
Googleが生み出した新しい大規模言語モデル「Gemma」の解説

2024年2月21日にGoogleがオープンモデル「Gemma」を発表しました。
モデルのアーキテクチャに興味を持ちましたが、解説するブログが見つからなかったため、このブログでまとめることにしました。
以下は、公式ブログ記事とテクニカルレポートです。
公式ブログ記事: Gemma: Introducing new state-of-the-art open models
https://blog.google/technology/developers/gemma-open-models/
テクニカルレポート: Gemma: Open Models Based on Gemini Research and Technology
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
GitHub:
https://github.com/google-deepmind/gemma
gemma.cpp: GemmaのC++言語による軽量な実装
https://github.com/google/gemma.cpp
Gemmaの概要
はじめに、「Gemma」の概要を簡単に振り返りましょう。「Gemma」はGoogleの技術者によって開発された言語モデルで、前バージョンの「Gemini」に倣い、軽量でオープンソース形式で提供されています。このモデルの名前はラテン語で「貴重な石」を意味する「gemma」から名付けられました。その名前が示すように、Gemmaは単にパラメータを提供するだけでなく、開発者を支援し、協力を促進し、Gemmaモデルの倫理的な使用を促すためのガイドラインとツールも提供しています。
Gemmaのポイントは以下の通りです。
Gemmaは、Gemma2BとGemma7Bの2つのサイズでモデルパラメータを公開しています。各サイズのモデルには、事前学習済みとインストラクションチューニング済みの2つの改良バージョンがあります。
Responsible Generative AI Toolkitは、Gemmaを使用してより安全なAIアプリケーションを作成するためのガイドラインとツールを提供します。 推論と教師ありファインチューニングは、JAX、PyTorch、TensorFlow、ネイティブKeras 3.0を含むすべての主要なフレームワークで行うことができるツールチェーンを提供します。
Hugging Face、MaxText、NVIDIA NeMo、およびTensorRT-LLMのようなツールが統合され、ColabとKaggleのノートブックが提供されているため、Gemmaの使用を簡単に開始できます。
事前学習済みモデルとインストラクションチューニング済みモデルは、ラップトップやGoogleクラウド上で簡単に実行し、Vertex AIおよびGoogle Kubernetes Engine (GKE)に容易にデプロイできます。
複数のAIハードウェアプラットフォームでの最適化により、NVIDIA GPUやGoogle Cloud TPUを含む業界をリードするパフォーマンスを実現しています。
利用規約では、組織の規模に関わらず、すべての組織が責任を持って商業利用および配布を行うことが許可されています。
これらの事項について詳しく知りたい方は、公式ブログおよび関連記事をご参照ください。
モデルアーキテクチャ
Gemmaのモデルは、入力テキストをそれぞれの分散表現にマッピングした後、Transformerモデルのデコーダーを使用して出力テキストにマッピングします。
入力テキストを分散表現にマッピングするとは、テキスト中の各単語を個別のベクトル表現に変換することを意味します。公式の技術報告書にはその具体的な方法についての記載はありませんが、このプロセスにはword2vecなどの手法が用いられていると推測されます。
Gemmaモデルのデコーダーでは、Transormerモデルのデコーダーが使用されています。Transformer[4]とは、単語からなるシーケンスを入力とし、対応するシーケンスを出力する機械学習モデルです。このモデルはSeq2Seq(シーケンス対シーケンス)モデルと呼ばれ、2017年に、論文「Attention is All You Need」にてGoogle Brainの研究者らによって提案されました。Transformerの核心機能である自己注意機構は、モデルが入力シーケンスの全ての単語(またはトークン)を同時に考慮することを可能にします。従来のRecurrent Neural Network (RNN) ベースのモデルでは、シーケンスを順番に一つずつ処理していく必要があり、この逐次的な処理は計算の並列化を困難にしていました。それに対して、Transformerでは、シーケンス内の各位置のトークンが独立して他の全てのトークンとの関係を計算できるため、これらの計算を同時に実行できます。
この特性は、特に大規模なデータセットを用いた学習において、顕著な効率化をもたらします。具体的には、自己注意機構によって、入力シーケンス内の全ての単語間の依存関係を一度に捉えることができるため、各単語を独立した計算単位として扱うことができます。これにより、モデルはデータのバッチを複数のプロセッサやGPU上で同時に処理することが可能になり、学習プロセスの高速化が実現されます。
さらに、Transformerモデルはこの並列処理能力を活かして、より大規模なテキストデータセット上での学習が可能になります。これは、モデルがシーケンス内の情報をより効率的に捉え、複雑な言語パターンや長距離の依存関係を理解する能力を向上させることに寄与します。結果として、Transformerは機械翻訳、テキスト生成、要約といった多様な自然言語処理タスクにおいて優れた性能を発揮することができます。
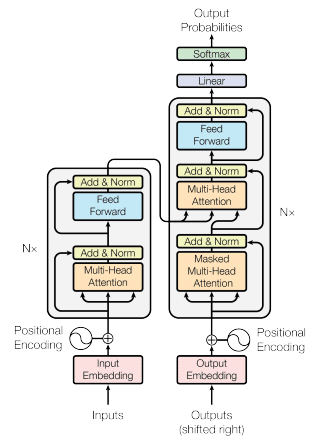
Gemmaモデルは、デコーダーとしてTransformerモデルのデコーダーを使用しており、以下の改良を加えています。
Multi-Query Attentionの導入
RoPE Embeddingの採用
GeGLU Activationの利用
Normalizer Locationの追加
ブログの残りの部分で、これらの改良点について詳しく解説します。
Multi-Query Attentionの導入
Multi-Query Attention[5]は、特にTransformerモデルやそれに類する深層学習アーキテクチャで使用される、自己注意機構の一種です。従来の自己注意機構では、入力シーケンスの各要素が他のすべての要素との関係を計算し、それに基づいて出力シーケンスを生成します。このプロセスは「クエリ」、「キー」、「バリュー」の3つのコンポーネントによって行われます。各入力要素に対して、クエリと他のすべての要素のキーとの間の類似度が計算され、その類似度に基づいてバリューが重み付けされ、最終的な出力が生成されます。
クエリ$${Q}$$、キー$${K}$$、バリュー$${V}$$の3つのベクトルに対して、これらは、入力ベクトル$${X}$$に対する線形変換によって得られます。
$${Q=XW^Q}$$
$${K=XW^K}$$
$${V=XW^V}$$
ここで、$${W^Q}$$、$${W^K}$$、$${W^V}$$はそれぞれクエリ、キー、バリューに対する重み行列です。
自己注意機構の出力は、クエリとキーの類似度を計算し、それに基づいてバリューを重み付けすることで計算されます。
類似度スコアは、通常、スケーリングされたドット積を用いて以下のように計算されます。
$${Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V}$$
ここでは、$${d_K}$$はキーベクトル$${K}$$の次元です。
Multi-Query Attentionでは、この概念をさらに進めて、各入力要素に対して複数のクエリを同時に生成します。クエリ、キー、バリューの各ベクトルは同様に生成されますが、クエリに関しては、複数の異なる重み行列$${W^{Q_i}}$$を用いて複数のクエリ$${Q_i}$$が生成されます。
$${Q=XW^{Q_i}}$$
$${K=XW^K}$$
$${V=XW^V}$$
各$${Q_i}$$に対して、上記の自己注意の式を使用して、複数の出力が計算されます。
$${Attention(Q_i, K, V) = softmax(\frac{Q_iK^T}{\sqrt{d_k}})V}$$
これにより、同じ入力データから複数の異なる特徴やアスペクトを捉えることができます。
最終的な出力は、これらの複数の注意出力を結合または統合することにより得られます。これにより、同一の入力に基づいて複数の異なる表現や特徴を同時に抽出することが可能になります。これは、モデルがより複雑で多様なデータの関係性を捉えるのに役立ち、特に多次元的な情報を扱うタスクでの性能向上が期待できます。
RoPE Embeddingの採用
RoPE (Rotary Position Embeddings)[6]は、Transformerモデルにおける位置情報の取り扱いに関する技術です。従来の位置エンコーディング(Positional Encoding)や位置埋め込み(Positional Embeddings)では、シーケンス内の各位置に対して固有のベクトルを加算または結合することで位置情報を提供していました。これにより、モデルは入力シーケンスの順序情報を学習することが可能になります。
RoPEは、Positional Encodingの改良版で、各位置の埋め込みを元のトークンの埋め込みと回転させることで、位置情報を組み込む方法です。
位置$${p}$$と埋め込みベクトル$${x}$$に対して、ロータリー埋め込みは以下の行列$${R}$$を用いて回転を適用します。
ここで、$${\omega}$$は回転の周波数を制御するパラメータです。この行列は、位置$${p}$$における2次元の回転を表しています。実際には、トークンの埋め込みベクトル$${x}$$は多次元であるため、この操作を埋め込みの各次元ペアに対して適用します。
$${R(p) = \begin{bmatrix}cos(p\omega) & -sin(p\omega) \\ sin(p\omega)& cos(p\omega)\end{bmatrix}}$$
次に、RoPEを使用して位置情報を組み込んだ埋め込みベクトル$${x’_p}$$は、元の埋め込みベクトルxに$${R(p)}$$を適用することで得られます。
$${x’_p=R(p)\cdot x}$$
この回転操作により、位置情報がトークンの埋め込みにより密接に組み込まれ、モデルがより効果的に位置情報を利用できるようになります。特に、RoPEは自己注意機構(Self-Attention Mechanism)内での位置関係のモデリングを直接的に改善し、シーケンスの長さに関係なく一貫した性能を提供することができます。
GeGLU Activationの利用
GeGLU(Gated Linear Unit)[7]は、ニューラルネットワークの性能を向上させるために使用される活性関数の一種です。
GeGLUでは、入力$${x}$$に対する活性関数を次のように計算します。
$${GeGLU(x) = x \cdot \sigma(W_gx + b_g)}$$
ここでは、$${W_g}$$は重み行列、$${b_g}$$はバイアス項、$${\sigma}$$はシグモイド関数です。
従来のReLUに比べて、ゲート機構を用いることで計算は複雑になりますが、その分表現力が高く、優れた性能が得られることで知られています。
Normalizer Locationの追加
Gemmaモデルの各層の出力をRMSLayerNorm(Root Mean Square Nomalization)[8]で正規化します。RMSLayerNormにより、各層の出力を正規化することで、学習プロセスを安定にすることができます。
RMSLayerNormの次のように計算できます。ある層の活性化を$${x}$$とします。
各特徴x_iに対する平均$${\mu}$$と$${\sigma_{rms}}$$を計算します。
$${\mu = \frac{1}{N} \sum_{i=1}^{N} x_i}$$,
$${\sigma_{rms} = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 + \epsilon}}$$,
ここで、$${N}$$は特徴の数、$${\epsilon}$$は数値的安定のために加えられる定数です。
次に、正規化された活性化$${x’_i}$$は次の式で計算します。
$${x_{i}^{'} = \frac{x_i - \mu}{\sigma_{rms}}}$$
最後に、学習可能なパラメータであるスケールパラメータ$${\gamma}$$とシフトパラメータ$${\beta}$$を使って出力$${y_i}$$を調整します。
$${y_i = \gamma x’_i+\beta}$$
ここで、$${\gamma}$$と$${\beta}$$は学習によりえられる重みパラメータです。
このプロセスを通じて、RMSLayerNormは各層の出力を正規化し、モデルの学習を安定化させることができます。
参考文献
[1]公式ブログ記事: Gemma: Introducing new state-of-the-art open models
https://blog.google/technology/developers/gemma-open-models/
[2]テクニカルレポート: Gemma: Open Models Based on Gemini Research and Technology
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
[3]テクニカルレポート: Gemini: A Family of Highly Capable Multimodal Models
https://arxiv.org/abs/2312.11805
[4] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin: Attention Is All You Need,
arXiv:1706.03762
[5] Shazeer: Fast transformer decoding: One writehead is all you need. CoRR, abs/1911.02150, 2019.
https://arxiv.org/abs/1911.02150
[6]J. Su, Y. Lu, S. Pan, B. Wen, and Y. Liu. Roformer: Enhanced transformer with rotary position embedding. CoRR, abs/2104.09864, 2021. https://arxiv.org/abs/2104.09864.
[7] Noam Shazeer: GLU variants Improve Transformer, arXiv:2002.05202
https://arxiv.org/abs/2002.05202
[8] B. Zhang and R. Sennrich. Root mean square layer normalization. CoRR, abs/1910.07467, 2019.
http://arxiv.org/abs/1910.07467.
この記事が気に入ったらサポートをしてみませんか?