
ChatGPTの導入で非定形フォーマットのOCRを実現した話

はじめに
はじめまして、わたくし株式会社ZISEDAIでエンジニアをしております程 (てい) と申します。
この度、日頃の開発内容をフランクにお伝えしたり、共有していけたらいいなという思いで、株式会社ZISEDAIのテックブログを開設させていただきました。
記事を読んでいただき、ZISEDAIがやっている技術に興味がある方がいればぜひお声がけいただけますと嬉しく思います。
記事概要
今回は記念すべき一回目ということで、最近リリース致しましたホットな新機能の裏側をご紹介していけたらいいなと思います。
プレスリリースをすでに読んでいただいている方はご存知かと思いますが、つい先日、物件資料のOCR機能の提供を弊社のSaaSプロダクト、TASUKI TECH LAND (以下、LANDと略記) にて開始させていただきました。
本記事ではこちらの機能が裏側で何をしているかについてまずは触りの部分を書いていこうかなと思います。
より詳細な内容などについても、おいおい別記事にて書いていく予定ですので、興味のある方は、本記事末尾の関連リンク(更新次第追加予定)よりご覧くださいませ。
本題
ChatGPTと聞くと、皆さんご想像されるのはおそらく、LINEのような会話形式でAIと文章による会話ができるUI/UXが思いうかぶかと思います。
一方、今回のリリースにおいてはチャットのような会話をする目的ではChatGPTを使っておりません。では、今回はどのような用途でChatGPTを導入したのか、更に以下にてご紹介します。
OCR読み取りにおける課題
突然ですがこちらは、ある物件資料PDFをキャプチャしたものです。

さらに、こちらのPDFをOCRで読み取ってみようと思います。
今回は、Microsoft Azure が提供している Azure AI Document Intelligence というOCRサービスを用いて、試してみます。
得られた結果がこちらです。
【物件概要書】\n種 別\n価 格\n所 在\n交 通\n土 地\n相談\n住居表示\n東京都港区東麻布9-9-99\n登記記録\n東京都港区東麻布9-9-99\n東京メトロ南北線·都営大江戸線\n「\n麻布十番\n赤羽橋\n」駅\n徒歩 8 分\n土 地\n法令制限\n道 路\n備 考\n|駅 徒歩 2 分\n都営大江戸線 「 権利形態\n所有権\n宅地\n登記地目\n登記記録\n152.25 ₥\n(\n46.05 坪 )\n有効面積 152.25 ₥\n都市計画 市街化区域\n用途地域 第一種住居地域\n建ぺい率\n60\n%\n容積率\n300\n%\n高度地区\n第三種高度地区\n防火規制\n準防火地域\n日影規制\n4h -2.5h/4m\n( 46.05 坪 )\n街路状況\n東側幅員\n約\n5.77 m\n公道\n約 13.47 m 接道\n接道状況\n東側公道\n現況:更地(地中残存杭あり)\nTT\nCL\n0\nC\n住戸面積 · 想定月額賃料(管理費込)\n階数\nタイプ\n間取\n床面積\n5\nD\n1LDK\n42.61m2\n想定月額賃料 (管理費込) 178,000円\n4\nD\n1LDK 42.61m2\n179,000円\nC\n1K\n16.96m2\n92,000円\n3\nB\nA\nC\n2\nB\nA\nC\n1\nB 1R\n1R\n16.57m2\n91,000円\n1R\n18.37m2\n95,000円\n1K\n16.96m2\n91,000円\n1R\n16.57m2 90,000円\n1R 18.37m2\n1K 16.96m2\n16.57m2\n94,000円\n89,000円\n88,000円\nA\n1R\n18.37m2\n92,000円\n想定年間賃料収入 14,148,000円\nC\n-C\n引渡し時期:相談 参考プランあり(壁式RC造4階建 総戸数11戸) 詳細につきましては、物件担当者までお問い合わせ下さい。\n設備·仕様\n..\n1 階平面図\nホームIoTシステム/インターネット高速Wi-Fi/エア コン/浴室·トイレ別/浴室乾燥機/2ロIHコンロ/ 温水洗浄便座/フローリング/宅配ボックス/防犯カ メラ(共用部)/オートロック/玄関ダブルロック (ディンプルキー)他\ne\n2, 3 階平面図\n土地評価等\n取引形態\n令和4年度 土地評価額\n162,513,110 円(参考、分筆前の評価額)\n売主\nBH\nO 1.\nCC\nC\nFalL\n0\n0\n土地情報求む !! 壁式RC造プランをはじめ、開発手法を知り尽くした「タスキ」では、開発が難しいとされる用地こそ、仕入れの好機です。 だから用地仕入は急拡大中。\n「23区内、駅徒歩10分圏の土地情報」は、「タスキ」にお任せください。\nC\ne\nトーアルルルー\n4 階平面図\nY\nC\ne\n近隣施設·店舗\nセブンイレブン · 徒歩5分 (約400m) ファミリーマート · 徒歩7分 (約600m) フードストアーかみもと · 徒歩1分(約30m) みずほ銀行駒込支店 · · 徒歩8分(約600m) 文京千石郵便局 · · · 徒歩5分(約400m)\ne\n5 階平面図\n21\nSE\nその技術を次世代へ Bring the Technology to the Next Generation\n株式会社ZISEDAI\n〒107-0061東京都港区北青山2-7-9日昭ビル2階\nTEL : 03-5315-4791\nFAX : 03-5315-4792
ご覧の通り、実は文字をそのままの「羅列」で読み取ってしまうのですね。
もちろんこれを人間が見れば、どこからどこまでが住所のデータで、どこからどこまでが築年月のデータかは割とぱっと判別できたりするのですが、実はコンピュータで同様の判別をさせようとしても、意外に困難だったりするわけです。
つまり、書いてある文字は読み取れても、読み取った文字のどの部分が実際に欲しいデータなのかを判断、抽出するという処理を実装するのは、一般的なWeb領域の技術では太刀打ちするのが難しかったのです。
※ 上記のような処理を機械学習といった数理学的なアプローチで実現されている企業様もいらっしゃるので、完全に不可能というわけではないですが、数学的な専門知識やモデル構築の知見が必須となります。
ChatGPTの活用用途
さて、そんな課題に対して今回はChatGPTを適用してみました。では、先程のサンプルから試しに住所を抽出させてみましょう。
今回は Microsoft Azure が提供している Azure OpenAI Service 上で、GPT-4 モデルを使って抽出に挑戦します。
今回、結果としてChatGPTに返答してほしい文字列はこちらですね
正解:「東京都港区東麻布9-9-99」
それでは、実際にChatGPTを動かしてみます。
今回与えるプロンプトはこちらです。
以下はある物件の説明書きをOCRスキャンしたものです。 この物件の住所を抽出してください。
(ここに先程のOCRスキャン結果のコピーを貼る)
それに対するGPTの返答がこちらです。
この物件の住所は「東京都港区東麻布9-9-99」です。
見事に大正解ですね。さすがこれだけ世間を席巻しているChatGPTです。
プロンプトを与えたときのイメージ画像です。

せっかくなので他の情報も抽出させてみましょう。

これは駅名は正解ですが、徒歩時間が残念ながら不正解ですね。
麻布十番駅は正しくは徒歩2分なので、やや結果としては惜しい結果となってしまいました。このへんは今後、より精度高く抽出できるように工夫する余地があるかもしれないので、将来的に改善できる方法を考えたいポイントです。
近くの施設をリストアップさせてみました

今回は全正解です。複数ある正解をすべて抽出できていて素晴らしい結果です。
自社SaaSとの連携
ここまででChatGPTを用いることで、OCRで読み取った文字列から欲しい項目を狙い撃ちで抽出できることがわかりました。
一方、抽出したデータはChatGPT上のUIではなく、最終的にはLAND(弊社SaaS)上にデータを連携させる必要があります。
そのために弊社では、ChatGPTへの処理の依頼はAPIを通して通信させており、LANDのユーザーが画面上のボタンを押したタイミングで自動で抽出処理と処理結果の画面表示を実装しています。
LANDにおいては、物件情報として各種項目をフォーム形式で入力できるようになっております。
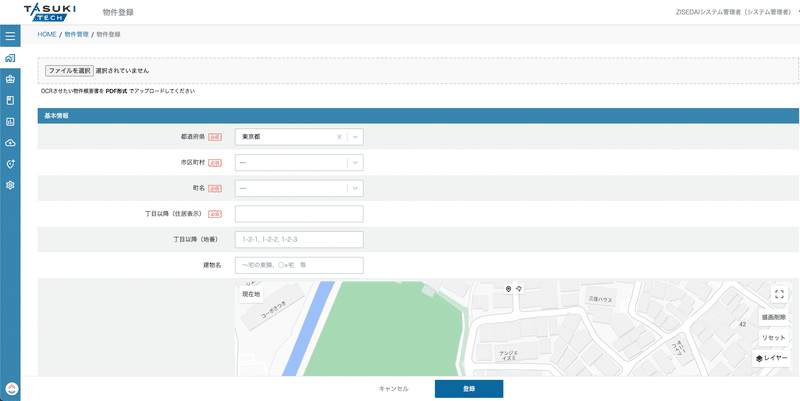
実は、これらのフォームを従来は手動で入力する必要があり、やや手間と感じるユーザー様もいらっしゃいました。
今回OCR機能が提供開始となったことで、画面上部のファイルアップロードよりPDFファイルをアップロードするだけで、OCRとPDF抽出が開始するようになります。
スキャンが完了すると、自動で各項目ごとのフォームに、読み取ったデータが反映されるため、手動での入力作業が軽減されるという寸法です。
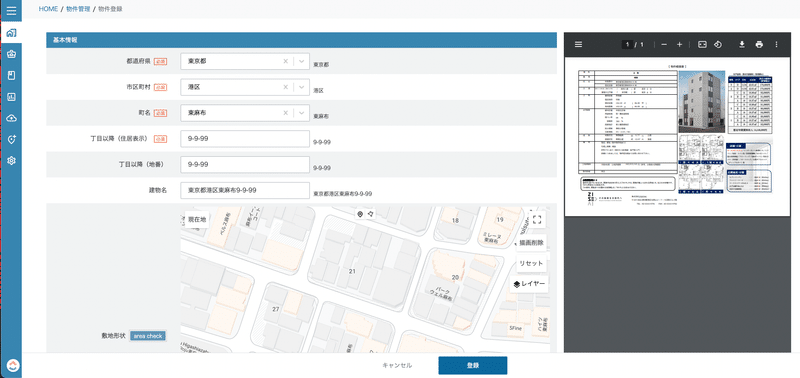
さて、先程のChatGPTを使った例では、1回の抽出依頼ごとに1つの項目のみを抽出させていましたが、同時に複数の項目を抽出させることももちろん可能です。上記でご紹介した画面機能の裏側では、APIのレスポンスとして下記例のようなレスポンスを返却させており、同時に多数の項目を一気に抽出してくるようAPIにリクエストを投げています。これによって、1回ボタンをクリックするだけで、各種項目の大半を自動で画面に反映させるということを実現させています。
{"result":{
"住所":{"都道府県":"東京","市区町村":"港区","字":"東麻布","丁目以降":"9-9-99"},
"地番":["9-9-99"],
"物件名":"",
"土地":{"地目":"宅地","地積公簿":"152.25m2","地積実測":"152.25m2" },
"権利":"所有権",
"現況":"更地(地中残存杭あり)",
"道路":["東側幅員約5.77m公道","東側公道約13.47m接道"],
"用途地域":{"種類":["第一種住居地域"],"建蔽率":["60%"],"容積率":["300%"]},
"防火地域":["準防火地域"],
"高度地区":["第三種高度地区"],
"日影規制":["4h-2.5h/4m"],
"最寄り":[{"駅名":"東京メトロ南北線・都営大江戸線麻布十番駅","徒歩時間":"8分"}],
"家屋番号":[""],
"建物":{"構造":"壁式RC造","階数":4,"築年月":"建設予定","総戸数":11,"延床面積":"","専有面積":""},
"検査済証":"",
"間取り":["1LDK","1LDK","1K","1R","1R","16.96m2","1R","18.37m2","1K","16.96m2","1R","16.57m2","1R","18.37m2"],
"最寄りの施設・店舗":[{"施設名":"セブンイレブン","徒歩時間":"5分","距離":"約400m"},{"施設名":"ファミリーマート","徒歩時間":"7分","距離":"約600m"},{"施設名":"フードストアーかみもと","徒歩時間":"1分","距離":"約30m"},{"施設名":"みずほ銀行駒込支店","徒歩時間":"8分","距離":"約600m"},{"施設名":"文京千石郵便局","徒歩時間":"5分","距離":"約400m"}],
"収入":{"金額":14148000,"内訳":""},
"支出":{"金額":"","内訳":""},
"販売金額":"",
"表面利回り":"",
"ネット利回り":"",
"路線価":162513110,
}}使用データの扱い
重複となりますが、弊社が使用しているGPTモデルは、Microsoft Azure提供のサービス経由で利用しています。
Microsoft Azure では、GPTを使用する際のデータの扱いについて下記の公式サイトで次のように表明しています。
Your prompts (inputs) and completions (outputs), your embeddings, and your training data:are NOT available to other customers.
are NOT available to OpenAI.
are NOT used to improve OpenAI models.
are NOT used to improve any Microsoft or 3rd party products or services.
are NOT used for automatically improving Azure OpenAI models for your use in your resource (The models are stateless, unless you explicitly fine-tune models with your training data).
Your fine-tuned Azure OpenAI models are available exclusively for your use.
The Azure OpenAI Service is fully controlled by Microsoft; Microsoft hosts the OpenAI models in Microsoft’s Azure environment and the Service does NOT interact with any services operated by OpenAI (e.g. ChatGPT, or the OpenAI API).
せっかくなのでこれもChatGPTで日本語訳させましょう

あなたのプロンプト(入力)とコンプリート(出力)、あなたのエンベッディング、あなたの訓練データは:他の顧客には利用できません。
OpenAIには利用できません。
OpenAIモデルの改善には利用されません。
Microsoftや第三者の製品やサービスの改善には利用されません。
Azure OpenAIモデルの自動改善には利用されません(モデルはステートレスで、あなたが明示的に訓練データでモデルを微調整しない限り)。
あなたが微調整したAzure OpenAIモデルは、あなただけのために利用可能です。
Azure OpenAIサービスは完全にMicrosoftが制御し、MicrosoftはOpenAIモデルをMicrosoftのAzure環境でホストし、サービスはOpenAIが運営する他のサービス(例えば、ChatGPT、またはOpenAI API)とは一切関わりません。
つまり、GPTモデルを利用した際のユーザーデータは、OpenAIに提供されることがなく、モデルの学習に利用されることもなく、他サービスで利用されることもないですよ。という趣旨の内容であると理解できます。
そのため、予想外に外部にGPT利用データがMicrosoft側から漏れてしまうということはサービスの仕様上ないということが述べられているため、安心してGPTの利用ができるというところも、今回導入を決めた決め手の1つとなりました。
むすびに
今回、初めてテックブログを投稿させていただきました。
今後も弊社SaaS製品の技術面に関する記事や、技術組織での取り組みに関する内容を投稿していこうと思っています。
本稿では、最近リリースしたChatGPT活用したOCR機能の触りの部分を書きましたが、プロンプト検証した際の気づきだったり、インフラ構成だったり、LANDとの統合で悩んだことだったり、より細かいエピソードトークを交えた記事を更新していく予定ですので、ぜひご期待いただければ嬉しいです。
最後に、テックブログの継続を応援してくださる方は記事タイトル下部にあるハートボタンを押していただけると励みになるので、ぜひよろしくお願いします。
関連記事
(今後更新予定です)