【検証】勾配決定木で『相関の強いデータ(多重共線性)』を使うと、線形回帰の様な不都合は起きるのか??

お疲れ様です。東京で仕事をしているものです。へちやぼらけと申します。(統計学・機械学習に関する動画も投稿している、所謂YouTuberです。笑)
今回は、タイトルの通りです。勾配決定木で相関の強いデータ(多重共線性)を説明変数に使うと、線形回帰の様な「回帰係数が安定しない的」な不都合は起きるのか?? これについて、検証していきたいと思います。
始めに結果を言えば、不都合起きます。予測のタスクでは問題無いですが、変数重要度が”ブレブレ”になることがわかりました。なので、勾配ブースティングをする際も、説明変数のチェックをする必要があるかもです。
そもそも、「線形回帰において、相関の強いデータを予測に使ってしまうと、回帰係数βの値が不安定になる。」というのはご存知かと思います。数式から簡単に理解できることですし、pythonなどで数値検証もできます。
【何故?βの値が不安定なる?】
回帰係数βの分散の値。こいつの分母に、相関係数rの2乗が存在します。このr2乗が、1に近づけば近づくほど、βの分散が大きくなる(分母が0に近づくわけですから・・)。という訳です。

pythonによる数値実験でも簡単にわかります。以前、私が実際に数値検証をしてみた動画があるので、ご連携します。
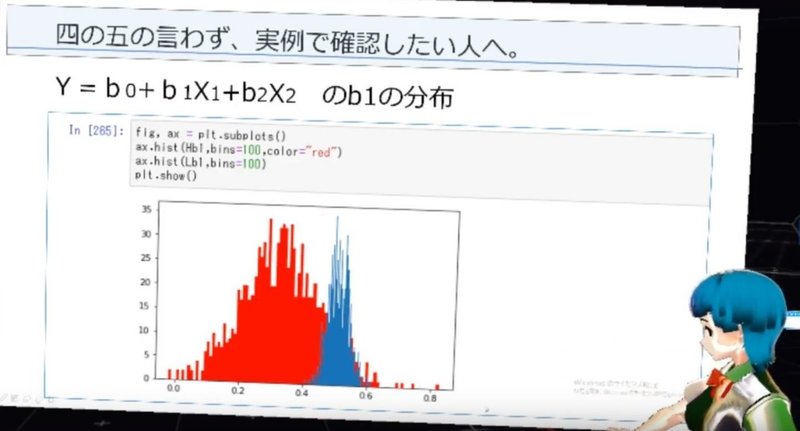
X1とX2の相関が弱い時・相関が強い時で、それぞれ1000回の回帰分析を行い、回帰係数βの値をヒストグラムにまとめています。青が相関の弱い時・赤が相関の強い時です!相関係数の強い変数を使って、回帰分析をすると、βの値がこんなにも不安定になるんですね!分散、大きすぎです(笑)
さて、回帰分析だとβの分散を数式で表現できるため、分散の式を見れば「あっ!相関の強いデータを目的変数にすると、βの値不安定になるな」ってことは一目瞭然なんですが、勾配ブースティングなんて式が複雑すぎて分からないっすよね…。
なので、数値実験というアプローチで見ていきましょう!
さて次は、相関の高いデータを説明変数に勾配ブースティングをやっていきますよ!果たしてどうなるのでしょうか??(ちなみに、実験に使う勾配ブースティングは、XGBoostで行かせていただきます。)
【実験1】分類問題
まずは分類から。使用するデータは、kaggleなどで有名なタイタニックのデータです。乗客の性別・年齢などの情報とともに、その乗客が生き残ったかを0,1でラベルしているデータです。
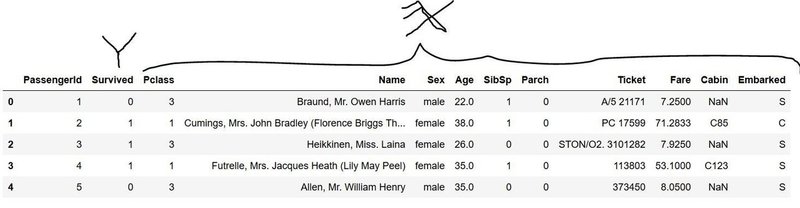
まずは、このデータに対して分類のタスクをやらせてみましょう。変数重要度は、どうなるでしょうか?
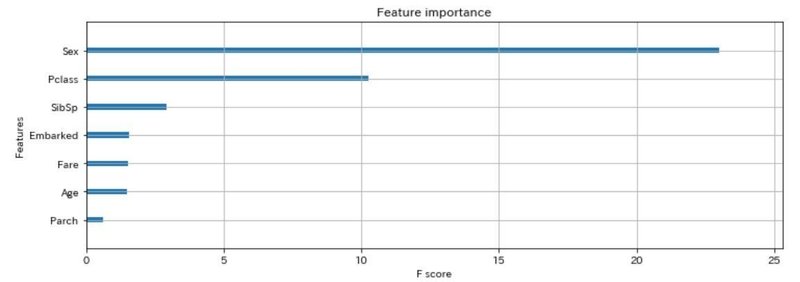
はい、ということで、皆さんご存知の結果ですね(笑)。Sex(性別)が死ぬか生きるかに大きく寄与している変数です。
さて、検証はココから。相関の強いデータをぶち込んで、XGBoostをやってみましょう。相関の強いデータに使用するデータは、Sex(性別)の逆とします。要するに、男⇒女・女⇒男に書き換えたデータです。連続量ではありませんが、負の相関はめちゃめちゃ高くなります。(正確には、クラメールの連関係数)
こいつを「un_Sex」として、さっきと同じようにXGBoostします。・・・。
結果、ドン↓
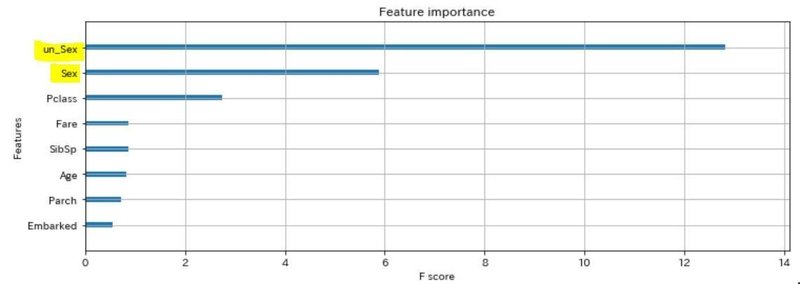
こんな感じです。sexの重要度は相変わらず高いんですが、un_Sexの重要度が2倍以上に伸びてるのわかります??
次は、XGBoostのパラメタを少しだけ変えて、もう一回、やってみます。・・。
結果、ドン↓↓
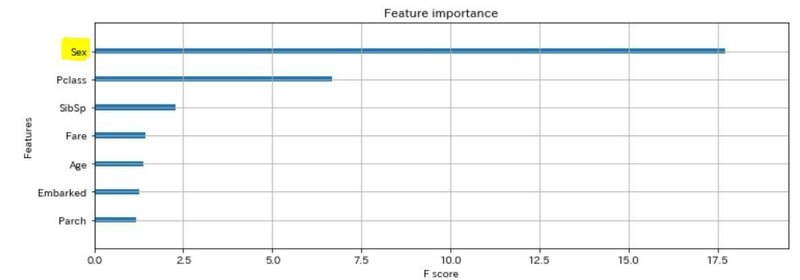
次は、un_Sexの値が消えてしまいました・・。もう一回、パラメタ変えてドン↓↓↓
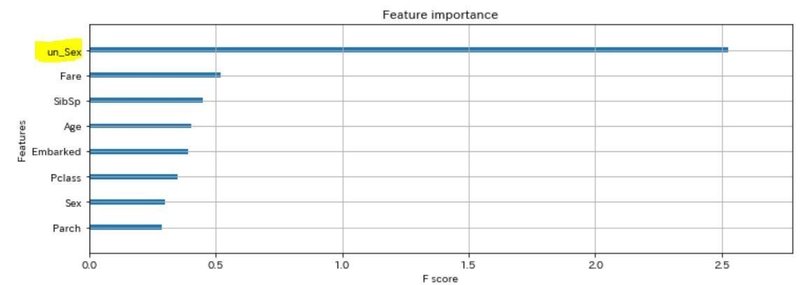
今度は、Sexの値が消えてしまいました・・・。変数重要度(Feature importance)ブレブレじゃないですか!!!!!
【実験2】回帰問題
続いて、回帰のタスクで実験してみます。実験に使うデータはボストンデータ。ボストン市周辺の家賃yと、その賃貸の情報xを持つ有名なデータですね。
まずはこのデータのまま、家賃を予測するというタスクをやって変数重要度を確認します。結果↓
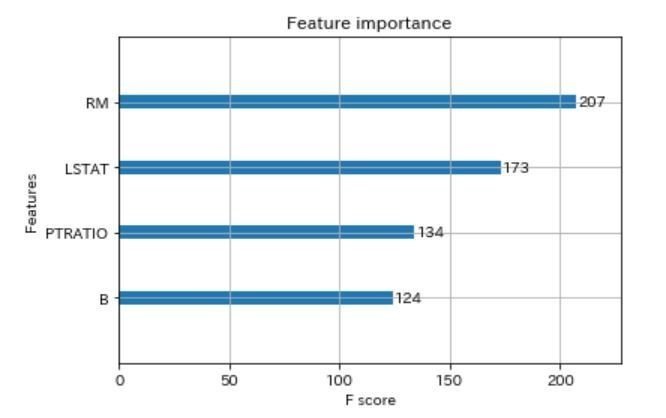
RM(1住戸あたりの平均部屋数)が、家賃を予測する上で、もっとも重要とのこと。
実験は、ここから。今度は、RMと相関のめちゃめちゃ高いRM2を定義します。RM2=>2*RM+1です。さて、もう一度XGBoostだ。
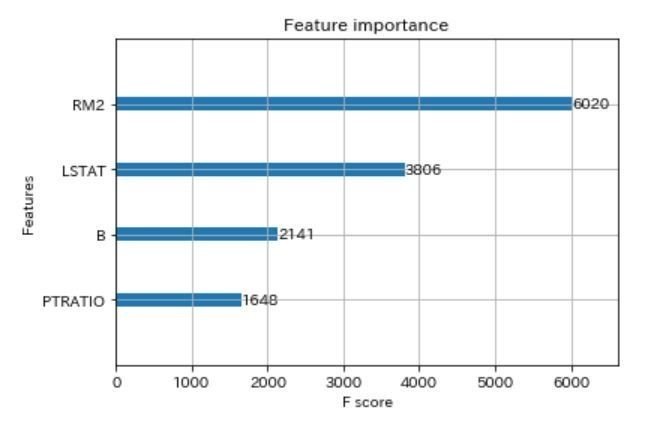
RMが消えて、RM2が一番重要度の高い変数になってしまいましたね・・。
色々、パラメータをいじくりながら、変数重要度を確認したのですが、カテゴリカルの時と異なり、RMとRM2の両方を出力することができませんでした。どちらかが出力されれば、どちらかは必ず出力されないようです。
色々と検証してわかったのですが、目的変数Xの形状に依存しているようで、RMが定義されている列がRM2が定義されている列よりも前にいた場合、RMが変数重要度として出力されるようです。逆もまた、同様。

データの形状で結果変わるとか、変数重要度って案外頼りにならないな・・・。
以上です。ブースティングの時も、多重共線性に気を付けた方がよさそうですね。恐らくこの現象は、決定木(ランダムフォレスト)・LightGBM・CatBoostでも起こりえそうです。(実験してないので、適当なことは言えませんが。)
この記事が気に入ったらサポートをしてみませんか?