データマネジメント知識体系(DMBOK)第5章「データモデリング」概説

イントロダクション
データモデリングとは、データ要件を洗い出し、分析し、取扱スコープを決めるプロセスである。
このデータ要件を表現し伝えるために、データモデルと呼ばれる明確に定義された様式が用いられる。
データモデリングはデータマネジメントに必須の要素である。
組織は、このモデリングプロセスを通じて、データの関係性を突き止め、文章化しなければならない。
このモデリングプロセスこそが、データの体系を設計することである。
データを表現するには、様々なスキームが用いられる
最も一般的に使用される6つのスキームは、リレーショナル、ディメンショナル、オブジェクト指向、ファクトベース、タイムベース、NoSQLである。
モデルがこれらのスキーム内で概念、論理、物理と言う3つのレベルで詳細化される。
各モデルには、1連の構成要素が含まれている。
エンティンティ
リレーションシップ
ファクト
キー属性など
モデルは作成された後にレビューされ承認され、維持されなければならない。
ビジネス上の意義
データモデルは、効果的なデータマネジメントを行うために不可欠なものである。
データに関する共通語彙を提供する。
組織のデータや情報システムに関しての明示的な知識を捉え文章化する。
プロジェクトにおいて主なコミニケーションツールとして使われる。
アプリケーションをカスタマイズ、統合、リプレイスする際の出発点となる
目標と原則
ビジネス上の意義と重複する箇所もある。
様々な観点を理解し確認して文章化することである。
それによりアプリケーションが現在または将来の業務要点とより厳密な整合性を持つようになる。さらにマスターデータマネジメントやデータガバナンスプログラムのような広範囲の取り組みを成功裏に完遂させる基礎が作られる。適切なデータモデリングを行えば
運用コストが削減され
将来の取り組みに再利用できる可能性が高まり
その結果、新しいアプリケーションを構築することも削減できる
データモデルは、メタデータを記述する重要な様式である
本質的な概念
データモデリングとデータモデル
データモデリング
データモデリングはシステム開発、ライフサイクルと呼ばれるシステム開発、予備保守作業のコンテクストの中で最も頻繁に行われる。
データモデリングは広範な取り組み(業務設計やデータ設計、マスター管理、データ、ガバナンスなど)の中で実施される。
この場合、組織のデータを理解するのが直接的な目的となり、必ずしも最終的にデータベースを作るとは限らない。
データモデル
データモデルは組織が把握した現状の姿、あるいは組織が望むあるべき姿として、組織のデータを記述する。
データモデルには、文字付きのシンボル群が含まれ、データモデラーが把握したデータ要件が資格的に表現される。
プロジェクトごとの小さなスケールから、組織用の大きなスケールと様々なサイズのものがある。
モデルはドキュメントの位置形式であり、モデリングプロセスでとらえたデータ要件とデータ定義を表現する。
データモデルは、データ要件を伝えるための主要な手段であり、業務からIT、ITからIT、アナリスト、もでらー、アーキテクトからデータベースデザイナーや開発者へ、データ要件を伝える際に使われる。
モデリングの対象となるデータの種類
モデル化の対象となるデータは、主に4種類ある。
データモデルを必要とする組織やプロジェクトの優先順位によってモデル化されるデータの種類が異なる。
カテゴリー情報:
モノを種別し分類するために使用されるデータ。
市場分野や事業部門ごとに分類された顧客、色モデルサイズなどで分類された製品、処理済みか未処理化によって分類された注文…など。リソース情報:
製品、顧客、サプライヤ、設備、組織、口座などであり、業務プロセスを実行するための基本になる。業務イベント情報:
業務プロセスの中で作成されたデータ。
注文、請求、現金、出納、業務打ち合わせ等が含まれる。
IT技術者の間では、トランザクション業務データと呼ばれることもある。詳細取引情報:
詳細な取引情報は、POSシステムから生成されることが多い。またソーシャルメディアセンサー船舶や車両の部品、産業用部品、パーソナルデバイスの場合もある。
この種の詳細情報から集計データや導出データが生成され、傾向を武運咳することができる。
この点では業務イベント情報の使われ方と同様である。
大容量であったり、急速に変化したりする。この手のデータは通常ビックデータと呼ばれる。
データモデルの構成要素
データモデルの種類によって、データの表現方法は異なる。
ただし、ほとんどのデータモデルには、エンティティ、リレーションシップ、属性ドメインと言う基本的な構成要素が含まれている。
エンティティー
データモデリングが離れて、一般的にエンティティとは他のものから分離されて自立している存在と定義される。
データモデリングの世界でエンティティはある組織が情報を収集する対象のことである。
エンティティは、組織が使う名詞と呼ばれることもある。
エンティティは誰が、何を、いつ、どこで、なぜ、どのようにといった基本的な疑問詞や、その組み合わせに対する回答と考えることができる。
表7「一般的に使えるエンジェティカテゴリー」では、一般的に使用されるエンティティー分類定理と例を示している。
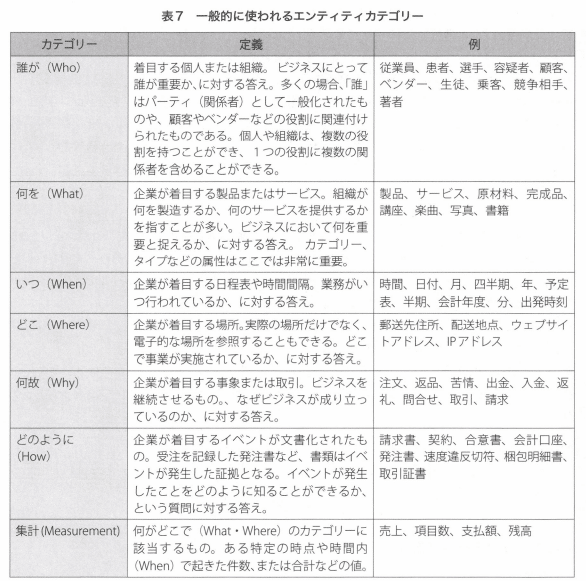
エンティティという一般用語は、違う名称で呼ばれることがある。
表8の場合、今日では従業員がエンティティであり、ジェーンはエンティティインスタンスとする言い方が広く普及している。

エンティティの別称は詳細レベルによっても異なる
概念レベル: 概念または用語と呼ばれる。
論理レベル: エンティティと呼ばれる。
物理レベル: テーブルと言う用語が最も一般的である。
エンティティの図式技法
データモデルは、図のようにエンティティを名称が内側に書かれた長方形で表すことが一般的である。

エンティティーの定義
データモデルがビジネス上の価値を持つにはエンティティ定義が不可欠である。エンティティ定義はメタデータの核となる。この定理の品質を上げることにより、業務用語の意味が明確になり、エンティティ間のリレーションシップを規定する業務ルールも厳格になる。さらに業務上の意思決定やITの専門家がアプリケーション設計上の意思決定を合理的に下す上で役に立つ。
データ提示の品質には、次の3つの重要な特性がある
明瞭性: 定義は読みやすく、理解しやすいものでなければならない。
曖昧な略語や、「時には」「普通は」など説明のつかない表現がなく、シンプルでよく練られた文章のことである。正確性: 定義はエンティティを正確かつ詳細に記述する。
関連事業分野の専門家によってレビューされ正確であることが確認されなければならない。完全性: 定義は必要なすべての項目が書かれなければならない。
コードを定義する場合、コード値の例を含める一意識別子の定義には、どの範囲で一意かを含まなければならない。
リレーションシップ
リレーションシップとは、エンティティー間の関連性である。
リレーションシップには、概念エンティティー間の概念的相互作用、論理エンティティ間の詳細な相互作用、物理エンティティー間では制約が表現される。
リレーションシップの別帳は、詳細レベルに応じて異なる場合もある。
概念レベルと論理レベルのリレーションシップはリレーションシップと呼ばれる
物理レベルのリレーションシップは採用するデータベース技術により制約や参照など他の名前で呼ばれることがある。
リレーションシップの図式表現
リレーションシップは、データモデル図に線として表現される。
いかずには、IE(Information Engineering)表記法の例を示す。

データモデリングスキーム
データを表現するために、リレーショナル、ディメンショナル、オブジェクト指向、ファクトベース、タイムベース、NoSQLと言う最も一般的な6つのスキームが使用される。各スキームは特定の表記法を使用する。
以下によく使われるであろうリレーショナルスキームとディ面書なるスキームについてのみ記載する。
リレーショナルスキーム
1970年エドワード・コッド博士によって最初に提唱された。
リネーショナル理論は、データの意味が反映されるようになるデータを組織化し、体系化する方法を示している。このアプローチは、データストレージの冗長性を減らすと追加の効果をもたらした。2次元のリレーションを使えば、データは非常に効果的に管理できると見通したのはコッドであった。
リレーショナルモデルの設計目標は、業務データを正確に表現し、1つの事実を1つの場所で持つこと(つまり冗長性の除去)
リレーショナルモデリングは情報を素早く入力し、正確に保存する必要がある業務用システムの設計に理想的である。
IE、IDEF1X、バーガー、チェンなどの表記法を含め、リレーショナルモデリングにおけるエンティティ間の関連性を表現する表記法はいくつかある。
最も一般的な形式はIE構文であり、カーディナリティを描くため分かりやすい三叉「カラスの足」を使う。

ディメンショナルスキーム
ディメンショナルモデリングの概念は、1960年代にゼネラルミルズとダートマス大学が共同で実施したプロジェクトから始まった。
大量データに対する問い合わせと分析が最適化されるようにデータが構造化されている。
対照的にトランザクション処理をサポートするオペレーションシステムは、個々のトランザクションを高速処理するために最適化。
特定の業務プロセスに的を絞った業務上の設問に対応する。
このモデルを作成するために使用された「分析軸表記法」は、伝統的なデータモデリング構文を読もうとしない人に対しても、非常に効果的なコミュニケーションツールとなる。
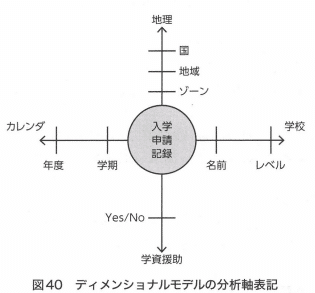
リレーショナルスキームとディメンショナルスキーム
リレーショナル及びディメンショナル両方の概念データモデルは、同じ業務プロセスを対象に作成できる。
リレーショナルモデルでは、リレーションシップの線が業務ルールをとらえ
ディメンショナルモデルでは、業務的設問に答えるために必要なナビゲーションパスを捉える
(補足)表記法の紹介
IE法

IDEF1X

データモデルの詳細レベル
1975年に米国規格協会の標準計画及び要件委員会は、データベース管理に対して三層スキーマアプローチを発表した。
概念スキーマ:
企業がどう現実を見ているかと言う視点がデータベース上にモデル化され、それを概念スキーマが体現する。企業にとって、現状の最良モデル、または業務遂行方法を表す。外部スキーマ:
データベースシステムを使う様々な利用者は全社統合モデル全体の中で特定ニーズを満たすためにあるサブセットを使用する。このサブセットが外部スキーマとして表現される。内部スキーマ:
データのマシンビューは内部スキーマによって記述される。このスキーマは格納された全社情報を表す。
これら3つのレベルは、一般的にそれぞれ概念、論理、物理などの詳細レベルに変換されることが多い。
プロジェクト内では、概念と論理は、要件計画と分析活動の一部であり、物理は設計活動である。
概念モデル: 関連する概念の集合体として、データ要件の概要が取り込まれる。
特定の領域や業務機能に関する基本的で重要なビジネスエンティティーのみが含まれ、各エンティティの説明とエンティティ間のリレーションシップが含まれる。論理モデル: 詳細なデータ要件が表現されたものであり、通常アプリケーション要件のような特定の使用シナリオに適用する。
技術や具体的な実装上の制約から独立しており、概念モデルの拡張として始まることが多い。物理モデル: 詳細な技術的ソリューションを表す。
論理モデルを出発点として作成されることが多く、ハードウェア、ソフトウェア、ネットワークツールを組み合わせた環境に適応するように設計される。
物理モデルは特定のテクノロジ向けに構築される。例えばリレーショナルDBMSはデータベース管理システムが持つ特定の機能を考慮して設計する必要がある。
正規化
正規化は業務の複雑性を整理し、安定したデータ構造を導くためにルールを適用するプロセスである。
第1正規形から第3正規形、ボイス・コッドの正規形、第4、第5整形が紹介されている。
正規化モデルと言う用語は通常データが第3正規形であることを意味し、ボイスコットの正規形、第4、第5正規形が必要な状況は稀である。
抽象化
抽象化とはある概念や対象に関する重要な性質や本質を保ちつつ、より、多種類の状況へ広く適応できるような方法を細部で取り除くことである。
モデラーや開発者によっては抽象化に慣れていなかったり、抽象化したものは使える能力を持っていなかったりする。モデラーは、抽象的な構造の開発と維持にかかるコストと抽象化されていないデータ構造を将来変更するときに必要となる。やり直しの量を比較する必要がある。
抽象化には、汎化プロセスと特化プロセスが含まれる。
汎化プロセス: エンデの共通属性とリレーションシップスーパーエンティティーにまとめる
特化プロセス: サブタイプに属性をサブタイプエンティティーに分割する。特価は、通常GTインスタンス内の属性にも基づいて行われる。
役割や分類を考え、エンティティーのインスタンス機能ごとにグループ分けしてサブタイプを作成することもできる。
アクティビティ
データモデリング計画
データモデリング計画には、組織要件の評価、標準類の作成、データモデルの保存方法の決定等のタスクが含まれる。
ダイヤグラム:
データモデルには1つまたは複数のダイヤグラムが含まれている。これらのダイヤグラムは、要件を正確な形で捉え、可視化したものである。そこでは、概念、論理、物理などの詳細レベル、スキーム、選択されたスキームで使用する表記法等が描写される。定義:
エンティティー属性リレーションシップの定義は、データモデルの精度を維持するために不可欠である。問題と未解決の疑問:
データモデリングの段階で対処できない問題や疑問が頻繁に発生する。さらにこれらの問題を解決し、疑問に答える責任者やグループがデータモデルを構築するグループにはいないことがある。したがって多くの場合、現在の問題点と未解決の疑問点がドキュメントに記述され、彼らに引き渡されるリネージ:
物理データモデルや論理データモデルにおいてデータリネージ、つまりデータがどこから来るのかを知ることが重要である。多くの場合、リネージはソース、ターゲットのマッピング形式を取る。ここでソースシステムの属性データからターゲットシステムの属性データへ取り込む方法を把握できる同じモデリング作業において、リネージは、概念モデルから論理モデル論理モデルから物理モデルへとデータモデリング要素をトレースできる。
データモリング中にリネージをとらえることが2つの理由から重要モデラーはデータ要件を非常に深く理解し、ソース属性を決定するのに最適な立場である
ソース属性を決定することが、モデルとマッピングの正確性を検証する有効な手段となる
データモデルの構築
モデラーはモデルを構築するにあたり、以前に行った分析結果とモデリング経験に大きく依存することが多い。モデルは既存のデータモデルとデータベースを調査し公表された標準を参照し、データ要件を取り込む。これらのインプットが検討されたとモデルの構築を始める。モデルは非常に反復的なプロセスである。モデラーはモデルをドラフトした後、業務側の専門家やビジネスアナリストにあって、用語や業務ルールを確認する。それをもとにモデルを更新し、さらにまた多くの質問を投げかける。
フォワードエンジニアリング
新しいアプリケーションを構築する際に要件定理から始めるプロセスである。取り組むべきスコープと、その中で取り扱う重要な要望を把握するために、概念データモデルを最初に完成させる。次に業務ソリューションを文書化するために、論理データモデルを完成させ、続いてITソリューションを文章化するために、物理データモデルを完成させる。
概念データモデルリング
スキームを選択する
表記法を選択する
スキームが選択されたら、IEやORMなど適切な表示法を選択する。表示法は、組織内の標準とそのままモデルの利用者が特定の表示法に慣れているかどうかによって選ばれる。概念データモデルの初版を完成させる
初版概念データモデルは、業務ユーザグループの視点で捉える必要がある。ただし、その視点とタブ門や組織全体との整合性を取ろうとして、プロセスを複雑にすべきではない。全社の共通用語を取り込む
データモデラーは四角と線を書き、ユーザの視点で捉えた後、全社で扱う用語や業務ルールの一貫性を確保し、全社の視点を捉える。承認を得る
初期モデルが完成したら、データモデリングのベストプラクティスと言う観点と、要件を満たしているかと言う観点からモデルがレビューされたことを確認する。
論理データモデリング
情報要件の分析
既存文章の分析
関連エンティティーの追加
多対多のリレーションシップを記述するために使用される。あるリレーションシップに参加するエンティティーから識別属性を取り、それを新しいエンティティに追加するとリレーションシップだけを記述する関連エンティティとなる。属性の追加
概念モデルエンティティに属性を追加する。論理データモデルの属性はアトミックでなければならない。アトミックな属性とは、その中にたった1つのデータしか入らないもので、そのデータをそれ以上分割できない。ドメインの割り当て
ドメインによって、プロジェクト内、プロジェクト間でのフォーマットと値の整合性を取れる。キーの割り当て
エンティティに割り当てられる属性はキー属性または非キー属性のいずれかである。キー属性は完全にまたは部分的に1つのユニークなエンティティインスタンスを、他のすべてから区別する役割を担う。非キー属性はエンティティインスタンスを記述するが、エンティティインスタンスを一意に識別することには役立たない。こうして主キーと代替キーを特定する。
物理データモデリング
論理データモデルで使われる抽象化の解決
・サブタイプの統合
・スーパータイプの分割属性に関する詳細の追加
参照データオブジェクトの追加
・別個のコード、テーブルを作成
・コードテーブル共有マスターの作成
・ルール、または有効なコードを該当オブジェクトの定理に埋め込むサロゲート地の割り当て
パフォーマンスのための非正規化
パフォーマンス向上のためのインデックス
パフォーマンスのためのパーティション分割
ビューの作成
その他のアクティビティ
データモデルのレビュー
他のIT分野と同様に、モデルは品質管理が必要であり、継続的な改善手法が採用されるべきである。価値獲得に要する期間、サポート、コスト、データモデルスコアカードのようなデータモデル品質検証といった技法は、すべてモデルの正確性、完全性、一貫性を評価するために使用できる。概念 / 論理 / 物理モデルが完成すると、ビジネスアナリストから開発者までモデルを理解する必要のある役割を持つすべての人にとって非常に便利なツールになる。
データモデルの維持と更新管理
データモデルは構築後、最新の状態に保つ必要がある。要件が変更されたり、業務プロセスが変更されたりした場合、データモデルを更新する特定のプロジェクトではあるレベルのモデルを変更する必要がある場合よりハイレベルのモデルを変更することになる。
ツール
データモデリングツール: データモデリングツールはデータモデルが行う多くのタスクを自動化するソフトウェア。
リネージュツール: データモデル上の各属性に対する構成を取得し、それを保守できるソフトウェア。
データプロファイリングツール: データの中身を調べ、既存のメタデータと照らし合わせて検証できるもの。
メタデータリポジトリ: データモデルに関する記述情報を格納するソフトウェアである。
データモデルパターン: 幅広い状況に適応できる再利用可能なモデリング構造であり、初級パターンは全部パターン、統合パターンなどがある。
業界データモデル: 医療、テレコム、保険、銀行業務、製造業など、業界全体であらかじめ構築されたデータモデルである。これらのモデルは多くの場合範囲が広く非常に詳細に書かれている。業界モデルには数千のエンティティー属性が含まれていることがある。
データモデリング品質の評価方法
データモデル検証に使用される。1つの方法としてデータモデル・スコアカードがある。
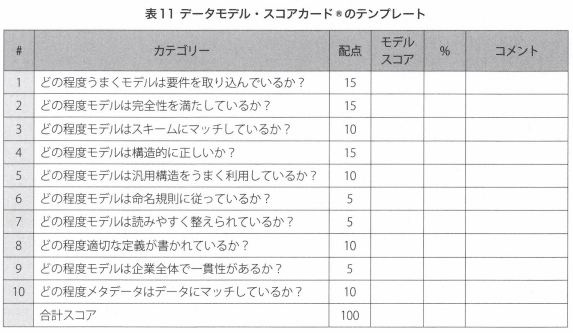
モデルスコアの欄には、特定のモデルがスコアリング基準をどれくらいうまく満たしているかについて評価者の評価が書き込まれる。
このスコアカードは、モデル品質の全体を評価し、改善を要する領域を特定できる。
この記事が気に入ったらサポートをしてみませんか?