40代文系プログラミング未経験サラリーマンのPython学習 (Aidemy Premium plan)

はじめに
40代の文系、プログラミング未経験のサラリーマンです。会社では予算策定や予実分析などをしており、今後、予算策定などの経営業務は、外部環境や経済環境を踏まえてAIで行った方が精度が高くなるだろうと考えていたため、AIについて学ぶべくAidemyに申し込みました。
学習環境と振り返り
3ヶ月の短期間コースを選択したため、受講する時間を確保するのが大変でした。平日は出社前に会社近くのカフェにてIpadで受講し、週末は自宅でまとまった時間を取りPCで受講しました。受講はIpadでも出来たので、非常に便利でした。営業マンの方は、外出先・出張先でもIpadで受講することで、時間を有効活用出来ると思いました。
環境
Python3
Macbook Air
Google Colaboratory
実際のプログラミングについて
気温によるLPガス販売数量の変化について、都道府県ごとに相関関係を検証しました。また、最後にLPガス販売数量を予測し、実測値との精度を調べました。
1.データの取得と前処理
■LPガス販売数量のデータ
日本LPガス協会のHPから都道府県別の月別LPガス販売量のデータをダウンロードします。
ダウンロードしたエクセルの状態
但し、そのままでは、時系列の地域毎の販売データとして活用できません。
①月毎に1つのエクセルファイルになっている
②月によって記載様式が異なり、必要なデータが同じ行・列にない
③ファイル名が「fukenbetsu_R0306.xls」など、令和、平成で異なるため
時系列の順番付けがうまく出来ない
そこで手作業で全てのエクセルファイルの余分な情報を削除し、同じ様式にします。コードで処理しようとしましたが、難易度が高く無理でした。
同じ様式にしたエクセルファイルを全てGoogleDriveに保存します。GoogleDriveのファイルを読み込み、データを整える関数を作ります。
そして、GoogleDriveの月別のファイルを年月順に読み込みます。
ファイル名は平成と令和が混在しているので西暦に変換し、データに追加します。
# gdriveのファイルをマウント
from google.colab import drive
drive.mount('/content/drive')# ライブラリのインポートと定数宣言
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
LPGAS_DIR = "/content/drive/MyDrive/lpgas_data/"
#エクセルから必要なデータだけ取り出すようにデータの前処理
def read_excel(excel_file_path):
input_book = pd.ExcelFile(excel_file_path)
input_sheet_df = input_book.parse("全国")
input_sheet_df = input_sheet_df[["Unnamed: 1","家庭業務用"]]
input_sheet_df= input_sheet_df.drop(input_sheet_df.index[[0, 8, 20, 26, 34, 40, 45, 54, 55]])
input_sheet_df= input_sheet_df.rename(columns={"Unnamed: 1": "都道府県", "家庭業務用": "数量"})
return input_sheet_df
#フォルダにある全てのエクセルを読み込む
import os
directory = os.listdir(LPGAS_DIR)
print("dirctory check")
print(directory)
#ファイルについている年月順に読み込む
directory=sorted(directory)
print("sorted dirctory check")
print(directory)
#フォルダ内のファイル全ての読み込んでいるか確認
for file in directory:
filepath= LPGAS_DIR+file #print (read_excel(filepath))
#読み込んだデータのファイル名を基に 、列に年月を追加する。
df=pd.DataFrame()
for file in directory:
filepath= LPGAS_DIR+file
year_str = file.split("_")[1].split(".")[0]
if year_str[0] == "R":
year_ = 2018 + int(year_str[1:3])
elif year_str[0] == "H":
year_ = 1988 + int(year_str[1:3])
year = str(year_)+"/"+str(int(year_str[3:5]))
df = pd.concat([df,read_excel(filepath).set_index('都道府県').rename(columns={'数量': year}).T])
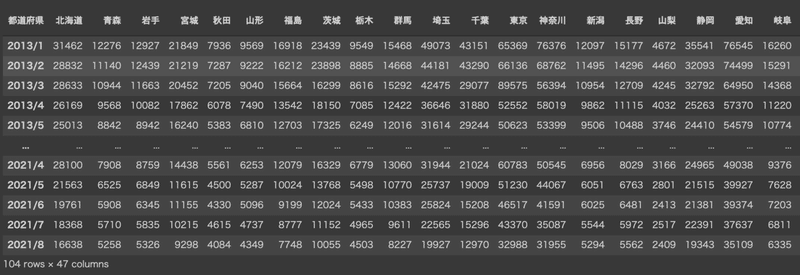
df.index結果、このようなデータフレームを作ることができました。
2013年1月〜2021年8月まで104ヶ月分の都道府県別LPガス販売数量です。
■気温のデータ
次に、気象庁のHPから入手した都道府県別の気温のデータを読み込みます。
県庁所在地ごとのデータのため、LPガス販売数量データの列名と合わせるために、都道府県の名前に変更します。
# 気温のデータを読み込み
df_temp = pd.read_csv("/content/drive/MyDrive/temp/temp_data3.csv")
df_date = df_temp['年'].astype(str).str.cat(df_temp['月'].astype(str), sep='/')
df_temp["月"]= df_date
df_temp = df_temp.drop('年',axis=1) #LPガス数量のデータと行を合わせるために改名する 。
df_temp= df_temp.rename(columns={"札幌": "北海道", "盛岡": "岩手", "水戸": "茨城", "仙台": "宮城", "宇都宮": "栃木", "前橋": "群馬", "さいたま":"埼玉","横浜":"神奈川", "甲府":"山梨", "津":"三重", "金沢":"石川", "大津":"滋賀", "神戸":"兵庫", "松江":"島根", "松山":"愛媛", "那覇":"沖縄"})
df_temp = df_temp[21:125]
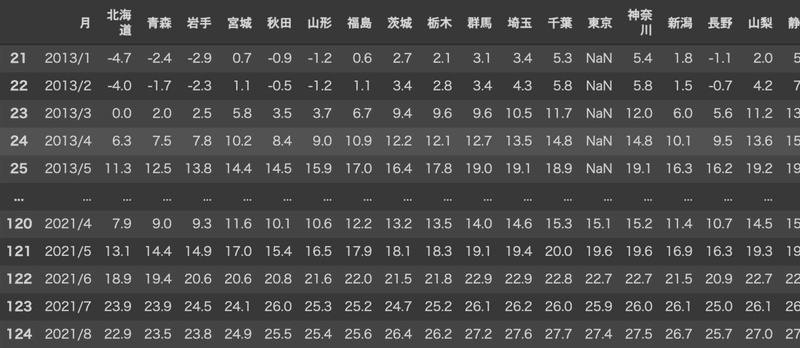
df_temp結果、このようなデータフレームが作れました。
2013年1月〜2021年8月まで104ヶ月分の都道府県別平均気温のデータです。
2.取得データの分析
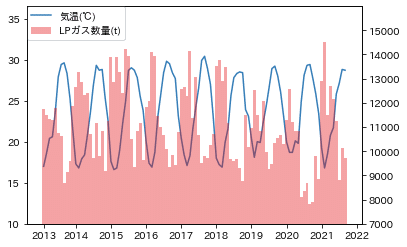
次に、北海道の気温とLPガス販売数量のグラフを作ります。
まず、グラフを作るためにjapanize_matplotlibをインストールし、
X軸を年月、Y軸をLPガス販売数量とした2軸グラフを作ります。
!pip install japanize_matplotlibimport numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
import japanize_matplotlib
%matplotlib inline
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
# 2軸グラフの本体設定
ax1.plot(df_temp["月"], df_temp["北海道"],
color=cm.Set1.colors[1], label="気温(℃)")
ax2.bar(df.index, df["北海道"],
color=cm.Set1.colors[0], alpha=0.4, width=1, label="LPガス数量(t)") #X軸の日付けをシンプルにする
plt.xticks([0, 11, 23, 35, 47, 59, 71, 83, 95, 107], list(map(str,list(range(2013,2023)))))
# label1と2には、凡例用に各labelのリスト情報が入る
handler1, label1 = ax1.get_legend_handles_labels()
handler2, label2 = ax2.get_legend_handles_labels()
# 凡例をまとめて出力する
ax1.legend(handler1 + handler2, label1 + label2, loc=2, borderaxespad=0.)
temperature_max = 1.2*max(df_temp["北海道"])
lp_gas_max = 1.1*max(df["北海道"])
ax1.set_ylim([-10, temperature_max])
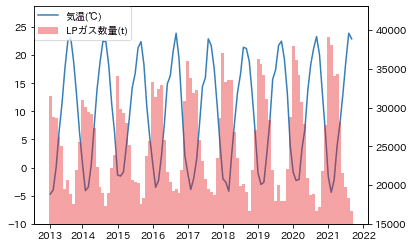
ax2.set_ylim([15000, lp_gas_max])一般的に、気温が下がるとお湯を使うようになるので、LPガス販売数量が増えるという仮説を持っていましたが、その通りの結果が見られました。
気温が一番下がった時に、LPガス数量がピークになっています。
沖縄県についても見てみます。同様に相関が見られます。
次に、北海道における気温を要因(説明変数)として、LPガス販売数量の予測器を構築します。Xを気温、YをLPガス販売数量、2013年1月〜2019年10月まで(80%)を訓練データ、2019年11月〜2021年8月まで(20%)をテストデータに分割し、線形回帰、ラッソ回帰、リッジ回帰、ランダムフォレストを使いました。
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
#北海道における気温を要因 (説明変数)として、LPガス販売数量の予測器を構築
X = df_temp[["北海道"]].values
y = df[["北海道"]].values
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2 , random_state=42, shuffle=False)
best_model = ""
pred_model = []# 線形回帰
model = LinearRegression()
model.fit(train_X, train_y)
# test_X, test_yに対する決定係数を出力する
print("Linear regression:{}".format(model.score(test_X, test_y)))
# ラッソ回帰
model = Lasso()
model.fit(train_X, train_y)
# test_X, test_yに対する決定係数を出力する
print("Lasso regression:{}".format(model.score(test_X, test_y)))
# リッジ回帰
model = Ridge()
model.fit(train_X, train_y)
# test_X, test_yに対する決定係数を出力する
print("Ridge regression:{}".format(model.score(test_X, test_y)))
#ランダムフォレスト
model = RandomForestRegressor()
model.fit(train_X, train_y)
# test_X, test_yに対する決定係数を出力する
print("RandomForestRegressor:{}".format(model.score(test_X, test_y)))
それぞれ0.83以上と高い予測精度が見られます。
次に、沖縄県における気温を要因(説明変数)として、LPガス販売数量の予測器を構築します。
#沖縄における気温を要因 (説明変数)として、LPガス販売数量の予測器を構築
okinawa_X = df_temp[["沖縄"]].values
okinawa_y = df[["沖縄"]].values
okinawa_train_X, okinawa_test_X, okinawa_train_y, okinawa_test_y = train_test_split(X, y, test_size=0.2 , random_state=42)
best_model = ""
pred_model = []# 線形回帰
model = LinearRegression()
model.fit(okinawa_train_X, okinawa_train_y)
# test_X, test_yに対する決定係数を出力してください
print("Linear regression:{}".format(model.score(okinawa_test_X, okinawa_test_y)))
# ラッソ回帰
model = Lasso()
model.fit(okinawa_train_X, okinawa_train_y)
# test_X, test_yに対する決定係数を出力してください
print("Lasso regression:{}".format(model.score(okinawa_test_X, okinawa_test_y)))
# リッジ回帰
model = Ridge()
model.fit(okinawa_train_X, okinawa_train_y)
# test_X, test_yに対する決定係数を出力してください
print("Ridge regression:{}".format(model.score(okinawa_test_X, okinawa_test_y)))
#ランダムフォレスト
model = RandomForestRegressor()
model.fit(train_X, train_y)
# test_X, test_yに対する決定係数を出力する
print("RandomForestRegressor:{}".format(model.score(test_X, test_y)))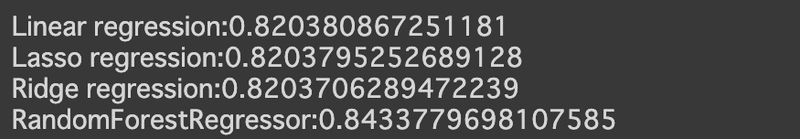
それぞれ0.82以上とそれなりに高い予測精度が見られます。
3.予測値の精度確認
次に北海道のLPガス販売数量の予測値と実測値の精度を見てみます。
2013年1月〜2021年8月までのデータの内、前半80%(2013年1月〜2019年10月まで)の気温とLPガス販売数量を訓練データとして使用し、2019年11月〜2021年8月のLPガス販売数量の実測値と予測値を比較します。
実測値と予測値には、高い精度がグラフから見て取れます。
#予測値 (testデータ)は後半20%を使用しているので、後半20% に月を合わせる
import math
predict= model.predict(test_X)
df_temp_month= df_temp["月"]
df_temp_date= df_temp_month[math.floor(len(df_temp_month)*0.8):]
plt.plot(df_temp_date,predict)
plt.plot(df_temp_date,test_y)
plt.xticks([0, 3, 6, 9, 12, 15, 18, 21], ["19/11","20/2","20/5","20/8","20/11","21/2","21/5","21/8"])
plt.show()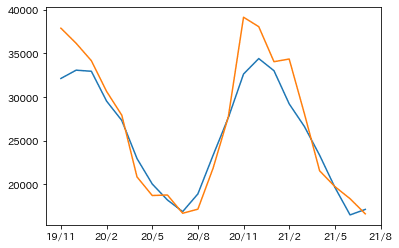
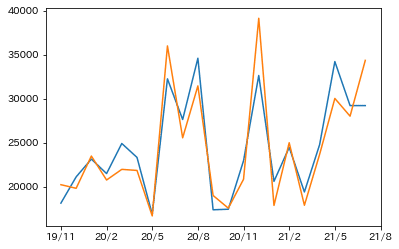
次に沖縄県のLPガス販売数量の予測値と実測値をグラフで見てみます。
こちらも高い精度が見られました。
終わりに
今回は、気温とLPガス販売数量の関係性を調べるとともに、過去のデータ(2013月1月〜2019年10月)からLPガス販売数量の予測が精度良くできるかどうかを検証しました。
実際には全都道府県のデータを取得し検証したため、都道府県別の相関係数の違いから考えられる考察(都心部はLPガスよりも都市ガス使用世帯の方が多いため相関が低いなど)を検証できれば良かったかなと思いました。
また、月毎・地域毎の世帯数のデータなどを入手出来れば、気温だけではなく、より相関の高い説明変数があるかどうかを検証出来たと思います。
今後は、社内にある実際のデータを使用し、販売数量や売上高の予測を行うことにより、経営業務の効率化や精度向上に努めたいと思います。
■参考にしたページ
・GoogleColaboratoryでGoogleDriveのファイルにアクセスする方法。
https://blog.kikagaku.co.jp/google-colab-drive-mount
・Matplotlibで2軸のグラフを描く方法。
https://datumstudio.jp/blog/matplotlib-2%E8%BB%B8%E3%82%B0%E3%83%A9%E3%83%95%E3%81%AE%E6%9B%B8%E3%81%8D%E6%96%B9/
・グラフのX軸目盛り文字が潰れているのを対策する方法。
https://chayarokurokuro.hatenablog.com/entry/2021/05/22/184944
この記事が気に入ったらサポートをしてみませんか?