
文字列を反転させたい

こんにちは。徒然なるままにTweetを眺めていたら、Tanakaさんがこのようなことを呟いていました。
そういやRustのStringにreverseメソッドないなと思ったけど、まあよく考えたらUTF-8で文字逆転させるとか地獄のような話になるしそもそも長さが変わるケースとかあったりしそうで怖いわな・・・(´・_・`)
— Hideyuki Tanaka (@tanakh) May 1, 2021
背景等はよくわからないですが、文字列の反転というのは確かに難しい問題ですし、どう難しいのかというのを、ちょっと真面目に考えて解説してみました。というノートです。
本文での表記について
これから文字とそのバイト表現の話をしていきます。文字のエンコードの方式で同じ数値でも色々意味が分かれてしまいますので、本文では以下のように表記することにします。
Unicodeコードポイント(以下、単にコードポイント)は\UXXXXという形で表記します。コードポイントとはざっくり言うと、Unicodeという世界共通規格が「この文字はこの番号」っという具合に決めている数字のことです。例えば、「H」のコードポイントの値は0x48であり\U0048と表記、「あ」のコードポイントの値は0x3042で、\U3042と表記します。
UTF-8が何なのかは後で説明しますが、UTF-8はバイト列で表現できます。0x00から0xFFの値の列ですね。ここでは、16進数でエスケープした文字列表現で一般的に使われている"\xXX"という表記を用います。例えば「H」はUTF-8では0x48とエンコードされますので、\x48と表記します。ほかにも、例えば「あ」はUTF-8では3バイトで表現され、順に0xE3、0x81、0x82となります。ここでは先程の記法を用いて\xE3\x81\x82と表記します。
この表記と実際の文字列との相互変換はこのページを用いると便利です。
「文字列を反転させる」とは?
まずは話を始めるために、「文字列を反転させる」という意味を考えてみましょう。ここでは簡単に「反転させた文字列とは、逆から読むと、もとの文字列と同じ意味になる」ものとしましょう。例えば、「Hello, World.」の場合、「.dlroW ,olleH」となり、右から一文字づつ追っていけば読むことができます。同様に日本語でも「こんにちは、」を反転させたものは「、はちにんこ」であるとします。逆に言うと、読めないようなものは反転させた文字列とはみなさないとしましょう。例えば、文字化けした文字列や、「あ」を反転した結果「い」になった、のような全く違う文字になるなどです。
UTF-8とは
文字列とは御存知の通り、メモリ上に格納されたデータ列です。ただしこのデータ列がどのような規則に従って文字を格納しているかは、言語や環境、仕様等によって様々です。ここでは、もとのTanakaさんのTweetのとおりUTF-8であるとしましょう。UTF-8の特徴は、1バイト=8ビットを一つの単位として、コードポイントをエンコードするところにあります。UTF-8の具体的な仕様はWikipedai等に譲るとして、ここでは以下のことが重要になりますので押さえておいてください。
UTF-8の1バイト目は長さ情報が入ってる
UTF-8は可変長です。つまり、1コードポイントを表すのに必要なバイト数がコードポイントによって違うのです。例えば、英語だと1バイト、日本語だと大体3バイト必要で、絵文字などだと4バイト必要なものもあります。ではバイト列を読む時、何バイト読めばよいのでしょうか?読むべきバイト数は1バイト目に書いてあります。つまり、UTF-8デコーダは最初の1文字目を読んで、何バイト読めばよいかを判断して、それらを使って、コードポイントを復元します。具体例として、\xE3\x81\x84\D7\x90というUTF-8のバイト列を見てみましょう。
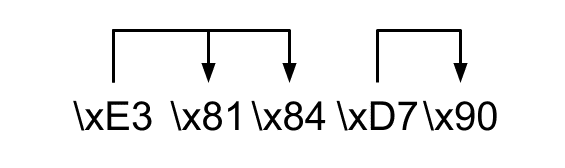
UTF-8を処理する際にはまず、1文字目を見ます。今回それは\xE3であり、これは後ろの2バイトを使ってデコードすることを要求しています。つまり、\xE3と\x81と\x84を利用してデコードします。そして、デコードが終わったらデコーダは次の文字\xD7を見つけます。\xD7は後続の1バイトを使用するので、ここで読むのは\xD7と\x90のみです。なぜ、\xE3は後続の2バイト、\xD7は後続の1バイトを使用するのかは、WikipediaのUTF-8の仕様を御覧ください。
英語と数字はUTF-8でも1バイト(ASCII互換)
次に重要なこととして、もし英語と数字のみで構成される文章を、UTF-8形式で保存した場合、それらはすべて1バイトで表されます。例えば「Hello, World」の文字列を構成するすべての文字はUTF-8では1バイトで表現されます。(注:雑に英語と数字と言いましたが、厳密にはASCIIコード領域の文字だけです。漢数字とかは1バイトじゃないですからね!)
さて、文字列を反転させる準備はできました。さっそく反転させていきましょう。
案1. バイト単位で反転させてみよう
まず、一番シンプルな解決策を考えてみましょう。文字列を文字と思わず、バイト列と思って反転させてみましょう。何が起きるでしょうか?
まず、英文を反転させてみましょう。「Hello, World.」はちょっと長いので、ここでは「ABC」を反転させてみましょう。この文字列のUTF-8でのバイト列はこのようになります。
"ABC" = \x41\x42\x43わかりやすいですね。Aが\x41でBとCはこれらから1づつズレた値になっています。さてこれをバイト単位で反転させます。バイト単位で反転させるとは、すなわち、\x41\x42\x43となっている列を逆にします。
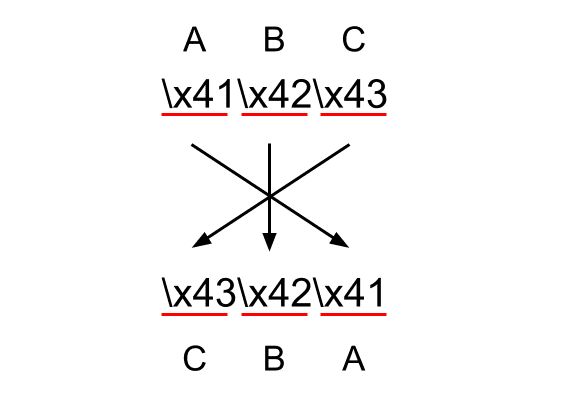
おぉ、きちんと「CBA」となりました。
では、この反転方法で問題はないのでしょうか?いいえ、問題おおありです。先程見たようにUTF-8は複数のバイトで文字を表現します。今見てきた例は、すべての文字が1バイトで表現可能だったので、たまたまうまく行ったのです。具体的に見ていきましょう。「あい」という文字列をバイト単位で反転させることを考えてみましょう。「あい」のUTF-8でのバイト列はこのようになります。
"あい" = \xE3\x81\x82\xE3\x81\x84これを、先程と同様に、バイト単位、すなわち\xXXの単位で反転させてみましょう。そうすると以下のバイト列が得られます。
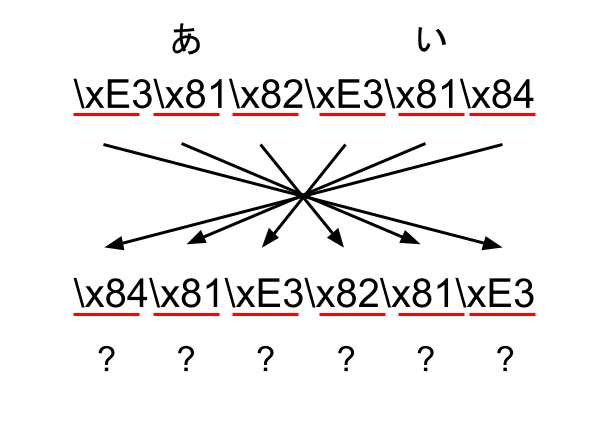
さて、このバイト列はなんの文字を表すのでしょうか?答えは、何も表しません。なぜならこのバイト列は正しいUTF-8の規則に則っていないからです。先程見てきたように、UTF-8の1バイト目は後ろに続くバイト数が格納されていると説明しました。この場合は元の文字列の1バイト目、\xE3に該当していて、この中に後ろに何バイト読まないといけないかが情報として入っています。この場合は2バイトですね。ですが、反転させたバイト列を見てください。反転されてしまった結果、最初の文字は\x84です。これでは一体このあと何バイト読めばよいかわからないですね。つまり、UTF-8として正しくないのです。
案2. コードポイント単位で反転させる
っというわけで、バイト単位での反転は(ASCII範囲の)英語と数字であればうまく動きますが、それ以外では壊れた文字列を出力する事がわかりました。では、どうやったら、「あい」を反転させて「いあ」を出力させることができるでしょうか?
バイト列ではうまく行かなかったので、次に考えるべきはUTF-8がエンコードしている元の情報、コードポイントまで戻って、コードポイント単位で反転させることを考えてみましょう。「あい」はコードポイント列は「\U3042\U3044」です。
"あい" = \xE3\x81\x82\xE3\x81\x84 = \U3042\U3044では、このコードポイント単位で反転してみましょう。「\U3042\U3044」を反転させると「\U3044\U3042」となります。そしてそれをUTF-8でエンコードしたものが\xE3\x81\x84\xE3\x81\x82となり、これが求めたかった結果となります。
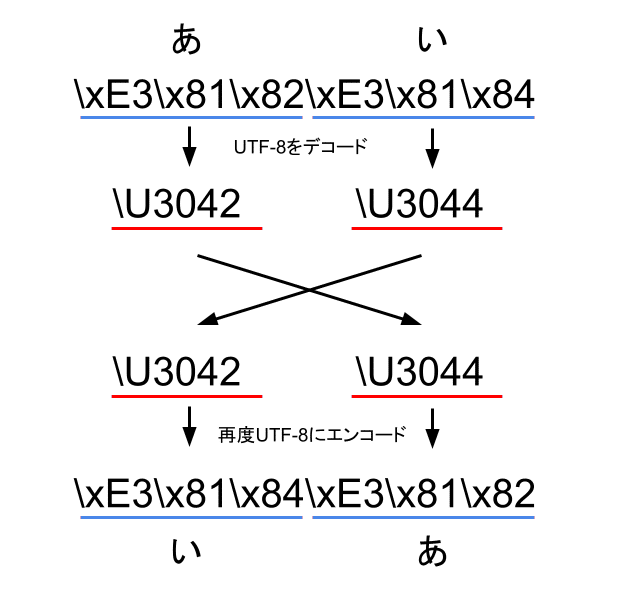
\U3044\U3042 = "いあ" = \xE3\x81\x84\xE3\x81\x82これで、日本語のようなUTF-8で複数バイトを使用するような文字でも正しく反転させることができるようになりました。
これでめでたし、めでたし・・・だとよかったのですが、実は、まだうまく動かない奴らがいるんです。次にそんな文字列を見ていきましょう。
案3. グラフィムクラスター単位での反転
前節でコードポイント単位で反転すれば、日本語では正しく反転してくれることを紹介しました。ここからは、コードポイントを反転させてもうまく行かない例を紹介します。
例1. 前の文字を修飾する文字
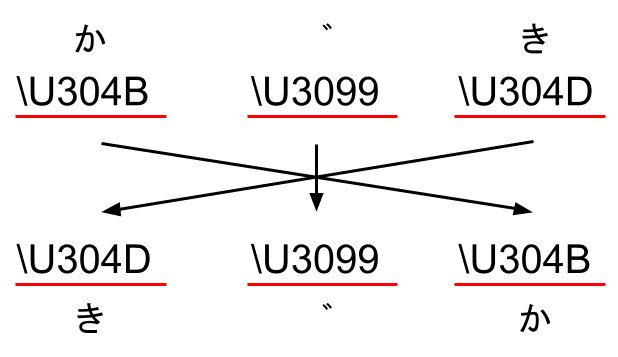
世界には、文字に文字を付け加えて、新たな文字を作る文化圏があります。あります、というよりはむしろ大多数がそうです。日本語も例外ではありません。「が」は「か」という文字に濁点を付け加えてできる新しい文字です。Unicodeには「が」を表現するのに二通りのやりかたがあります。「が」という一文字を表す「\U304C」を使用するやりかたと、「か」を表す「\U304B」と濁点を表す「\U3099」を別々に表記するやり方、つまり「\U304B\U3099」で「が」を表す方法があります。後者のコードポイント列を入れ替えると、濁点が先に来てしまいます。たとえば、「がき」という文字を反転させると、「きが」になってほしいところで、「ぎか」という文字になってしまします。
例2. 絵文字
絵文字は複数のコードポイントを組み合わせて一つの絵文字を表現する仕組みがあります。例えば、ボートを漕いでいる絵文字の後ろに、肌の色を表す絵文字、加えて女性の性別マークを追加することで、ボートを漕いでいる女性の絵文字になったりします。

これもある種、先程見たような修飾文字と見ることができるので、このコードポイントの順序が入れ替わると、意図しない文字が出力されてしまうことがわかっていただけるかと思います。これに関連して面白い例を一つ紹介します。絵文字には多数の国旗が収録されていますが、この国旗はちょっと変わった方法で表現されています。Unicodeは国旗に使用する専用のアルファベット、「A」から「Z」までを用意していて、その2つの組み合わせで国旗を表しています。例えば、日本の場合は国コード「JP」を、この特殊なアルファベット「J」と「P」を用いて表現します。

ここで、感の良い方は気づいたかもしれません。そうです、ひっくり返すと別の国の文字コードになる組み合わせがあるのです。
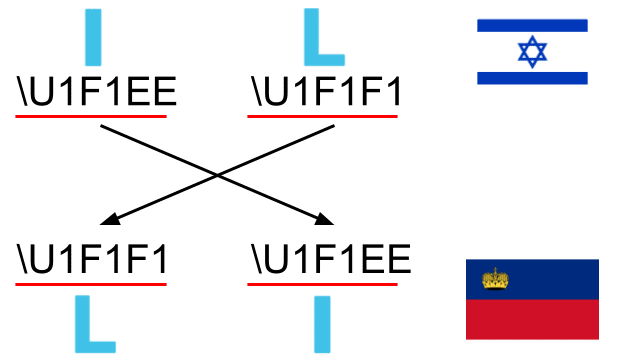
これは一例なのですが、「IL」はイスラエルを表します。他方で、「LI」はリヒテンシュタインを表します。つまりイスラエルの国旗をコードポイント単位で反転させると、なぜかリヒテンシュタイン公国の国旗になってしまいます。
解決策
では、このような問題に対してどうすればよいのでしょうか?答えはもうこの説のタイトルになっていますが、「グラフィムクラスター」を使います。グラフィムクラスターとは、ざっくりと言うと「人間が考える1文字」に相当します。たとえば、先程の例で見た通り、「が」を人は1文字だと考えますし、国旗も1文字だと考えるでしょう。つまり、このグラフィムクラスター単位で反転させてあげれば良さそうです。
「どうやってそんな1文字を計算するのか?」それには非常にめんどくさい説明と、Unicodeの文字データベースが必要なので、ここでは説明を割愛します。詳しく知りたい方は、こちらを御覧ください。もし普段プログラミング言語としてJavaをお使いでしたら、BreakIteratorのCharInstanceを利用すると、このグラフィムクラスターの分割が可能です。

図のように、「がき」という文字列にグラフィムクラスターのルールを適用すると、「か」と濁点は同一のクラスターに属することがわかります。ですので、反転させる場合はこのクラスターの中の順序を変更しないように、グラフィムクラスター単位で反転させます。図中の紫色の線はグラフィムクラスターを表しています。
めでたしめでたし?
さて、日本語に加えて、絵文字や修飾文字をも反転させることができました。では、これで文字列の反転問題は全部解けたのでしょうか?いいえ、じつはまだまだ問題が起こる場合があります。例えばアラビア語のように、文字の字形が単語中の位置によって変わる言語が存在します。このような言語の場合、語頭の文字が反転の結果語尾に移動してしまい、字形が変わってしまいます。また、おなじくアラビア語のような、右から左に書く言語(Right-To-Left,、RTLと略す)でも問題が起きるでしょう。UnicodeはRTLと英語のような左から右に書く言語(Light-to-Right、LTRと略す)を入り混ぜて書くための仕組み、BiDirectional Algorithmを策定しています。その処理するために、いくつか特殊な制御文字が存在しますが、その多くは「この文字以降はRTLとして扱う」みたいな処理になっています。つまり、文字を反転させてしまった結果、RTLとして扱う領域が反対になってしまうわけです。
正直、これらの問題を簡単に解決する方法を私はすぐに思いつきませんし、そもそも、何が「反転した文字列」として正しいのかすらわかりません。もう、この辺になってくると「なぜ文字列を反転させたいのか?」という問題に立ち返って、必要な処理をその都度考えたほうが良いでしょう。例えば、単にアルゴリズムの都合上、逆から走査する代わりに文字列を反転させる前処理がしたいだけなら、グラフィムクラスター単位の反転で十分ですからね。
おわりに
文字列の反転って聞くと、誰もがプログラミングの習得するときに一度は書いたことがあるプログラムだと思います。そんなシンプルな走査でも、言語という、非常に複雑な世界に適用しようとすると、難しい問題と複雑な処理が必要になります。今回はTanakaさんのTweetから着想を得て、文字列反転という題材を扱いましたが、実際には、文字列の反転が国際化対応する際に問題になるケースは少ないと思います。ですが、似たような問題は文字列マッチング問題などを解こうと思うと遭遇するでしょう。私はかれこれ10年ほど文字を題材とした仕事をしていますが、まだまだ未開の地をアドベンチャーしている感覚でいます。みなさまも機会がありましたら文字のジャングルへアドベンチャーして行ってみてください。きっと愉快な仲間たちがいっぱい生息してると思います。
この記事が気に入ったらサポートをしてみませんか?