
ComfyUIでGPT-4V + DALL-E3を使ったimg2img

こんにちは。キャッチーなタイトル付けるの苦手な子です。
ComfyUI-NegiTools v0.4.1 アップデート
まずは拙作NegiTools https://github.com/natto-maki/ComfyUI-NegiTools をアップデートしたことをお知らせします。このアップデートでは以下のような更新が加わりました。
OpenAI DALLe3ノードの更新。
従来は内部で固定していたパラメータを変更できるようにしたほか、content_policy_violation対策でリトライを入れられるようになりました。OpenAI GPT4Vノードの追加。
GPT-4Vは入力した画像を分析できるGPT-4の新機能です。OpenAI GPT4VノードではこれをComfyUI上から呼び出せるようにしました。OpenAI GPTノードの追加。
GPT-4などを使用してテキスト生成(chat completions)ができます。
この記事では、これらの新しいノードを使ってDALL-E3を使ったimg2imgに挑戦してみたいと思います。
テキストを経由するimg2img
画像生成モデルであるDALL-E3は、高品質な生成やプロンプトに忠実な生成といった特長を持ちます。これをComfyUIから直接使えるようにしたNegiToolsのOpenAI DALLe3ノードであれば(宣伝)、プロンプトを自動生成してDALL-E3に渡すような使い方もでき、画像生成環境としてはなかなかに強力といえます。
しかしその一方で、API版DALL-E3にはgen_idやseedのような仕組みがありません。img2imgやinpaintingはもとより、Bingでできるように、全体の雰囲気を保ったまま対話により一部分を変更といった操作はできないことが欠点といえるでしょう。
そこで今回は、先日APIが利用可能になったGPT-4Vを使用し画像の説明文を作成して、さらにこれをプロンプトとしてDALL-E3に画像生成させるという無理矢理な方法でimg2img(実態はimg2txt2img)を試してみたいと思います。
方法自体は以下の記事で触れられている方法と同じです。
OpenAI GPT4Vノード
NegiToolsに追加されたOpenAI GPT4Vノードは、GPT-4V APIを呼び出すだけのシンプルなノードです。画像を受け取ることができ、さらにこの画像に対する質問を与えると回答をテキストで返してくれます。
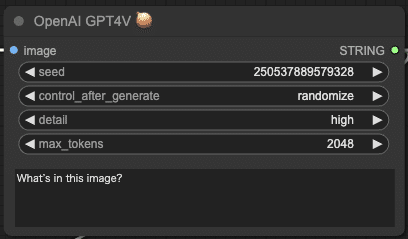
デフォルトで設定されている「What's in this image? (この画像には何が写っているのか?)」という質問文であれば、主要被写体だけではなく画像の中の様々な情報を読み取ってテキストを生成してくれます。
こちらのSDXLで生成した画像で試してみましょう。

workflowはこのようにします。Show Textノードはテキストをそのまま表示するノードで、https://github.com/pythongosssss/ComfyUI-Custom-Scripts に含まれています。
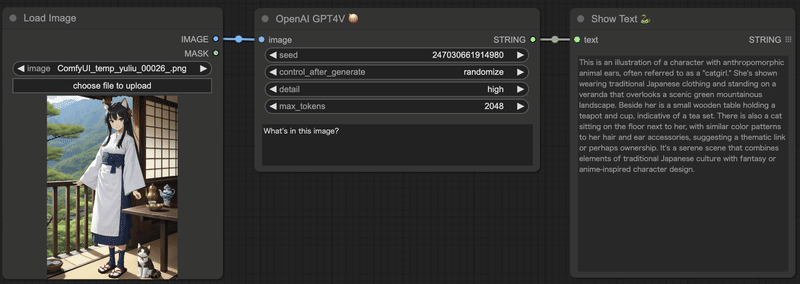
実行するとこのようなテキストが生成されました。
This is an illustration of a character with anthropomorphic animal ears, often referred to as a "catgirl." She's shown wearing traditional Japanese clothing and standing on a veranda that overlooks a scenic green mountainous landscape. Beside her is a small wooden table holding a teapot and cup, indicative of a tea set. There is also a cat sitting on the floor next to her, with similar color patterns to her hair and ear accessories, suggesting a thematic link or perhaps ownership. It's a serene scene that combines elements of traditional Japanese culture with fantasy or anime-inspired character design.
擬人化された動物の耳を持つ、しばしば "猫娘"と呼ばれるキャラクターのイラスト。伝統的な和服を着て、縁側に立っている。彼女の横には小さな木のテーブルがあり、ティーポットとカップが置かれている。また、彼女の隣には猫が座っており、彼女の髪や耳のアクセサリーと同じような色柄をしている。伝統的な日本文化の要素と、ファンタジーやアニメにインスパイアされたキャラクター・デザインが融合した、静謐なシーンである。
GPT4Vすごいですね。たぶん合っている気がします。
キャラクター以外についてもちゃんと説明してくれました。
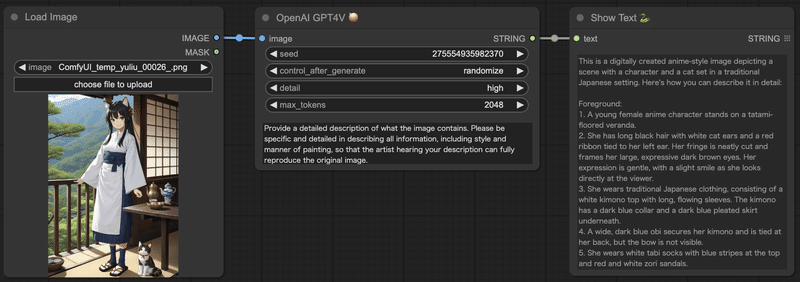
このままDALL-E3に渡せば似た画像を作ってくれそうです。が、さらに、画像生成を見越してもう少し詳しく説明してもらうことにしましょう。OpenAI GPT4Vノードのpromptを以下のように変えてみます。max_tokens(最大生成トークン数)は少し大きめにしておいた方がよいでしょう。
Provide a detailed description of what the image contains. Please be specific and detailed in describing all information, including style and manner of painting, so that the artist hearing your description can fully reproduce the original image.
画像の内容を詳しく説明してください。あなたの説明を聞いたアーティストが原画を完全に再現できるように、画風や描き方などすべての情報を具体的かつ詳細に記述してください。
結果はかなり長い文章になるので割愛しますが、細部まで詳しく説明した説明文を返してくれます。
これを生成用のプロンプトにすればいいですね。
img2img風
それでは、得られたプロンプトを使って画像生成してみましょう。workflowは以下のようになります。
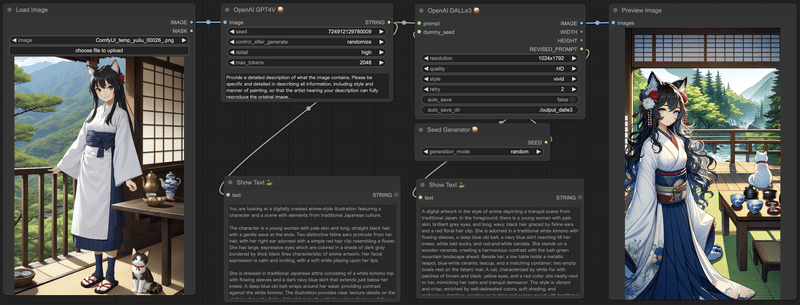
で、実行。

いかがでしょうか。
img2imgと呼ぶにはちょっと変化しすぎている気もしますが、雰囲気や要素を保ったまま新しい画像を生成できて・・・いるような・・・そうでもないような・・・?
作例1
この方法による生成例をいくつか載せておきます。まずはさきほどのSDXL生成画像をもとに生成した画像から。


妙なのが混ざっている気がしなくもない。
作例2
続いてDALL-E3で生成した画像をもとに生成してみます。この画像はDALL-E3で生成したものの、人体の構造がおかしいことに気づきお蔵入りしていた画像です。

生成後の画像がこちら。

このケースでは本来のimg2imgのように、画風・スタイルがうまく引き継がれています。
作例3
最後はこちら。DALL-E3とSDの合せ技で作成された画像。

何とは言いませんが失われる要素はあるでしょうね。

肌色に厳しいDALL-E3にしては健闘したほうではないでしょうか。
元画像の画風(リアル風・アニメ風)が統一されていないこともあって、生成された画像はどちらかの画風に寄ってしまうようです。
以上、img2imgの作例でした。
一旦テキストのみになってしまうため、細かな画風や意図のようなものは伝わらず、どうしても変化してしまう要素はあります。それでも言葉で説明できる範囲では十分再現されており、バリエーションを生み出すという目的ではある程度使えるんじゃないかと思います。
画像を変化させてみる
せっかく画像の説明テキストが手に入ったので、もうすこし遊んでみましょう。テキスト処理といえばGPT-4君です!
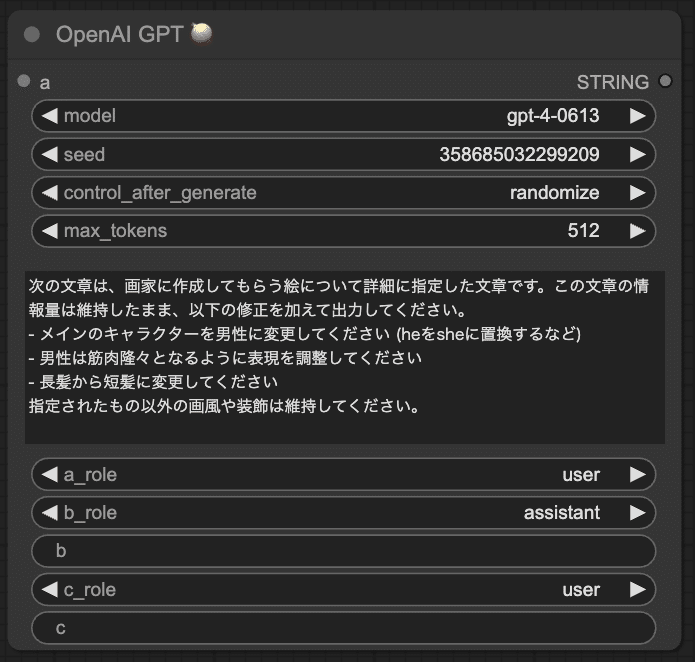
NegiToolsに含まれるOpenAI GPTノードを使えば、GPT-4やGPT-3.5を使ってプロンプトを変化させることができます。
workflowはこうなります。
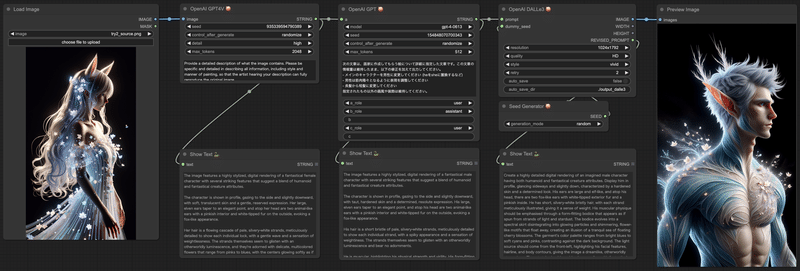
OpenAI GPT4ノードのパラメータaを入力に変更して、GPT-4Vによって生成された画像説明文を接続します。OpenAI GPT4ノードは受け取ったテキストをsystem_promptで処理した結果を出力するので、それをプロンプトとしてDALL-E3に入れて画像生成するという流れです。
作例1
最初の例として、GPT-4君に以下のようにsystem_promptで指示してみました。ここでは日本語にしましたが、英語で指示した方が精度が高いです。
次の文章は、画家に作成してもらう絵について詳細に指定した文章です。この文章の情報量は維持したまま、以下の修正を加えて出力してください。
- メインのキャラクターを男性に変更してください (heをsheに置換するなど)
- 男性は筋肉隆々となるように表現を調整してください
- 長髪から短髪に変更してください
指定されたもの以外の画風や装飾は維持してください。
できあがった画像がこちら。

次は人以外に変えてみます。
次の文章は、画家に作成してもらう絵について詳細に指定した文章です。この文章の情報量は維持したまま、以下の修正を加えて出力してください。
- メインのキャラクターを猫に変更してください
- 猫は美形でふわふわな毛並みとなるように表現を調整してください
- 猫は人間のような立ち姿ではなく、猫としての自然な姿勢をとるように表現を変更してください
指定されたもの以外の画風や装飾は維持してください。

時々人のままなのはDALL-E3が悪い気がする。
作例2
今度はこちらの画像をベースにして、人物を増やしてみます。

system_promptはこんな感じにしてみました。
次の文章は、画家に作成してもらう絵について詳細に指定した文章です。この文章の情報量は維持したまま、以下の修正を加えて出力してください。
- メインのキャラクターを女性1人から女性2人に変更してください。
- 人物の特徴はここで指定したものを除き、元の記述に沿ったものとしてください。
- 髪型は片方がロング、もう片方はボブにしてください。
- 2人が交錯するポーズをとらせてください。
指定されたもの以外の画風や装飾は維持してください。

うまくいきましたが、ちょっと情報過多になりましたね。
そのあたりもGPT-4君にお願いすれば調整してくれるかもしれません。
作例3
応用例として、2つの画像の特徴を合成してみます。
workflowはこんな感じで、それぞれの画像から説明文を抽出したあと、説明文をGPT-4で統合します。

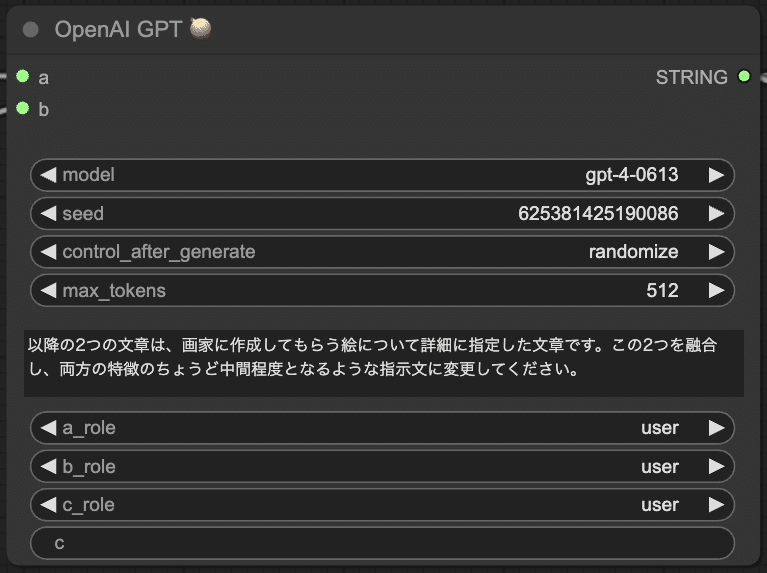
system_promptでは単純に合成を指示しました。
以降の2つの文章は、画家に作成してもらう絵について詳細に指定した文章です。この2つを融合し、両方の特徴のちょうど中間程度となるような指示文に変更してください。
結果がこちら。
なんとなく和テイストが混ざった不思議な画像ができあがりました。

このやり方は合成を指示するプロンプトの書き方や説明文の抽出方法によって様々な応用が考えられます。狙った特徴だけ抽出したり、自分で書いたプロンプトと融合させるようなこともできるでしょう。
まとめ
というわけで、変則的な手法ながらGPT-4Vの力を借りたimg2imgを試してみました。DALL-E3の高画質を活かしつつ、元画像の重要な特徴を保ったままバリエーションを生成できることがわかりました。
ただしその一方で、途中でテキストしかない状態を経由している関係で、元画像からの変化が大きくなる点に注意が必要です。
途中GPT-4によるテキスト処理を挟むことで、指示に基づく追加の加工も実現できました。ここはさらに改良・発展の余地がありそうです。
ぜひ皆さんも色々試してみてください!
OpenAI APIは完全な従量課金なので契約しておいて損はないです。きっと。
最後に
i2iトレパクは絶対にしないでくださいね。
この記事が気に入ったらサポートをしてみませんか?