
機械学習自動化ツール 〜分類編〜

初めまして。データ担当です。
今日から機械学習やデータ分析まわりの記事をかいていきますので、たまにみていただけると嬉しいです。
ということで早速機械学習の話題。
最近データサイエンティストの不足にともない、機械学習自動化ツールが流行っています。ということで当社でもプロトタイプを作ってみました。
対応しているのは教師あり学習で、
・分類 → カテゴリの予測
・回帰 → 数値の予測
とりあえずsklearnにあるアルゴリズムだけで対応してます。
では実際に分類の予測をしていきましょう(次回は回帰の予定)。

上のような学習データをCSVで用意しました。
このデータを学習させて、
身長、体重、年齢 → 性別
の予測をしていきたいと思います。
予測用のデータはこちら。

性別のところが抜けているのがわかります。
その他のデータも学習データとは違う値になっています。
この2つのCSVをインプットして予測させてみましょう。
結果がこちら。

かなり妥当な結果が得られていると思います。
それぞれの特徴量がどれだけ影響しているかもわかります。
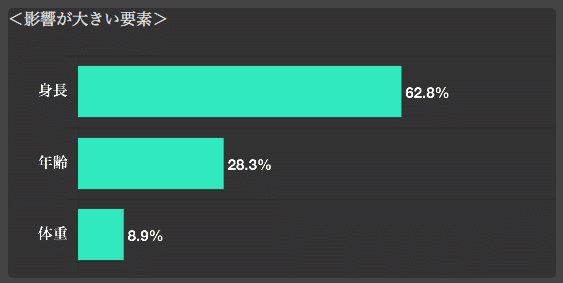
そして正解率です。

かなり高い数値が出ています。
最後に各アルゴリズムの比較結果です(上の結果はベストなアルゴリズムの結果)
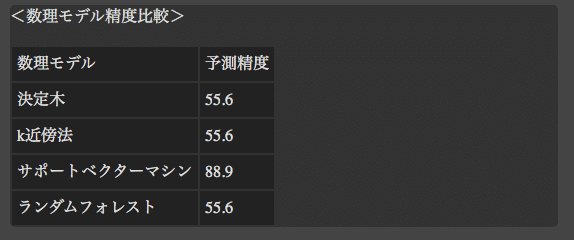
圧倒的にサポートベクターマシン(SVM)でした。
データによって適切なアルゴリズムは違います。
さらにいうとアルゴリズムを設定した上でハイパーパラメータのチューニングも行うことで高い精度が得られます。
それらは普通データサイエンティストがデータの形状から判断したり試してみたりするのですが、そのフローを自動化したのがこのツールです。
汎用性が高い分、オリジナルでアルゴリズムを組むよりは精度は劣るかもしれませんが、データをインプットするだけで予測できるので、手頃に機械学習ができるという大きな強みがあります。
この記事が気に入ったらサポートをしてみませんか?