
[翻訳] GTOソルバーの仕組み by Tombos21 (GTO Wizard)

ポーカーの勉強をする時にGTO Wizardなどでソリューション(ソルバーの出力結果)を見ながら、GTOの勉強をしている方も多いと思いますが、そもそものソルバーの仕組みを理解することで、ソリューションをより正しく読み解くことができるようになると思います。
GTO Wizardのブログは質が高くて有益な記事が多いですが、その中から、今回はTombos21による「ソルバーの仕組み」に関する記事を取り上げて翻訳します。

ソルバーの仕組み
How Solvers Work - GTO Wizard Blog (2023/1/23)
GTOソルバーは実現しうる最善のポーカー戦略を計算するためのアルゴリズムです。しかし、具体的にソルバーはどのような仕組みなのでしょうか。なぜその戦略が「最善」と言えるのでしょうか。
この記事では、ソルバーの仕組み、ソルバーにできること、ソルバーの限界について深掘りしていきます。
GTOのゴール
GTOの目的は、エクスプロイト不可能なナッシュ均衡戦略を実現することです。
ナッシュ均衡 (Nash Equilibrium) とは、どのプレイヤーも一方的に戦略を変更したところで、それ以上プレイが改善されない状態のことです。これは、つまり各プレイヤーが自身の戦略を公開しても、相手プレイヤーに戦略を変更するインセンティブが生まれないことを意味します。ポーカー戦略における聖杯*のように言われることもありますが、実際にはソルバーはそのように設計されていません。事実、ソルバーはナッシュ均衡が何かを理解していません。
(*訳注: Holy Grail - 聖杯。人々が追い求める至高の目標のこと)
ソルバーはただEVを最大化するアルゴリズムである。
ソルバーでは、エージェントというのが一人のプレイヤーに相当します。そのプレイヤーのゴールはただ一つ、金を最大化することです。問題はもう一方のエージェントも完璧にプレイできるということです。このエージェント同士をそれぞれの戦略で戦わせると、繰り返し、繰り返し、相手の戦略をエクスプロイトし合いながら、どちらもそれ以上プレイを改善することができない地点に到達します。それが均衡です。
GTOは、相手をエクスプロイトするアルゴリズム同士を戦わせ、どちらもそれ以上プレイを改善することができなくなるまで続けることで実現される。
GTOを導き出す方法
各プレイヤーへ、均一にランダムな戦略を割り当てる。(各意思決定ポイントにおける各アクションの頻度が等しい戦略)
ゲームツリー全体における各ハンドの後悔 (regret) を計算する。後悔とは、相手の現行の戦略に対するEVロスのこと。
後悔を減らすように自身の戦略を変更する(相手の戦略は変更されない前提で)。
2点目に戻って、後悔を再計算し、今度はもう一方のプレイヤーの戦略を後悔が減るように変更する。
これをナッシュ均衡に至るまで繰り返す。
このサイクルは、反復 (iteration) と呼ばれる。ツリーの大きさやサンプリング方法によって、必要な反復回数は数千回から数十億回にものぼる。
Step 1) ゲーム空間を定義する。
[インプット]
ポーカーはそのまま解析するには複雑すぎるため、サブセットと抽象化によって計算可能なところまでゲーム空間を減らす必要があります。
一般的に、ソルバーを作動させるためには以下のパラメータを定義する必要があります。
ベッティングツリー
求める精度
開始時点のポットサイズとスタックサイズ
開始時点のレンジ(ポストフロップソルバーの場合)
ボードのカード(ポストフロップソルバーの場合)
ポストフロップカードの抽象化(プリフロップソルバーの場合)
レーキやICMなどの関数の修正
[ベッティングツリーの複雑性]
ゲームツリーを減らすために、利用するベットサイズを指定する必要があります。アルゴリズムの話をする前に、ベッティングツリーがどのようなものか見てみましょう。
ソルバーはあなたが設定したパラメーターに基づいて動作します。ソルバーに非常にシンプルなゲームツリーを設定すれば、より複雑性の低い戦略を生成することができますが、ソルバーはそのゲームツリーにおける制限をエクスプロイトしてくる、ということに留意してください。
ソルバーは設定されたベット構造の範囲内で取りうるすべてのラインを含むよう "ツリー" を生成します。ツリー全体の中の各意思決定ポイントが "ノード" です。例えば、OOPが1/3ポットサイズベットに直面した時、それがひとつの "ノード" となります。ツリーの中のノードの数こそが、そのツリーの大きさです。その各ノードにおいて最適化が実行されます。
以下のような極端にシンプルなツリーでも、 最適化されなければいけないノードが696,613個あります。
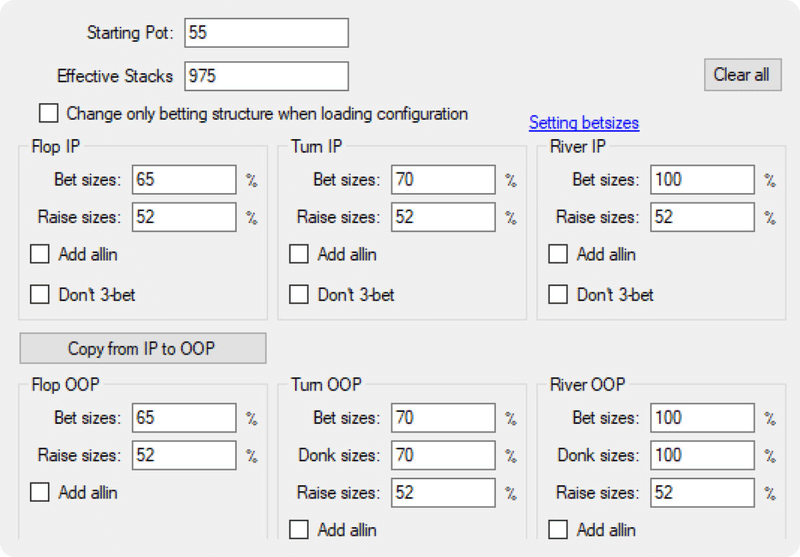
以下のGTO Wizardが使っているような、より複雑なツリーであれば、ノードの数は最大87,364,678個になります。
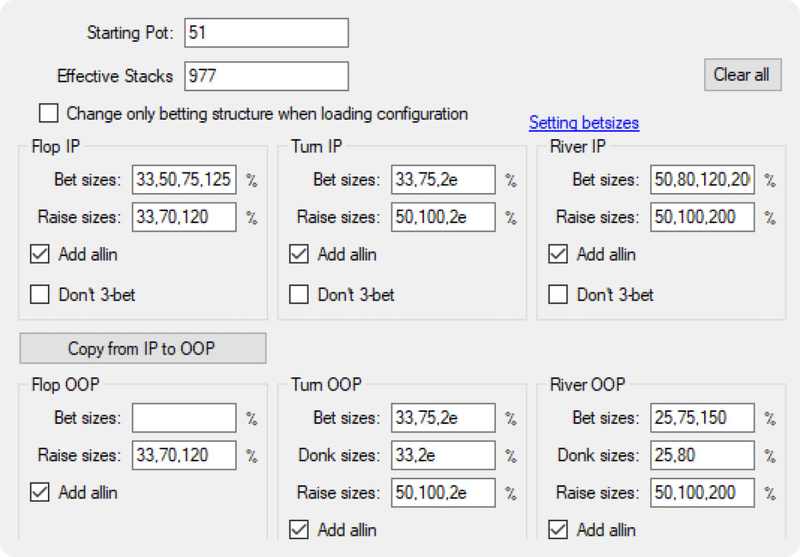
このように、ツリーの複雑さは指数関数的に増します。上記の複雑なツリーのように、各ノードで使われるサイズ数が4、5倍になると、ツリーは125倍大きくなり、解く難易度が上がります。しかし、これでも真のゲーム空間を大幅に単純化したものです。
ソルバーの最も難しい問題は、現代の技術的制約の中で、どのようにベッティングツリーを最適化しながら、まともな戦略を生成するか、です。ソルバーが解ける範囲でしか、ツリーを大きくすることができません。また、ツリーの制限がソルバーのエクスプロイトされない範囲でしか、ツリーを小さくすることもできません。
GTO Wizardは、ポーカーを学びやすくするために、簡略化したベッティングツリーを見つけるアルゴリズム開発に取り組んでいます。これらのソリューションはすべてのスポットでベストなサイズを見つけられるでしょう。
GTO Wizardは様々な異なるタイプのソリューションを提供しています(最大19のサイズを持つ複雑なソリューションから、数サイズのみのシンプルなソリューションまで)。最終的に、まずは複雑なツリーから始めて、そのあと頻度の低いラインを取り除くことで、より扱いやすくて小さいツリーにするのがよいことがわかりました。
[ノードロック]
ノードロックはエクスプロイト戦略の探索や、その根底にある原因と結果の原則について探索するために使われる非常に強力な機能です。
ノードロックは、ゲームツリー内の特定のノードにおいて、あるプレイヤーの戦略を固定する手法です。そのプレイヤーに特定の方法でプレイすることを強制することができます。ノードロックはよくエクスプロイト戦略を開発するために使われます。例えば、強制的にフロップでレンジベットをさせた場合、対するプレイヤーはその戦略を最大限エクスプロイトします。
注意点として、そのロックしたノードに対応するために、両プレイヤーともそのノード前後でアジャストを行うことを忘れないようにしましょう。つまり、ターンとリバーの戦略が変更されるのです。
ソルバーに下手なプレイを強制した時、そのダメージを最小限にするため、ソルバーはそのノードの前後で修正を行う。
単一のノードをロックして、その欠陥をソルバーに回避させる処理を "最小エクスプロイト戦略 (minimally exploitative strategy)" と呼びます。ツリー全体に存在するリークではなく、ツリーの中の特定のポイントだけをモデル化します。
より複雑なノードロックも可能です。例えば、あるノードで特定のコンボの戦略だけをロックすることができるソルバーもあります(他のコンボの戦略をアジャストする)。あるいは、相手のより大きなトレンドを再現してエクスプロイトするために複数のノードをロックすることも可能です。ただし、現代のツールはまだマルチストリートのノードロックを効果的に扱うことができません。
Step 2) ゲームツリーを解く。
ゲームツリーの定義ができました。いよいよ、これを解いていきます。そのためにまず、ソルバーがどのようにして戦略のEVを計算しているのかを理解しなければいけません。
EV(期待値)の計算方法
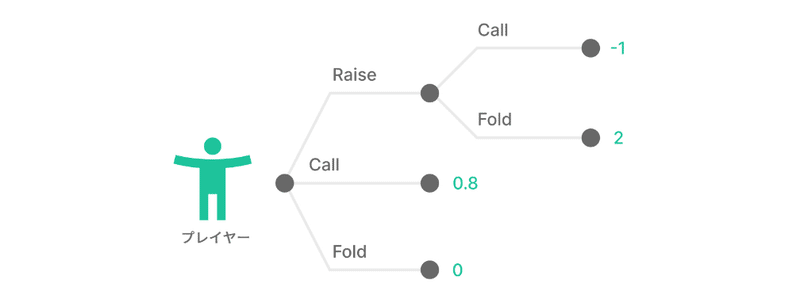
上記のゲームツリーを見てみましょう。各ドットはノード、つまり意思決定ポイントを表しています。各ノードにおいて各ハンドがどれだけのEVを生み出すか、どのように知ることができるでしょうか。
このプロセスは(コンピューターにとっては)単純です。まず、ゲームの終結点に当たる終端ノード (terminal node または leaf node) を定義します。これらは、どちらかがフォールドするか、ショーダウンに至るかによって、ハンドが帰結する点です。
各終端ノードには、確率 (p) と値 (x) が割り当てられます。レンジ内の各ハンド (i) は、それぞれの終端ノードに至る確率と値を持ちます。各終端ノードの確率と値を掛けて、足し合わせることで合計のEVを算出します。
各ノードの値は、勝った時のポット合計から、そのポットに投入した金額を引いたもの、と定義されます。
ある戦略のペアから始める。
自身の戦略と相手の戦略に基づき、我々のハンドは各終端ノードに p の頻度で到達する。
各終端ノードの値は x である。
各ノードの x*p を合計し、我々のEVを求める。
この計算をすべてのノード、すべてのハンドで行う。
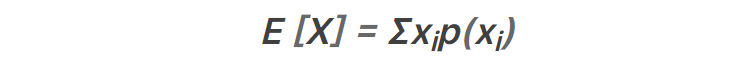
p(xi) = Xが取る値 xi が起こる確率
ソルバーはこの計算をほとんど瞬時に行うことができます。ソルバーが登場する以前は、CREVのようなプログラムでEVを計算していました。その頃の問題は、ユーザーが各ノードの戦略を定義しなければいけないことでした。そのため、よく後続のノードを純粋なエクイティの計算に置き換えることで減らしていましたが、これは極めて精度が低いものでした。
GTO Wizardでは、すべての時点で、すべてのハンドのEVを見ることができます。例えば、こちらはBTN vs BB SRP - NL50キャッシュゲームです。ドロップダウンでストラテジーを選択すると、各ハンドの全体EVが表示されます。各ハンドにカーソルをホバーさせると、各ハンドが取りうる様々なアクション別のEVが表示されます。
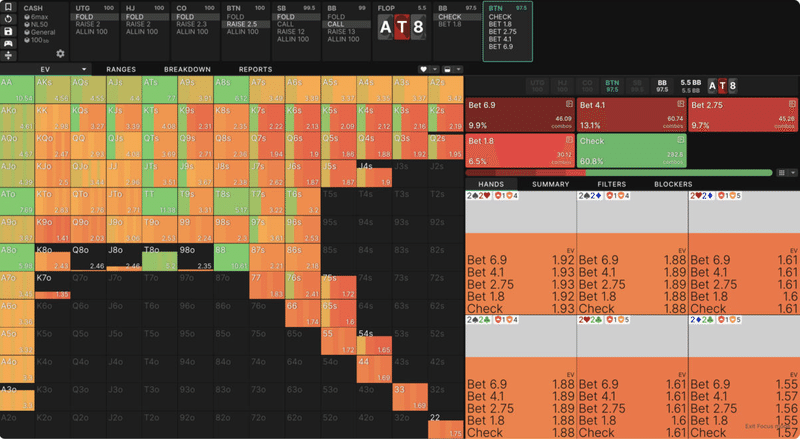
後悔とは
まずは、相手の戦略は固定されている(変化しない)ものと仮定します。次に、ゲームツリー全体にある各ノードで、ハンドが取りうるすべてのアクションに対して、上の図のようにEV計算を行います。そして、各点において最もEVが高い意思決定を選び、最初の意思決定ポイントから様々なアクションのEVを計算するために、これを終端ノードからさかのぼります。
さて、各ノードでの各ハンドの値がわかりました。では、どうやって戦略を改善させればよいでしょうか。ここで後悔 (Regret) という概念が登場します。
後悔を最小化するというのは、すべてのGTOアルゴリズムの基本です。最も有名なアルゴリズムは、CFR (Counterfactual regret minimization) と呼ばれています。Counterfactual regretとは、ある戦略をとらなかった時の後悔の大きさを指します。例えば、フォールドした後で、コールするほうが良い戦略だったと気づいた時、コールしなかったことを "後悔" します。数学的には、ある意思決定ポイントにおけるそのハンドの戦略全体と比較し、あるアクションを取ることの得失を計測します。

例えば、私たちのハンドの戦略がそれぞれ1/3の頻度でフォールド、コール、オールインだったとします。またそれぞれのアクションのEVが、フォールド=0bb、コール=7bb、オールイン=5bb だった場合、私たちの戦略のEVは以下となります。
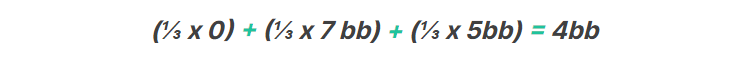
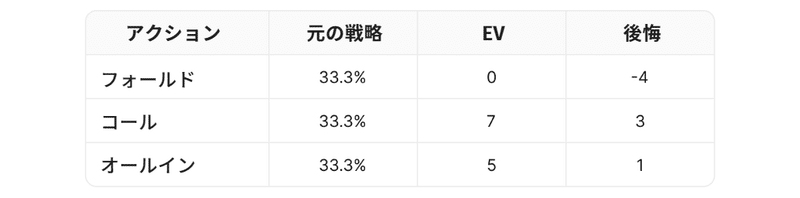
フォールドは後悔がマイナスであり、当戦略の平均値より多く負けることを意味する。
コールとオールインの後悔はプラスであり、当戦略の平均値よりもパフォーマンスが高いことを意味する。
次のステップは、後悔を最小化するために戦略に変更を加えることです。
一番わかりやすいやり方は、単純に各意思決定ポイントにおいて全てのハンドで、最もEVが高いアクションを選ぶことです(maximally exploitative strategyと呼ばれる)。上記の例で言えば、常にコールをすることです。問題は相手も戦略を変更できるということで、これによってループにはまってしまいます。
例えば、プレイヤーAはリバーでブラフ過少なので、プレイヤーBはブラフキャッチャーをすべてフォールドします。すると、プレイヤーAはリバーで常にブラフするようになり、今度はプレイヤーBはブラフキャッチャーはすべてコールします。すると、プレイヤーAはリバーでブラフを止めて…、これを永遠に繰り返してしまいます。
そこで、相手への対応すべてを一気に切り替えるのではなく、その方向へ一歩ずつ、徐々に戦略をアジャストしていくのです。こうすることでループにはまる問題から抜け出し、双方の戦略はスムーズに均衡へと収束していくのです。
戦略を更新するために、CFRを使うこともできます。先ほどの例に戻りましょう。後悔の値がマイナスだったアクションはすべて選択することをやめます。後悔の値がプラスだったアクションで、次の等式を使います。

先ほどの例で言えば、こちらのようになります。
コール頻度 → 3/(3+1) = 75%
オールイン頻度 → 1/(3+1) = 25%
フォールド頻度 → 0% (後悔の値がマイナスのため)
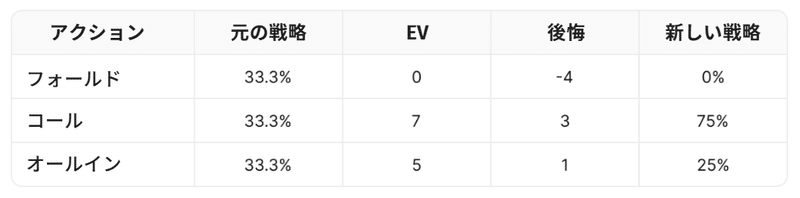
元の戦略のEV = 4.0
新しい戦略のEV = 6.5
まだこれで、反復は1回です。この処理を何度も繰り返すことで、戦略はどちらもそれ以上改善できないポイントに到達し、ナッシュ均衡を実現するのです。
精度とは
ソリューションの精度はナッシュ距離 (Nash Distance) によって測定されます。それは次の問いから始まります。
プレイヤーAは、プレイヤーBの現行の戦略を最大限エクスプロイトした場合、どれだけ勝つことができるだろうか?
この質問はコンピューターであれば、後悔を計算できるため、簡単に知ることができます。プレイヤーAの現行戦略のEVと、最大限エクスプロイトした場合の戦略のEVの差がナッシュ距離です。ナッシュ距離の数値が小さいほど、エクスプロイトされにくく、精度の高い戦略ということになります。
すべてのプレイヤーのナッシュ距離の平均を取ることで、そのソリューションの精度を求められる。
この正確なナッシュ距離の測定方法は、反復を行うたびに戦略全体を列挙している場合にのみ行うことができます。ほとんどのプリフロップソルバーは抽象化やサンプリング法を用いるため、この計算方法は非現実的で不正確になります。HRCやMonkerのようなソルバーは、反復のたびに戦略や後悔がどれくらい変化するかを測定することで、収束を推定しています。
GTO戦略というのは、ナッシュ距離がポット1%以下になると均衡へと収束し始めます。このしきい値より大きいと、戦略は極端に複雑で信頼度が低くなる傾向にあります。ほとんどのプロは、ナッシュ距離がポット0.5%より大きいソリューションは受け入れられないと言います。GTO Wizardの場合、ソリューションタイプによりますが、開始時点のポットの0.1~0.3%の精度で提供しています。
ゲームツリーがより複雑になると、近いベットサイズ間の差を明確にするため、より高い精度が求められます。似たサイズは似た利得になるため、多くのベットサイズを含む複雑なゲームツリーは、収束するためにより高い精度が必要になるのです。
凸型利得空間
(Convex payoff space)
この反復作業がうまく機能することをどのように確認できるでしょうか。局所的な最大値 (local maximum, 極大値) に陥ることはないでしょうか。一般的に、ポーカーは双線形鞍点問題 (bilinear saddle point problem) と表現され、利得を表す空間は下の画像のようになります。
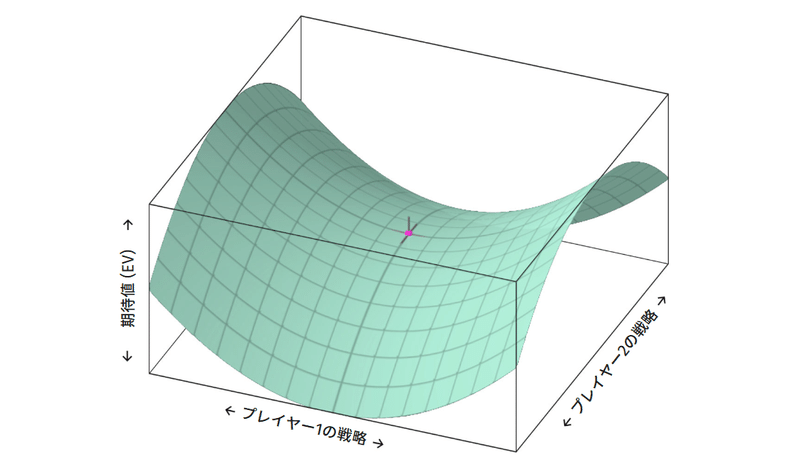
x軸とy軸は、戦略のペアを表します。戦略ペアは、両プレイヤーがすべてのスポットのすべてのランアウトで、自身のレンジ全体をどうプレイするかという情報を含んでいます。
高さ (z軸) は、その戦略ペアのEVを表します。高い点ほど一方のプレイヤーのEVが有利であることを意味し、低い点ほどもう一方のプレイヤーのEVが有利であることを意味します。
ほとんどのソルバーは Counterfactual Regret Minimization (CFR) と呼ばれる処理を用います。このアルゴリズムは、アルバータ大学のMartin Zinkevichによる論文によって2007年に初めて公開されました。その論文は、CFRアルゴリズムが局所的最大値に陥ることなく、十分な時間をかければ、均衡に到達できることを証明しました。
この曲面の中央がナッシュ均衡を表します。このグラフ上で曲率のない点は、どちらのプレイヤーも戦略を変更したところで利得を増やすことができないことを意味します。
まとめ
主要なポイントをまとめます。
主なポイントとして、ソルバーとは、ユーザーが設定したゲームツリーの中で、EVを最大化するアルゴリズムである。
ソルバーのアルゴリズムは最大エクスプロイト戦略を生成する。ソルバー同士を戦わせることで、エクスプロイト不可能な均衡戦略が生成される。
戦略のペアのEV計算自体は(コンピューターにとっては)簡単である。戦略を正しい方向へ導き、数え切れないほど繰り返しこの処理を繰り返すところが、困難な部分である。
ポーカーはそのまま解くには複雑すぎるため、ベットサイズの制限等の抽象化テクニックによってゲーム空間を簡略化しなければいけない。
ソルバーの精度は、ユーザーによって設定された抽象度に依存する。複雑すぎると、解析不可能かつ人間に学べるものではなくなる。単純すぎると、ゲームツリーの制限をソルバーがエクスプロイトする結果となる。
Source: How Solvers Work | GTO Wizard
翻訳は以上です。読んで頂いてありがとうございました!
この翻訳noteは、皆様からのリアクションがモチベーションになっています。ぜひスキ・フォロー・拡散・投げ銭で応援して頂けると嬉しいです。
※以下の有料部分には何も書かれておりません。
ここから先は
¥ 300
スキ・拡散・サポートで応援して頂けるととても助かります。サポートは100円でもいいです。先に言っておきますが、ありがとうございます。