
検索革命: 大規模言語モデル時代の新しい検索戦略

今回は、Theory Venturesが提供するLLM(大規模言語モデル)とその検索システムに関する解説です。検索はコンピュータサイエンスで最も難しい技術的課題の一つです。Google、Amazon、Instagramなど、わずかな製品だけがそれをうまく行っています。しかし、最近のLLMの爆発的な普及に伴い、あらゆるLLM企業は、製品にワールドクラスの検索機能を組み込む必要があります。この新たなAI企業の波は、検索をどのように解決するのでしょうか?LLMの目標は「推論」であり、膨大なトレーニングは「世界を理解する」ためであって「世界を記憶する」ためではありません。巨大的なコンテキストはモデルに辞書を背負わせるようなものであり、リトリーバル(検索)はモデルが辞書を引けるようにすることです。この分野には新たなチャンスが広がっています。
Theory Venturesの原文:https://www.linkedin.com/pulse/every-llm-company-search-hard-future-retrieval-systems-7zigc/
LLMシステムにおける検索の重要性
RAGシステムの役割: Retrieval-augmented generation(RAG)システムは、LLMに対してクエリに回答するための関連情報を提供します。これは、LLMが実際の情報に基づいて生成を行うのを助けます。
文脈の重要性: 新しいLLMは長いコンテキストウィンドウを持ち、大量の入力を一度に処理できます。しかし、複数のバージョンの類似文書があるビジネスや、セキュリティ上の理由で役割やコンテキストに基づくアクセス制御が必要な場合、検索の重要性は消えません。
セマンティック類似検索の限界
単純だが効果が限定的: セマンティック類似検索は、データをチャンクに分割し、テキスト埋め込みモデルを使用してベクトル化し、クエリに最も近いベクトルを持つチャンクを取得します。しかし、このアプローチは、ユーザーの意図を完全に捉えられない場合があります。
埋め込みモデルの依存性: 一般的なテキスト埋め込みモデルは、特定のドメインではうまく機能しないことがあります。
計算コスト: テキスト埋め込みの計算は高コストであり、リアルタイムデータの提供が難しくなります。
将来の検索システムの展望
多様なアプローチの必要性: 現在の検索システムは、意味的な類似性だけでなく、ユーザーの行動や人気度に基づいた予測も取り入れています。例えば、YouTubeやAmazonの検索システムは、ユーザーの視聴履歴や購入履歴を考慮に入れています。
より複雑なシステムへ: GoogleのPageRankアルゴリズムのように、単純なアルゴリズムから始まったシステムも、現在は複雑な多面的なアプローチを取るようになっています。LLMのRAGシステムも同様に進化すると予測されます。
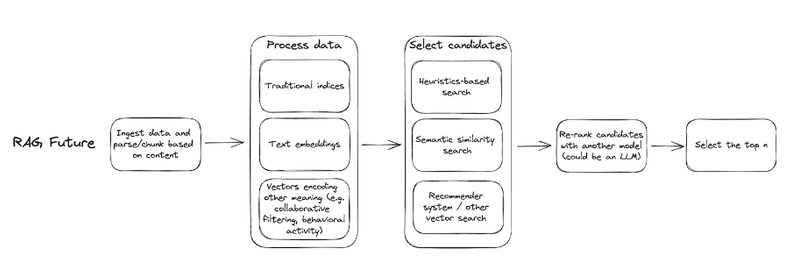
企業にとってのインパクト
コアコンピテンシーの構築: ほとんどの企業は、独自の検索システムを構築し、それを競争力の源泉とするでしょう。これには、特定のアプリケーションに合わせたインフラストラクチャの新しいセットが必要です。
ツーリングの向上: 新しい検索システムの構築には、さまざまな種類のベクトルを生成、操作、および使用するためのツールが必要です。例えば、Superlinkedはこのツールを構築しています。
将来的なスタックの統合
インフラストラクチャプロバイダーの拡張: 既存のインフラストラクチャプロバイダーが、より広範なスタックをカバーするようにオファリングを拡張する可能性があります。
「サービスとしての検索」の台頭: 特定のアプリケーションやモダリティに特化したプロダクト化された「検索サービス」としての提供が増えるでしょう。例えば、eコマースウェブサイト向けやチャットアプリケーション向けの検索システムなどです。
結論
検索システムは、LLMアプリケーションの能力に劇的な影響を与えます。これらのシステムは、効果的なメモリ、応答品質、信頼性、性能/レイテンシに影響を与えるため、企業にとってはコアコンピテンシーとなり得ます。将来の検索システムは、現在のLLMプロトタイプとは異なり、複雑で多面的なアプローチを取ることが予想されます。
この記事が気に入ったらサポートをしてみませんか?