
WSL2でSwallowを試してみる

自称「2023年12月現在オープンな大規模言語モデルの中で、日本語に関して最高性能を達成」したというSwallowを試してみます。試すモデルは tokyotech-llm/Swallow-7b-instruct-hf です。
使用するPCは、GALLERIA UL9C-R49(RTX 4090 laptop 16GB)、メモリは64GB、OSはWindows 11+WSL2です。
あ、わたしはタイガースファンです。
準備
環境のセットアップ
打ち込んでいきます。
python3 -m venv swallow
cd $_
source bin/activatepip install
pip install torch transformers accelerate
pip install sentencepiece
pip install protobufpip list
$ pip list
Package Version
------------------------ ----------
accelerate 0.25.0
certifi 2023.11.17
charset-normalizer 3.3.2
filelock 3.13.1
fsspec 2023.12.2
huggingface-hub 0.19.4
idna 3.6
Jinja2 3.1.2
MarkupSafe 2.1.3
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.2
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.3.101
nvidia-nvtx-cu12 12.1.105
packaging 23.2
pip 22.0.2
protobuf 4.25.1
psutil 5.9.7
PyYAML 6.0.1
regex 2023.10.3
requests 2.31.0
safetensors 0.4.1
sentencepiece 0.1.99
setuptools 59.6.0
sympy 1.12
tokenizers 0.15.0
torch 2.1.2
tqdm 4.66.1
transformers 4.36.2
triton 2.1.0
typing_extensions 4.9.0
urllib3 2.1.0コードの作成
README.mdを確認します。指示は日本語ですね。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
import time
llm = "tokyotech-llm/Swallow-7b-instruct-hf"
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
llm,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
llm,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
PROMPT_DICT = {
"prompt_input": (
"以下に、あるタスクを説明する指示があり、それに付随する入力が更なる文脈を提供しています。"
"リクエストを適切に完了するための回答を記述してください。\n\n### 入力:\n{input}\n\n",
"### 指示:\n{instruction}\n\n### 応答:"
),
"prompt_no_input": (
"以下に、あるタスクを説明する指示があります。"
"リクエストを適切に完了するための回答を記述してください。\n\n",
"### 指示:\n{instruction}\n\n### 応答:"
),
}
def build_prompt(user_query, chat_history=None):
template_name = ""
if chat_history:
template_name = "prompt_input"
else:
template_name = "prompt_no_input"
sys_prompt = PROMPT_DICT[template_name][0].format(input=chat_history)
prompt = PROMPT_DICT[template_name][1].format(instruction=user_query)
return sys_prompt, prompt
def q(user_query, chat_history=None):
start = time.process_time()
# 推論の実行
sys_prompt, prompt = build_prompt(user_query, chat_history)
#print("--- begin: sys_prompt ---")
#print(sys_prompt)
#print("--- begin: prompt ---")
#print(prompt)
#print("--- end: prompt ---")
input_ids = tokenizer.encode(
tokenizer.bos_token + sys_prompt + prompt,
add_special_tokens=False,
return_tensors="pt"
)
output_ids = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.99,
top_p=0.95,
streamer=streamer,
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
# print(output)
next_input = prompt + output
if chat_history:
next_input = chat_history + "\n\n" + next_input
end = time.process_time()
print(end - start)
return next_input
サンプルコードを参考にして、以下の点を修正しています。
「###入力」が「###指示」と「###応答」の間にあるとちょっとコーディングしにくいので、入力・指示・応答の順番に勝手に修正
繰返し呼び出すことを想定して、テンプレートを定義した変数 PROMPT_DICTをちょっとだけ修正
聞いてみよう - 7b
いつものドラえもんです。
>>> chat_history = q("ドラえもんとはなにか")ドラえもんは、未来からやってきたネコ型ロボットである。22世紀の日本では、ドラえもんが持つことのできる四次元ポケットのなかに 、さまざまな発明品やアイテムが入っている。ドラえもんはのび太をサポートし、のび太の人生を軌道に乗せるようにサポートする。の び太があらゆる問題に直面し、困難を抱える度に、ドラえもんはのび太をサポートし、助けてくれる。そのため、ドラえもんは、のび太 の母親の役割も果たす。
4.092888499999987
いい感じだし、速い。
続きを聞いてみましょう。
>>> chat_history = q("続きを教えてください", chat_history)ドラえもんは、のび太の人生に多大な影響を与え、のび太を常にサポートしている。ドラえもんは、のび太が困難に直面したとき、すぐ に助けに来てくれます。ドラえもんは、のび太が間違った道を選んだとき、いつでも正しい道に戻してくれる。ドラえもんは、のび太に 、人生で起こるすべての困難を経験し、克服し、楽しむように促しています。ドラえもんは、のび太の人生をより豊かで楽しいものにし てくれる存在である。
4.61318510000001
いいよ、とてもいいよ、ドラえもん。「###入力」の位置を変えているけれど大丈夫そう。
感動してきたので、さらに聞く。
>>> chat_history = q("続きを教えてください", chat_history)ドラえもんは、のび太が困難を乗り越え、成長する姿を見てきた。そして、ドラえもんは、のび太の人生におけるすべての瞬間に影響を 与え、サポートする。ドラえもんは、のび太に人生の多くの教訓を教えてくれます。ドラえもんは、のび太に、すべての人生は無限であ り、すべてのことを試す価値があることを教えています。ドラえもんの最大の功績は、のび太をより良い人間にし、のび太の人生をより 良いものにしたことで
4.858675099999999
感動した!
おまけ
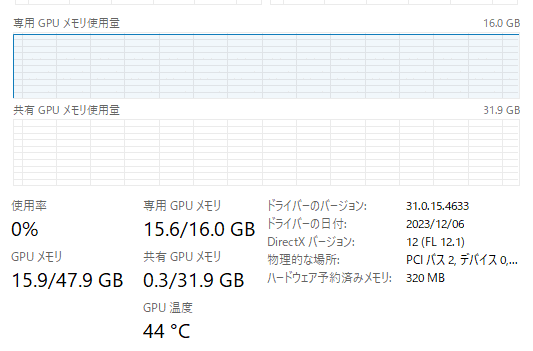
リソースの使用状況
GPU専用メモリは、15.6GBの使用でした。
変数chat_historyの内容
>>> print(chat_history)
### 指示:
ドラえもんとはなにか
### 応答:ドラえもんは、未来からやってきたネコ型ロボットである。22世紀の日本では、ドラえもんが持つことのできる四次元ポケットのなかに、さまざまな発明品やアイテムが入っている。ドラえもんはのび太をサポートし、のび太の人生を軌道に乗せるようにサポート する。のび太があらゆる問題に直面し、困難を抱える度に、ドラえもんはのび太をサポートし、助けてくれる。そのため、ドラえもんは 、のび太の母親の役割も果たす。
### 指示:
続きを教えてください
### 応答:ドラえもんは、のび太の人生に多大な影響を与え、のび太を常にサポートしている。ドラえもんは、のび太が困難に直面したとき、すぐに助けに来てくれます。ドラえもんは、のび太が間違った道を選んだとき、いつでも正しい道に戻してくれる。ドラえもんは、 のび太に、人生で起こるすべての困難を経験し、克服し、楽しむように促しています。ドラえもんは、のび太の人生をより豊かで楽しい ものにしてくれる存在である。
### 指示:
続きを教えてください
### 応答:ドラえもんは、のび太が困難を乗り越え、成長する姿を見てきた。そして、ドラえもんは、のび太の人生におけるすべての瞬間に影響を与え、サポートする。ドラえもんは、のび太に人生の多くの教訓を教えてくれます。ドラえもんは、のび太に、すべての人生は 無限であり、すべてのことを試す価値があることを教えています。ドラえもんの最大の功績は、のび太をより良い人間にし、のび太の人 生をより良いものにしたことでおまけ2 - 13b
tokyotech-llm/Swallow-13b-instruct-hf も試してみました。
>>> chat_history = q("ドラえもんとはなにか")ドラえもんとは、未来の世界からやってきた猫型ロボット。四次元ポケットから様々な「ひみつ道具」を取り出し、主人公であるのび太 とともに、時にはそれらでピンチを切り抜け、時にはのび太の悪い癖を叱り飛ばしつつも、のび太を支え続ける。そのひみつ道具により 、のび太の人生は大きく好転し、後のドラえもんの存在意義すら危うくしてしまうほど。
151.74658269999998
chat_history = q("続きを教えてください", chat_history)そして、ある日のび太はドラえもんのことを思い、号泣する。それを見たドラえもんも一緒になって、のび太とともに泣き続けるのであ った。
58.859720099999976
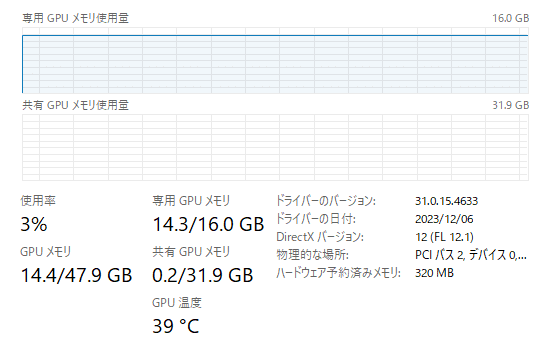
7bと比較して遅いけれども、GPU専用メモリも溢れてませんでした。てか、7bよりも少ない….。
この記事が気に入ったらサポートをしてみませんか?