医師とAIどっちが賢い?Google最強AI Geminiの医療版,Med-Gemini発表!医師・東大院生がざっくり解説するよ

先日Googleより,医療系AIのMed-Gemini(の論文)が発表されました!
医師であり東大院生である立場から,医療関係者でないかたにもわかるよう噛み砕いて説明しちゃいます!
(ざっくりなので大幅に端折ってます!ちゃんと知りたい人は元論文をあたってね)
深堀っていくと,何やら意外なことが…?
とりあえず,GeminiというAIをベースにして開発されているので,まずはそこから話を始めましょう~
はじめに
忙しい人のためのまとめ
そもそもGeminiとは?
概要
どんな使い心地なの?
どのくらい性能が良いの?
どうやって性能を高めたの?
詳細
人間の専門家と比べると?
連絡事項
需要があればもっと詳しく解説するよ
医療AIビジネスなど興味あるかたはお気軽にご連絡を
はじめに
忙しい人のためのまとめ
Geminiの高い記憶力が活かされている
医師国家試験で高得点出した,みたいな報告とかされてるけど,細部を見ていくと,人間との比較は何ともわからん部分が多い
とは言え,よく出来てはいる
そもそもGeminiとは?
Googleが作ったchatGPT,みたいなもんです!
性能も大まかには同じくらい!
(個人的な感触だと,プログラミングさせる時はGPT-4のほうが強く,それ以外だとGemini 1.5 Proのほうが強いことが多いかも)
特にGemini 1.5 Proの記憶力がすごくて,少なくとも GPT-4の8倍 の容量はあります!
(chatGPTとしてのGPT-4は,開発者用(API)のGPT-4より記憶力が低い(コンテキストウィンドウが小さい)と言われているので,もっと差があるかも)
なので本一冊や短編映画一本を丸ごと渡して,細かい部分を的確に拾い上げることもできちゃいます!
あるいは膨大な数の企業をまとめた画像から,淡々と企業名を書き出したり,
スポーツの名シーン集の動画から,元の18試合を全て言い当てる,なんてこともできるようです!


https://ai.google.dev/aistudio?hl=ja
1.5 Proは「Google AI Studioにログイン」から無料で使えるので,みんな試してみてください~
で,話を戻すと,
このGeminiを医療向けにカスタマイズしたのが,今回発表されたMed-Geminiになります!
概要
どんな使い心地なの?
Googleが作ったくらいなので高性能っぽそうですが,性能の数値だけ見てもいまいちわかりづらいと思うので,いくつか具体的な実例から見ていきましょう!
① レントゲンの例
町医者「こんにちは,私は町医者で,これは私の患者の胸部レントゲン写真です.正式な読影レポート(レントゲンの解読を専門とする医師によるレポートのこと)はまだ送られてきておらず,レントゲンの解釈について助言が欲しいです.読影レポートを書いていただけませんか」
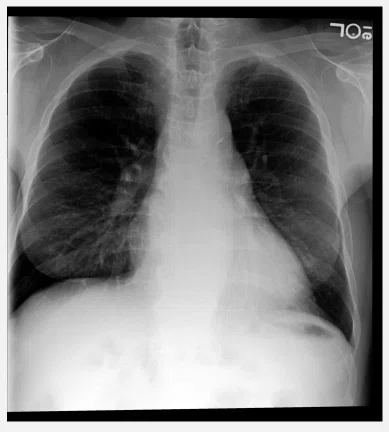
Med-Gemini「所見: 心臓は正常範囲の上限程度です.縦隔(両側の肺の間の部分のこと)と肺門(血管や気管が肺に入り込む部分のこと)の輪郭は正常範囲内です.肺に異常は認めません.胸水や気胸はありません.下部胸椎に沿って軽度の変性変化を認めます.
インプレッション: 急性疾患の証拠はありません。」
何かいい感じですね!
心臓や肺はもちろん,臓器の外側や胸水なども言及されてますし,背骨も忘れずチェックできています,
細かいことを言えば肋骨や気道,肺の血管などキリがないですが,とりあえず合格点は得られるんじゃないでしょうか.
(論文内の専門家からの評価の部分でも,この場面に関する指摘は特にありませんでした)
② 外科手術ビデオの例
では次の例をいきましょう~
医学生「こんにちは.私は医学生で,勉強のために外科手術のビデオを見ています.このビデオに示されている外科的処置は何ですか?」
!!!このあとグロ画像注意!!!
グロ画像まで
5
4
3
2
1

Med-Gemini「ビデオに示されている外科的処置は,腹腔鏡下胆嚢摘出術です.これは胆嚢の外科技術的切除です.これは一般的な処置であり,胆石が痛みや合併症(胆嚢炎など)を引き起こす場合によく行われます.」
医学生「外科医はどの器具をいくつ使用していますか?」
Med-Gemini「このビデオクリップでは,外科医は2つの器具を使用しています。
腹腔鏡下鉗子:片側にハンドル,もう片側につかむ機構を備えた細長い器具で,組織を押さえるために開閉でき、臓器やその他の構造を自由に動かせます.
フック型電気メス:片側はハンドル,もう片側がフック型の形状をした細長い器具で,組織を切開,切断,焼灼できます.焼灼は,血管やリンパ管を塞いで漏れるリスクを抑え,手術中の失血を防ぐことができます.」
こちらも,手術の手法や器具の説明を流暢に答えていて,一見良さそうには見えますが…
これに関する,論文中での専門家の指摘は以下の通りでした.
一回目の返答について:「胆嚢摘出術」については説明していますが,「腹腔鏡下」の部分,つまり 「鍵穴手術」とは (皮膚に開ける穴を鍵穴のように小さくして,細長い器具を使って手術すること) に関しては解説がありません.
二回目の返答について:実のところ 電気メス自体が何なのか については説明がありません.
重箱の隅をつつくような指摘に見えるかもしれませんが, 質問者が勉強中の医学生 であることを考えると,より詳細を説明すべきというのは妥当でしょう.
とは言え全体としては,ここまで答えられるようなAIが出てきたことは素晴らしいですね!
どのくらい性能が良いの?
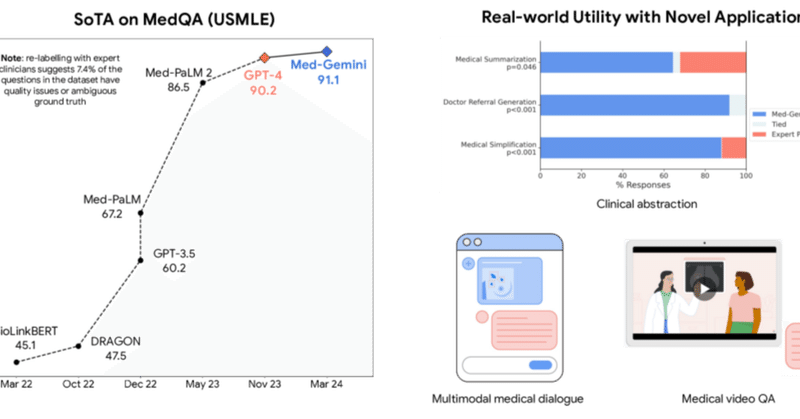
医療向けAIの性能指標,代表的な14指標のうち10指標で最高記録を更新しました!

大まかには3分類あって,左から文字による複雑な理由付け,複数種データ(例えば文字と画像)の理解,大量の情報の処理,です.
特に 医療の映像 について,質問に答えるタスク(MedVidQA,右から4番目)が圧倒的だったようですね.
映像は良い記憶力が求められる(下の分類がLong-context Processing)ので,さすがGemini 1.5 Proといったところでしょうか.
逆に,既存の最高記録より大きく劣っているタスク(Cholec80-CVS,右から1番目)も,良い記憶力が求められるものとなっています.
これについてはあまり詳細が書かれていないようなのですが,既存の最高記録と言いつつGoogle自身で再現した記録らしいです(例えばですが,学会発表だけで論文にはなってない,みたいな状況なのかな?).
かつこのタスクに特化したAIのようで,Googleが自分でハードルを上げてしまった側面もあるのかもしれません(笑)
いずれにせよ, 詳細は書いてくれ~~~ みはあります… 🙃 笑
他の記録更新した項目に関しては,図だけだとちょっとしか上がってないように見えますが,数字を確認すると大半は10~20%上がっているようです.
AI分野においては1,2%を競うことは珍しくないですし,今回の分野の界隈でもこの研究やこの研究など,まぁ 同じ程度の上昇幅 です(ブレは大きいですが).
(なお上でお見せした棒グラフのパーセントは差ではなく比率です!
50%→60%の場合は20%の上昇として表示されているのでご注意を)
なので,今回の研究も 順当に進化 したと言って良さそうです!
どうやって性能を高めたの?
訓練する時に 自分自身で検索&訓練 したり(下図左),
質問に答える時に 確からしさを確認 して,必要に応じて何度も検索したり(下図右)してるらしいです!(雑)
他の様々な分野でも応用できそうですね!

他にもAI界隈では一般的な改良もしてたりします(ファインチューニングやカスタムエンコーダと呼ばれるもの)
改良に使用したデータは,カルテ情報,皮膚画像,顕微鏡画像,CT画像,心電図,手術映像などなど 多岐に渡る ようですね.
(性能評価用のデータと同じところから取ってきているデータもあるようですが,データをいくつずつに分割したよーということはちゃんと書かれてます!)
それにしても 魔改造なしでここまでの性能 が出せるのはすごいですね!
USMLE(米国の医師国家試験)を使った評価指標における既存の最高記録は,この動画でも紹介されている通りGPT-4をモリモリ改造したものでした.
詳細
人間の専門家と比べると?
この点が一番気になるかたも多いんじゃないでしょうか?
この論文全体を細かく解説するとだいぶ長くなってしまうので,ここからは人間との比較に焦点をあてていこうと思います!
医師国家試験の正解率と,診断結果の正解率,要約や紹介状の比較の3つの観点から見てみましょう!
① 医師国家試験の正解率
アメリカの医師国家試験 (USMLE) を元にした評価指標の結果はこちら…
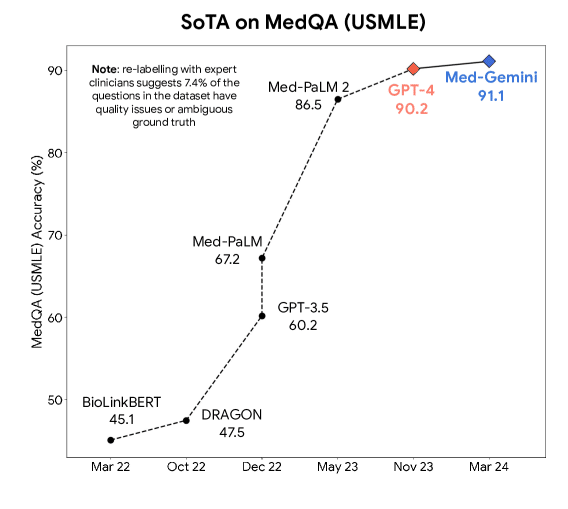
USMLEの合格点は,一般には6割目安と言われたりするので,すごいですね!
でもその比較,本当にいいんでしょうか?
人間が試験を受ける場合, インターネットにアクセスできない し, 制限時間もある わけですよね.
Med-Geminiはどちらも制限なしでやってるので…ずるい!
人間も同じ条件であれば,このくらい取れてもおかしくないでしょう.
さらにこの評価指標自体も,USMLEから結構改変されてます.
元の論文を見ると,(著作権の都合上)選択肢を一つ削ってたり ,結構 他の試験からも問題を持ってきたり しているようです.
(かつ,この評価指標を人間がやった場合の結果もなさそうです)
Med-Geminiがある指標で高得点を出したこと自体は事実ですが,人間との比較に関しては何とも言えないですね.
② 診断結果の比較
以下の図は,医学系で有名な学術雑誌であるNew England Journal of Medicineを使った問題の結果です.

まずここで行われたタスクは,(AIまたは医師が)病歴を読んだ上で,病気の診断の候補を10(可能性の高いものから順に)挙げるというものです.
縦軸は正解率で,一番左側が,候補上位1番目だけでの正解率です.
右に行くほど, 候補を2, 3, 4, ..., 10番目まで含めた場合の正解率,となります.
色は,赤のPrior SoTAが過去の最高記録で,黄色のClinicianが医師です.
今回の青のMed-Geminiは医師をずいぶん上回っているというか,過去の記録の時点でも医師を上回っているように見えますが…
実はこれ, 人間に不利な条件かも しれないのです.
この人間のデータが取られた先行研究を見てみると,一般内科医20人と書かれています.
しかし問題のほうは,一般内科だけでなく神経内科,小児科,精神科と 他の専門分野も含まれている のです!
まぁ確かに,一般内科のクリニックにそのような患者さんが来ることもあるので, 間違いとは言えない のですが…
クリニックですぐに診断しなければいけない状況を想定すれば,今回の結果は妥当です.
現実的には,孤島の診療所などでしょうか(そのようなぴえんみの強い場面であれば,AIも使えたほうが良さそうです).
ですが多くの場合は,専門が異なる場合は自分では診断せず,他の病院に紹介するわけなので…
それぞれの 専門分野での正解率と比較しないと ,一般的な現場の診断の流れに即した比較はできません.
(AIが診断できるようになれば紹介も不要になるじゃん!と思うかもしれません.
しかしその場合,「専門の医師がいないなら,AIの診断結果の責任を取るのは誰になるの?」となってしまうのです…!)
直感的な意味でも,「医師とどちらが上回っているか」と言った時に,専門外の診断までさせる状況はあまりイメージしないんじゃないでしょうか.
かと言って,専門外の内容をやらせたことが確定する記載もなさそうです.
なので,この結果だけでは 正直何ともわからん という感じですね… 🙃
(ほんとのところは,分析や推測を重ねることで,もうちょっと白黒付けることも可能ではあります.
ですがそこまでいくと論文解説のレベルを超えてしまいますので,この記事では一旦ここまでとしておきます)
ちなみに,診断の候補を10も挙げるのって結構キツそうです…(笑)
参加された先生がたは大変おつかれさまです…!
③ 要約や紹介状などの比較
次の図は,要約や紹介状などを書いてみて人間と比較した結果です.

見た感じMed-Gemini(青)が圧勝そうには見えますね.
実際はどうなんでしょうか?詳細を紐解いていきましょう.
ここでのタスクは3つあります.
図の上から順に,
主訴・現病歴を要約すること
他院への紹介状を書くこと
医学研究のまとめ(ここではコクランという有名な情報源のもの)を一般人向けに説明し直すこと
これらにMed-Geminiと医師が挑戦し,その成果物同士を,複数の観点から医師が比較するというものです.
複数の観点については一旦置いておいて,まず先ほど判断困難な点であった「 専門分野外のタスクをやらされる 」については,今回はどうなのでしょうか?
まず「医学研究まとめを一般人向けに説明」のタスクは,元々の著者が既に用意してくれています.
これは明確に, 専門分野の人が担当 したと言えます.
だって本人だもーん.
他のタスクは明らかな記載がなさそうなのですが,
「他院への紹介状」については,どの患者さんの紹介状を書くかを医師が選んだとも読めるような記載があります.
また上の帯グラフを見てもらうと,数が25~31件と少ないので, 1人あたりの担当件数も少なそう です.文章を書くのは負担も大きいですしね.
このあたりを考えると,推測ではありますが, 得意な分野を担当 した可能性が濃厚そうです.
言い換えると,分野担当の観点では,人間とAIとで妥当な比較がされていそうだということになります.
話を戻して,書かれた要約や紹介状などの比較評価のための,複数の観点について…
複数に細分化された結果は,以下のようになっています.

正確さや網羅性,簡潔さなど様々な観点から評価してますね.
統計学的には「全体ではA優勢でも,実は部分ごとに見てみるとB優勢」みたいな不思議なことがたまにあったりするんですが,今回は観点ごとにわけてもそのような 逆転することはなさそう です.
(ちなみに1つ目と3つ目のタスクで,いい勝負になる観点が異なるのは興味深いですね.
本題からはそれるので詳細は割愛しますが,少なくとも人間側の書き手の属性が大きく異なっていた可能性が高いのと,詳細な評価基準がやや異なるのも影響しているかもしれません)
人間との比較まとめ
こう見てみると,Med-Geminiは要約や紹介状などの作成には強そうですが,医師国家試験や診断については何とも判断つきがたいですね~~~
あとは,「論文に例示されているMed-Geminiの具体的な応答を見て,人間の医師としての実感と比較する」というのも出来なくはないですが,
こういった具体例は,往々にして見栄えの良いものを恣意的に選んで掲載されるものですからね… 🙃
特に選択問題なんかは偶然正解することも十分あり得るわけです.
Med-Geminiが広く使えるようになれば独自での検証もできるのですが,まだ少し先になるでしょう.
いずれにせよ,AIは責任を取ることはできませんので…
AIに大部分を任せられるようになったとしても,最終判断を生身の医師が行うことはしばらく続くと思います!
(他にももちろん,「評価指標の数字を超えた徹底的な調査」「プライバシーや偏見への配慮」みたいなことも論文には書かれてます.
気になる人は読んでみてください)
連絡事項
間違いとか変なところとかあったらびしびしご指摘ください!
もし需要があるならもっと詳しく解説するよ
需要があるかは知りませんが,SNSやコメントで反応が良ければ,今回取り上げなかった部分も解説するかもです!
今回省略した部分をいくつか挙げておきますね.
AI vs 医師で脇道になった細部
その他の検証の内容いろいろ
仕組みの詳細
今後の展望について などなど…
医療AIビジネスなど興味あるかたはお気軽にご連絡を
Twitterからお気軽にご連絡どうぞ!
こちらは以下のようなものを提供できるかもしれません!
ビジネスモデルのデザイン
医療の現場に関する側面
患者さんに関する側面
最先端の研究についての知見
なるべく精度の高い医療AIを作る技術
なるべくコスパ良い医療AIを作る技術
プロンプト(chatGPTなどに人間が入力する言葉)のテクニック
コネクション
某上場企業(医師向け医療ITサービス)の社長や経営企画室
医療×AI×ブロックチェーンのスタートアップ創業者
大半の医学生に使われたITサービス創業者
この記事が気に入ったらサポートをしてみませんか?