「特許俯瞰(マップ)分析」を考える

✖️本記事は有料記事です。◯無料にしました。
注1:この記事は個人的な考え・意見をまとめたものです。
注2:本記事では最近は流行っている俯瞰分析を自己流で解釈し、現在の分析ツールの技術動向への考えと自作したPythonプログラムのコードを掲載します。コードを起因とする問題に一切の責任は追えません。
1. 俯瞰(マップ)分析とは・その意義
IPランドスケープの話題が近年増えてきたが、その引き合いに出されていることが多いのは特許俯瞰分析(解析)(ここから俯瞰分析と述べる)である。
俯瞰分析とは、特許文書をベクトル化→2次元で表示し、文書間の関係性を知ることで、特許情報の俯瞰を行う分析である。
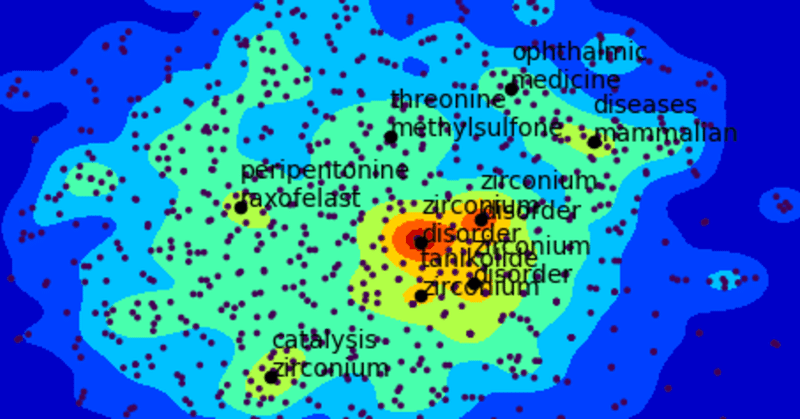
例を挙げる下記URLや下図のようなマップで特許情報を俯瞰するようなものである。
・https://www.jpo.go.jp/support/general/ip-intelligence/intro-17.html
引用) Patent Integration 特許庁HPより

図1:不斉反応に関する特許の抄録を用いた俯瞰分析結果
俯瞰分析の意義とはなんだろうか。研究開発戦略や製品開発戦略策定の足がかりにすること・新たなイノベーションを生むこと・ブルーオーシャンの探索が俯瞰分析の大きなゴールであろう。
私(IPランドスケープを遂行する役職の目線から)はそれに加えて、
「経営陣に特許情報のイメージを植え付け・興味を持たせる・その後の提案や判断をスムーズにさせる潤滑油」
としての役割(意義)を持つと考える。
私が経営戦略の提案フローを考えると、(柔軟に形態を変える必要があるが、基盤として私が持っているフローである)下図のようになる。

図2:経営戦略の提案フロー(簡略化版)
図2のように本腰をいれて分析を行い、戦略を提案をするまでに(プレ分析から現状分析に遷移するプロセス)、何もしないとかなりのエネルギー(精神)とコスト(時間)を使う必要があることが多くはないだろうか?何かを提案しようとして、経営者(上司)に話しても、イメージがわかずにうやむやになることがあるのではないだろうか?私は俯瞰分析を、これらの問題を解消するためのツールとして考えている。
個人的意見だが、この分析から、大きな目標でもある「新たなイノベーション」が直接生まれることはほとんどない、「ブルーオーシャンの探索」はほとんどできないと考えている(誤解して欲しくないので、追記しておくが、「できないとは言っていない」)。
「ブルーオーシャンの探索」に関しては、例えば、図1の特許文書のベクトルが寄り集まっていないところは新規テーマがある可能性がある強調して言われていることがある。しかし、当手法はその文書の書き方などによって左右されやすい(ここの解説は後述する)。抄録などの書き方によって2次元マップ上のベクトルの分散状態が大きく変わる。そのため、ベクトルの集まっていないところ(クラスターになっていないところ)が新規テーマが眠っている可能性があると簡単に言えないと考えている。(ただ、この文章を正規化しベクトルを観ることができれば、話は別と考えている。)
追記 ここで一番言いたいのは、上記のような可能性が大半を占めると思うので、俯瞰分析をした際に、ブルーオーシャンと思う特許は絶対読むべきで、例えば、経営陣に「ブルーオーシャンかもしれないですねぇ」というのはナンセンスであるということである。
2. 分析ツールの技術動向
特許情報データベースを売り出している企業が多くこの俯瞰分析機能を取り入れている。俯瞰分析の大まかな手順としては、
①特許文書を形態素解析する。
②形態素解析した文書をベクトル化する。(例:tf-idf)
③②の多次元ベクトルを2次元に次元削減する。
④ヒートマップで表現 / ベクトルの寄り集まり具合を表現するために2次元マップ上で密度計算を行う(④は各社色々な手法を使っているように見受けられる)
という流れだ、各社ベクトル化手法や2次元削減手法が異なるように思われる。細かい手法は各社隠しているようで、完全に真似ができない状況である。概要が知りたい方は下記(俯瞰解析ソフトの比較)を参考にされたい。
・俯瞰解析ソフトの比較(PLASDOC協議会)
ここからは代表ツールのHPの紹介とその大きな特徴のみ紹介する。
Derwent Inovation社製「Themscape」
・tf-idfでベクトル化を行なっている。
・次元削減手法は不明
・ストップワード(解析に使いたくないキーワード、全文検索などで、あまりに一般的であるため、単独では検索から除外される単語)の設定が可能である。
Valuenex社製「DocRader」
・tf-idfでベクトル化を行なっている。
・文書間の類似度をベクトル計算に反映している。
・ベクトル化後、多次元尺度構成法(MDS)を行い2次元マッピング化を行なっている。
・ストップワードの設定はできない。
Patent Integration
・技術詳細不明
・ユーザー登録不要で、無料で利用可能。
・有料(14日間トライアルあり)
・ストップワード の設定ができない。
Questel 社製「Orbit」
・技術詳細不明
・クラスター(特許文書ベクトルの集まり)の名前変更が可能。
どれも有償のツールは高いのが難点。金銭的に使えなくなる状況が発生すると困る。特にプレゼンの作り方を変えないといけなくなる可能性がある。
今回はそのようなことが起こらないように、簡単に自分でできるようになるべきだと考えてプログラムを作成した。
3. 自作プログラムのコードと解説
さて、今回の本題である自作プログラムのコード紹介と解説である。
今回のプログラムのフローを下図に示した。

図3:自作プログラムのフロー
簡単に流れを説明すると、
①特許のテキストデータを形態素解析で分かち書き
②①の結果に対して、tf-idfで文書のベクトル化
③tf-idfで2次元に次元削減
④文書ベクトルの寄り集まり方を表現するために、カーネル密度推定でベクトルの密度計算
⑤ベクトルの密度がピークになっているところの高頻出キーワードを抽出する
といった流れである。
ここで、このフローに使われる技術の解説を行う。
形態素解析

図4:形態素解析とは
形態素解析とは自然言語をコンピューターが処理できるように、単語単位で文章を分ける手法である(図4に例を表記)。日本語だとMecab、英語だとnltkが形態素解析ツール(ライブラリー)として挙げられる。
tf-idf

図5:tf-idfとは①
tf-idfとは文書の中から、その文書の特徴語抽出する時に使う手法である。
ある文書である単語が出る確率(tf)とある単語が出る文書の頻度の逆数(idf)をかけた値をその文書のベクトルとして用いる。例として下図(図5)を示した。

図6:tf-idfとは②
t-SNE
t-SNEは次元削減手法の一つである。Kullback-Leibler divergence(KLD)をコスト関数として使い、多次元ベクトルを低次元に合わせていくイメージである。詳細は私が説明するよりも下記HPを参考にされたい。これはとてもわかりやすい。
カーネル密度推定
ベクトル間の密度を推定する手法。図1で示すようにヒートマップを表示するために使用した技術である。下記を参考にプログラムを作成した。
コードとその解説
・ライブラリーのインポート
必要なライブラリーはインストールしてほしい。anacondaを入れている場合は、genismとscipyくらいを入れれば問題ないと思われる。
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import numpy as np
from gensim.models import KeyedVectors
from sklearn.manifold import TSNE
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import matplotlib.colors
import matplotlib.cm as cm
from scipy.stats import gaussian_kde
from scipy.ndimage.filters import maximum_filter
import math・密度計算後のピーク算出関数
def detect_peaks(image, filter_size=3, order=0.15):
local_max = maximum_filter(image, footprint=np.ones((filter_size, filter_size)), mode='constant')
detected_peaks = np.ma.array(image, mask=~(image == local_max))
# 小さいピーク値を排除(最大ピーク値のorder倍以下のピークは排除)
temp = np.ma.array(detected_peaks, mask=~(detected_peaks >= detected_peaks.max() * order))
peaks_index = np.where((temp.mask != True))
return peaks_index下記HPを参考にした。
◯imageにはガウス密度関数で計算された2次元データ(2次元の密度の高さを示す配列)が入っている。orderの値は任意で、値を下げるほどピークと認識する閾値が下がる。
・ピークの最近傍のベクトルを求めるための関数
def func_search_neighbourhood(embs, p0,p01):
L = np.array([])
for i in range(embs.shape[0]):
norm = np.sqrt( (embs[i,0] - p0)*(embs[i,0] - p0) + (embs[i,1] - p01)*(embs[i,1] - p01) )
L = np.append(L, norm)
return np.argmin(L)
◯求めたピークの位置((x,y)=(p0,p1))から最も値が近い値のベクトルをL2ノルムで算出して求める関数。下記HPを参考にした。
・メイン関数(抄録データの指定・ストップワードの指定)
def main():
data = pd.read_excel(r'./data.xlsx')
x_data = np.array(list(data["word"]))
assay = "Class"
le = LabelEncoder()#assay2num
le = le.fit(data[assay])
data[assay] = le.transform(data[assay])
y_data = data[assay].values.reshape(-1,1)
data1= pd.read_excel(r'./stopword.xlsx')
stoplist = list(np.array(list(data1["Stop"])))◯data.xlsxは抄録データおよびユーザーが指定したい分類を入力する(図6)。(分類は適当にしてほしい。指定しないとエラーが出る。)

図6:data.xlsx
また、stopwordの指定も行なっている(図7)。

図7:stop.xlsx
・メイン関数(tf-idfとt-sneの指定)
#main ()
#tf -idf
vectorizer = TfidfVectorizer(max_df=0.7,min_df=0.0,use_idf=True, token_pattern=u'(?u)\\b\\w+\\b',stop_words=stoplist)
vecs = vectorizer.fit_transform(x_data)
#t_sne
tsne = TSNE(random_state=0, n_iter=15000, metric='cosine')
embs = tsne.fit_transform(vecs.toarray())◯TfidfVectorizerのmax_dfとmin_dfはtf-idfの値の範囲を指定でき、その範囲外だと切り捨てとなる。
◯t-SNEのrandom_stateを指定することでは、サンプリングの仕方を固定することができる。これをしないとプログラムを試行するごとに俯瞰分析の結果が異なることとなる。
・メイン関数(ガウス密度関数の計算を行う範囲の指定)
#main ()
#ガウス密度計算
x = math.ceil(max((embs[:,0])))+1
x1 = math.ceil(min((embs[:,0])))-1
y = math.ceil(max((embs[:,1])))+1
y1 = math.ceil(min((embs[:,1])))-1
if x1<0:
x1=-x1
if y1<0:
y1=-y1
xx,yy = np.mgrid[-x1:x:1,-y1:y:1]
positions = np.vstack([xx.ravel(),yy.ravel()])
value = np.vstack([embs[:,0],embs[:,1]])◯ここでは、次元削減で求めたベクトルの最大・最小を求めた図示する範囲を決定している。その範囲でガウス密度計算を行う指定を行なっている。
・メイン関数(ガウス密度関数の計算・matplotを用いたベクトルの図への出力)
kernel = gaussian_kde(value, bw_method='silverman')
f = np.reshape(kernel(positions).T, xx.shape)
maxid1=detect_peaks(f)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.contourf(xx,yy,f, cmap=cm.jet)
plt.scatter(embs[:, 0], embs[:, 1], c=y_data,s=3)
words = vectorizer.get_feature_names()◯ここでは、ガウス密度関数の計算を行い、求めた2次元上のベクトルの密度具合をを用いてdetect_peaks関数(上で説明)でピーク算出を行なっている。
その後、そのピークを反映したヒートマップと次元削減したベクトルを図に出力している。
・メイン関数(ピーク最近傍ベクトルの最頻出ワードの出力)
for i in range(len(maxid1[0])):
plt.scatter(maxid1[0][i]-abs(x1), maxid1[1][i]-abs(y1), color='black',s=20)
n1=func_search_neighbourhood(embs,maxid1[0][i]-abs(x1),maxid1[1][i]-abs(y1))
w_id1=np.argsort(vecs[n1].toarray())[-1][-1]
w_id2=np.argsort(vecs[n1].toarray())[-1][-2]
plt.text(maxid1[0][i]-abs(x1), maxid1[1][i]-abs(y1), words[w_id1]+"\n"+words[w_id2])
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
if __name__=='__main__':
main()◯func_search_neighbourhood関数を用いて、求めたピークの最近傍のベクトルを求めている。その後、そのベクトルの最頻出ワード(1位・2位)を図に出力している。
出力は図1のようなものになる。
プログラムの解説は以上である。細かい内容はコメントをしていただければと思う。
4. まとめと今後の展望
今回のまとめとして
・俯瞰分析は経営陣に特許情報のイメージを植え付け・興味を持たせる・その後の提案や判断をスムーズにさせる潤滑油的な役割を持つと考える
・各社様々な技術を用い、独自性をだして俯瞰分析ツールを作り上げている。
・ネットにある情報のみで、独自に簡単な俯瞰分析プログラムを作成してみた
今後の展望としては、今回自作したプログラムはtf-idfでベクトル化したものを次元削減しただけのものであった。今後、これに加えDocRaderのような文書間の類似度もベクトルに反映する手法のようなものも取り入れたいと思っている。例えば、IPC、FI、CPCを反映させ、類似した分類の文書は寄りあつまるといったベクトル化手法を考えている。プログラムを作成することができれば、またnoteにまとめたい。
5. 参考資料
・特許情報検索の現状と今後の可能性(戸田 敬一)
https://japio.or.jp/00yearbook/files/2019book/19_2_01.pdf
・知財インテリジェンスサービスの紹介(特許庁)
https://www.jpo.go.jp/support/general/ip-intelligence/index.html
・形態素解析とは?おすすめの5大解析ツールや実際の応用例を紹介
https://udemy.benesse.co.jp/ai/morphological-analysis.html
・特許の文書構成と分類情報を用いた類似特許検索方式の精度評価
https://www.japio.or.jp/00yearbook/files/2007book/07_2_14.pdf
・TF-IDF
https://qiita.com/AwaJ/items/5937665d5a4152cc24cf
・Tf-idfベクトルってなんだ?
https://qiita.com/masatojames/items/5b0a140b1ecbdd0396e1
この記事が気に入ったらサポートをしてみませんか?