
法人番号を使って輪番で働く/gBizINFOからデータをダウンロードしてPythonでどれだけ均等になっているかを調べる

どうしても出社しないといけない人がいるのはわかる。自動車であればナンバーの末尾、電話番号であれば下一桁をつかって利用者数を減らそうとする試みがある。また、混雑する時間帯に合わせて利用料金を変更するという手もある。
法人番号をつかって輪番で働くとした場合、法人番号のチェックデジットは先頭1桁だが分布はどのようになっているのだろうか。反対に、連番で発行された末尾についてはどのような分布になっているのだろうか。
法人番号は、会社法人等番号を利用してチェックデジットを計算し、会社法人等番号の先頭に付与した物である。
よりCSVをダウンロードする。
490万件ほどのデータがある。厳密には会社ではないものも含まれているが省いていない。また、閉鎖登記も含まれているかもしれないがチェックしていない。
pythonでcsvファイルを開き、なにも考えず配列にいれて、collections.Counterというものを使った。
import pandas as pd
import collections
df = pd.read_csv('Kihonjoho_UTF-8.csv', encoding="utf-8-sig", header=0, usecols=[0])
sentou = []
matsubi = []
print("DF処理")
print(df.info())
print(df.columns)
for houjinNO in df['"法人番号"']:
strhoujin = str(houjinNO)
sentou.append(strhoujin[0])
matsubi.append(strhoujin[-1])
print("集計開始")
print("法人番号-先頭桁-チェックデジット")
sentou_narabikae = collections.Counter(sentou)
sentou_sorted_key = collections.OrderedDict(
sorted(sentou_narabikae.items(), key=lambda x: x[0])
)
print(sentou_sorted_key)
print("法人番号-末尾")
matsubi_narabikae = collections.Counter(matsubi)
matsubi_sorted_key = collections.OrderedDict(
sorted(matsubi_narabikae.items(), key=lambda x: x[0])
)
print(matsubi_sorted_key)結果は、以下のようになった。なぜかdf['法人番号']と書いてキーが存在しないというエラーになったのでdf.columnsを実行したら'"法人番号"'と表示された。どうしてなの?
法人番号-先頭桁-チェックデジット
OrderedDict([('1', 546478), ('2', 546008), ('3', 545339), ('4', 545860), ('5', 545503), ('6', 545936), ('7', 546163), ('8', 545874), ('9', 546002)])
法人番号-末尾-チェックデジット
OrderedDict([('0', 491307), ('1', 492397), ('2', 491200), ('3', 490793), ('4', 491304), ('5', 491454), ('6', 491000), ('7', 491954), ('8', 490830), ('9', 490924)])チェックデジットは先頭につけられる事を見越して0はないようになっている。
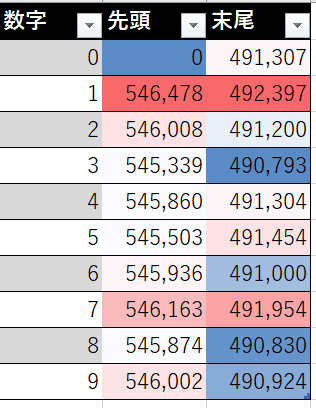
エクセルで見やすくした。先頭も末尾もそこそこよく混じっている。
数字 先頭 末尾
0 0 491307
1 546478 492397
2 546008 491200
3 545339 490793
4 545860 491304
5 545503 491454
6 545936 491000
7 546163 491954
8 545874 490830
9 546002 490924