どうせ2日で終わる日記-58-(KH Coderが面白い)【6/20-6/26】

最近めっきり暑くなりましたね、などという時候の挨拶が決して定型文などではない、ということを窓ガラスから伝わる熱気がありありと示してくれているだろう。
連日の猛暑日のせいで外に置いていたホースが溶けてベタベタになってしまった。
自然というものはここまで生命に牙をむくことができるのか、と思わず感心してしまうほどだ。
そんな気候なもんだから、元々雀の涙ほどしかなかった外出への意欲などはとっくに蒸発しており、ただ肉体を冷やすだけの装置と化した自室に籠るばかりだ。
しかし、残念ながら我々社会に生きる人間には相応の義務や責務があり、そのせいで外に引っ張り出されることがままある。せめてもの抵抗として太陽を睨んで威嚇を試みては、その眩い光に返り討ちにされて終わってしまうため、無力感と汗ばむシャツが背中に張り付く嫌な感覚を感じながらその運命に翻弄される他ない。
そういう訳で、その嫌な記憶に蹴りをつけ、またこれから訪れる連日の猛暑と対峙する覚悟を決めるためにも、今日も今日とて日記を書くこととする。
KH Coderが面白い
Twitterでもぼやいていたのだが、最近大学の関係で多変量解析を少々勉強する機会があった。
学部生時代にこれを学んだ記憶は無く、まあ本当に記憶がないだけで実際は学習したかもしれないが、ともかくこれが多変量解析に触れる初めての経験だった。
多変量解析が何であるか、というのはここでは詳細な解説は省く。僕でもある程度は独学できる程度にはインターネットに情報が転がっているのでそちらを参照して欲しい。
ただ一応簡単に一言で表すならば、多対多のデータセットに対しての解析手法の総称、というような意味で考えて貰えればそれでいいと思う。
これを勉強するにあたり久しく触れていなかった線形代数などを記憶の底から洗い出す過程があったことなど、様々な苦労があった訳だが、まあそれはここでは記述を省き、今回はその上でこの前たまたま見つけて面白いと思った多変量解析に関するソフトウェアを紹介、という名の使ってみた感想を述べる。
そのソフトというのが、このKH Coderだ。
多変量解析というのは実のところ多種多様なデータを解析することができ、気温や風速というようなデータから、テキスト、生物群集など、性質の解析も難しそうなデータも量的に解析することができる。
このKH Coderはテキストデータを解析することに特化しており、本来ならばRなどを使ってちまちまといじらなければならないような解析も、ボタン一つであら不思議、とても簡単にグラフィカルな結果を得ることができる。
しかも親切なことに、上記の公式サイトで簡単なチュートリアルも公開しており、初学者でも扱いやすい内容となっている(勿論データの解釈と扱いにはある程度理解が要求されるが)。
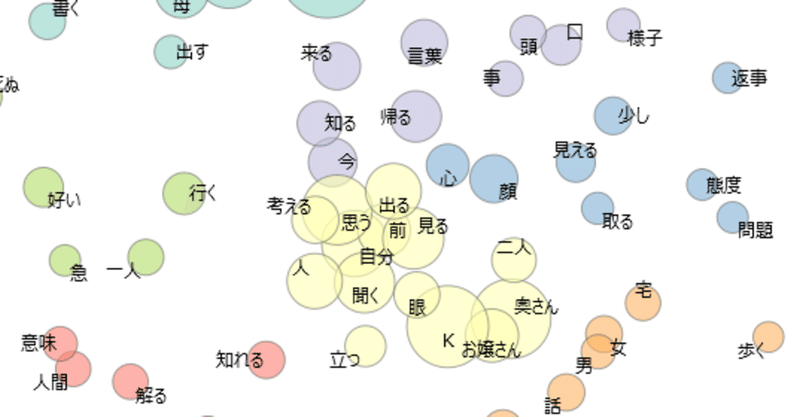
という訳でサンプルデータとして付属する夏目漱石の『こゝろ』を多次元尺度法で早速解析してみた。

多次元尺度法については下記のサイトなどが詳しいため、詳細なアルゴリズムなどについてはそちらを眺めて理解してもらいたい。
なお、上図には『こゝろ』に出てくる語の内、出現回数50回以上の単語のみが示されている。
多次元尺度法ではデータ同士が”似ている”ほど図上で近くにプロットされる。
テキスト分析においては、一般にJaccard係数などの在・不在データに基づく距離が計算に用いられる。つまり、今回で言えば同じ文中に出てきたものほど近くに配置されている。
また、それらは非計量データなため、多次元尺度法も非計量多次元尺度法を用いて解析を行う。
したがって、STRESS値を計算して実際の距離関係とプロットされた距離関係の一致具合を確かめる必要があるのだが、今回のプロットではSTRESS値が0.32程度であり、あまり良く当てはまっているとは言えない。
まあこればかりはデータの性質もあるだろうし、内部を見てないので分からないがRの解析をそのまま使っていることも考えられるので、仕方が無いと言える。
このプロットはKruscalの計算方法でJaccard係数に基づき計算したわけだが、これ以外にもsammonなど他のSTRESS値の計算方法やDiceやSimpsonなどの類似度を選べることができるので、お好みでデータの解析ができる。
ちなみにsammonでDiceを用いて計算した結果は下図のようになった。

なんだか丸く配置されてしまって少し心配になるが、stress値は0.16程度であり、まずまず当てはまっているといえるだろう。まあ単語自体がほぼ独立した因子であると考えると、文脈によって傾向は生じるものの、その中では均質を保っていると考えれば納得できないこともない。
ただ、ここで大事なのはそちらではなく、見て貰えばわかる通りプロットもクラスタリングの結果も大分異なっているということだ。「口」など、大きく位置が異なる単語もいくつか見受けられる。
実際に解析を行う際には、やはり手法選択の時点で細心の注意を払う必要がありそうだ。
……こうなるとR内部のアルゴリズムもやや気になる為、もしかしたらpython等で関数を自作した方が応用が効くかもしれない。
実はそんな時のためにも、このソフトは役立つ。
解析するのに面倒な前処理など、このソフトは自動で行ってくれるし、同士の活用なんかも考慮して一つにまとめてくれる。
さらに言うと、そこで得られた文中の出現数データなどもエクスポートからエクセル形式などで出力することができる。
なので、解析はしないがデータが欲しい、という場合でもこのソフトは非常に有用だ。
僕自身はテキスト分析などは行わないが、以前から興味があったので折に触れていじくりまわしてみた訳だが、存外便利で使い勝手が良く、驚いている。
多変量解析を実際に触れてみるいい教材になるかもしれない。
この日記でこうした技術的な話に触れるのはRen'py以来だろうか。
日記なので何となく日常に沿った話題を書かなければ、などとどこかで考えてしまっていたのだが、よく考えればこうした話題も僕の中の日常のため、別段これを控える筋合いも道理もない。
なので、今後は積極的にこうした少し専門的な話も、僕の備忘録を兼ねて書いていけたらと思っている。
それでは
この記事が気に入ったらサポートをしてみませんか?