {<8><0><62><91>', 'a suit</p> {<7><35><56><88>', 'tie</p> {<29><46><41><89>', 'his desk</p> {<0><85><100><100>', 'a laptop</p> {<55><52><85><87>']
return substrings
# 画像とeverse_escapeで変換された位置情報を含む文字列から、バウンディングbox付き画像とhtmlで記述された色付き文字列を生成する
# generationはuser_message または reverse_escape(chatbot[-1][1]), reverse_escapeで変換された位置情報を含む文字列
# <p>sofas</p> {<57><49><70><72>}<delim>{<26><48><43><71>}
# OUT: バウンディングboxと文字が書き込まれた画像、 htmlで記述された色付き文章
def visualize_all_bbox_together(image, generation,colors):
bounding_box_size = 100
print("++++++ visualize_all_bbox_together")
print("generation=",generation)
if image is None:
return None, ''
#HTMLエンコードされた文字列を元のテキストにデコード (逆変換)する
generation = html.unescape(generation)
image_width, image_height = image.size
image = image.resize([500, int(500 / image_width * image_height)])
image_width, image_height = image.size
# first check if there is no-finished bracket
string_list = extract_substrings(generation)
if string_list: # grounding または detection の時
mode = 'all'
entities = defaultdict(list)
i = 0
j = 0
for string in string_list:
try:
obj, string = string.split('</p>')
except ValueError:
print('wrong string: ', string)
continue
bbox_list = string.split('<delim>')
flag = False
for bbox_string in bbox_list:
integers = re.findall(r'-?\d+', bbox_string)
if len(integers) == 4:
x0, y0, x1, y1 = int(integers[0]), int(integers[1]), int(integers[2]), int(integers[3])
left = x0 / bounding_box_size * image_width
bottom = y0 / bounding_box_size * image_height
right = x1 / bounding_box_size * image_width
top = y1 / bounding_box_size * image_height
entities[obj].append([left, bottom, right, top])
j += 1
flag = True
if flag:
i += 1
else:
integers = re.findall(r'-?\d+', generation)
if len(integers) == 4: # refer の時
mode = 'single'
entities = list()
x0, y0, x1, y1 = int(integers[0]), int(integers[1]), int(integers[2]), int(integers[3])
left = x0 / bounding_box_size * image_width
bottom = y0 / bounding_box_size * image_height
right = x1 / bounding_box_size * image_width
top = y1 / bounding_box_size * image_height
entities.append([left, bottom, right, top])
else:
return None, '' # don't detect any valid bbox to visualize
if len(entities) == 0:
return None, ''
if isinstance(image, Image.Image):
image_h = image.height
image_w = image.width
image = np.array(image)
elif isinstance(image, str):
if os.path.exists(image):
pil_img = Image.open(image).convert("RGB")
image = np.array(pil_img)[:, :, [2, 1, 0]]
image_h = pil_img.height
image_w = pil_img.width
else:
raise ValueError(f"invaild image path, {image}")
elif isinstance(image, torch.Tensor):
image_tensor = image.cpu()
reverse_norm_mean = torch.tensor([0.48145466, 0.4578275, 0.40821073])[:, None, None]
reverse_norm_std = torch.tensor([0.26862954, 0.26130258, 0.27577711])[:, None, None]
image_tensor = image_tensor * reverse_norm_std + reverse_norm_mean
pil_img = T.ToPILImage()(image_tensor)
image_h = pil_img.height
image_w = pil_img.width
image = np.array(pil_img)[:, :, [2, 1, 0]]
else:
raise ValueError(f"invaild image format, {type(image)} for {image}")
indices = list(range(len(entities)))
new_image = image.copy()
previous_bboxes = []
text_size = 0.5 # size of text
text_line = 1 # thickness of text int(max(1 * min(image_h, image_w) / 512, 1))
box_line = 2
(c_width, text_height), _ = cv2.getTextSize("F", cv2.FONT_HERSHEY_COMPLEX, text_size, text_line)
base_height = int(text_height * 0.675)
text_offset_original = text_height - base_height
text_spaces = 2
used_colors = colors # random.sample(colors, k=num_bboxes)
color_id = -1
for entity_idx, entity_name in enumerate(entities):
# ++++ mode == 'single' or mode == 'identify'
if mode == 'single' or mode == 'identify':
bboxes = entity_name
bboxes = [bboxes]
else:
bboxes = entities[entity_name]
color_id += 1 #色を更新
for bbox_id, (x1_norm, y1_norm, x2_norm, y2_norm) in enumerate(bboxes):
skip_flag = False
orig_x1, orig_y1, orig_x2, orig_y2 = int(x1_norm), int(y1_norm), int(x2_norm), int(y2_norm)
color = used_colors[entity_idx % len(used_colors)] # tuple(np.random.randint(0, 255, size=3).tolist())
new_image = cv2.rectangle(new_image, (orig_x1, orig_y1), (orig_x2, orig_y2), color, box_line)
# ++++ mode == 'all'
if mode == 'all':
l_o, r_o = box_line // 2 + box_line % 2, box_line // 2 + box_line % 2 + 1
x1 = orig_x1 - l_o
y1 = orig_y1 - l_o
if y1 < text_height + text_offset_original + 2 * text_spaces:
y1 = orig_y1 + r_o + text_height + text_offset_original + 2 * text_spaces
x1 = orig_x1 + r_o
# add text background
(text_width, text_height), _ = cv2.getTextSize(f" {entity_name}", cv2.FONT_HERSHEY_COMPLEX, text_size, text_line)
text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2 = x1, y1 - (
text_height + text_offset_original + 2 * text_spaces), x1 + text_width, y1
for prev_bbox in previous_bboxes:
if computeIoU((text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2), prev_bbox['bbox']) > 0.95 and \
prev_bbox['phrase'] == entity_name:
skip_flag = True
break
while is_overlapping((text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2), prev_bbox['bbox']):
text_bg_y1 += (text_height + text_offset_original + 2 * text_spaces)
text_bg_y2 += (text_height + text_offset_original + 2 * text_spaces)
y1 += (text_height + text_offset_original + 2 * text_spaces)
if text_bg_y2 >= image_h:
text_bg_y1 = max(0, image_h - (text_height + text_offset_original + 2 * text_spaces))
text_bg_y2 = image_h
y1 = image_h
break
if not skip_flag:
alpha = 0.5
for i in range(text_bg_y1, text_bg_y2):
for j in range(text_bg_x1, text_bg_x2):
if i < image_h and j < image_w:
if j < text_bg_x1 + 1.35 * c_width:
# original color
bg_color = color
else:
# white
bg_color = [255, 255, 255]
new_image[i, j] = (alpha * new_image[i, j] + (1 - alpha) * np.array(bg_color)).astype(
np.uint8)
cv2.putText(
new_image, f" {entity_name}", (x1, y1 - text_offset_original - 1 * text_spaces),
cv2.FONT_HERSHEY_COMPLEX, text_size, (0, 0, 0), text_line, cv2.LINE_AA
)
previous_bboxes.append(
{'bbox': (text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2), 'phrase': entity_name})
# ++++ mode == 'all'
if mode == 'all':
def color_iterator(colors):
while True:
for color in colors:
yield color
color_gen = color_iterator(colors)
def colored_phrases(match): # Add colors to phrases and remove <p></p>
phrase = match.group(1)
color = next(color_gen)
return f'<span style="color:rgb{color}">{phrase}</span>'
generation = re.sub(r'{<\d+><\d+><\d+><\d+>}|<delim>', '', generation)
generation_colored = re.sub(r'<p>(.*?)</p>', colored_phrases, generation)
else:
generation_colored = ''
pil_image = Image.fromarray(new_image)
# pil_imageはバウンディングboxと文字が書き込まれた画像、 generation_coloredはhtmlで記述された色付き文章
return pil_image, generation_colored
def get_stream_answer(chatbot, chat_state, img_list, temperature):
generator_obj = stream_answer(chatbot, chat_state, img_list, temperature)
try:
for result in generator_obj:
output= result
print(".", end="")
except:
return {'message':"Generate error, try ask"}
print(output)
return output
まとめ
MiniGPT-Vがプログラムから使えるようになりました。AIキャラでゲームをせ詰めさせたり、カメラ画像を説明させたり、物体認識をさせさりできるようになりました。ただ、今回のコードは無理やり変更した感があって、見通しも悪く、あまり実用的とは言えません。次回はコードを整理し、複数のチャットセッションにも対応できるように、大幅に改良したコードを公開します。実用的なコードに近づくと思います。
MiniGPT-Vはローカルで動くLLMとしては秀逸では無いかと思います。個別のLLMは能力が上がって来ましたが、タスクをこなすという意味ではまだ遅れていたかと思います。画像認識タスクをこなせるマルチモーダルLLMはAIキャラ以外にも様々な用途がありそうです。