vast.AIでDart V2でイラストを3万枚(目標)作成し、HuggingFaceに自動アップロード

上記の記事のほぼパクリですが自分用メモで!
ControlNet学習用の画像が3万枚ほど欲しくなったので(そんな日もありますよね)ランダム生成することにしました。
しかし3万枚もローカル生成するとなると爆音による安眠妨害もいいところなので、レンタルGPU鯖を使うことにしました。
そんな感じの自分向け備忘録です。
2024/05/17追記
考えてみればprompt生成の部分はローカルでやってもいいと思ったので一部手順やコードを書き換えています
2024/05/18追記
sd-scriptsを使った方最適化されていて早くね?と思ったのでその手順に書き換えました。
①ローカルでprompt作成
レンタルGPU上でもできますがもったいないので。
python -m venv venv
venv\Scripts\activate
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
pip install transformerskohyaさんのコードを改造
https://gist.github.com/kohya-ss/1711f17fe77def811fcaf82877b0bec2
ここらへんは趣味で改造してください。
promptGEN.py
import os
import sys
import random
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def get_prompt(model, num_prompts, rating, aspect_ratio, length, first_tag):
prompt = f"<copyright></copyright><character></character>{rating}{aspect_ratio}{length}<general>{first_tag}"
prompts = [prompt] * num_prompts
inputs = tokenizer(prompts, return_tensors="pt").input_ids
inputs = inputs.to("cuda")
with torch.no_grad():
outputs = model.generate(
inputs,
do_sample=True,
temperature=1.0,
top_p=1.0,
top_k=100,
max_new_tokens=128,
num_beams=1,
)
decoded = []
for i in range(num_prompts):
output = outputs[i].cpu()
tags = tokenizer.batch_decode(output, skip_special_tokens=True)
prompt = ", ".join([tag for tag in tags if tag.strip() != ""])
decoded.append(prompt)
return decoded
def generate_prompts(model, output_file_path, NUM_PROMPTS_PER_VARIATION, BATCH_SIZE):
random.seed(42)
prompts = []
# 設定:寸法、アスペクト比、評価など
DIMENSIONS = [(1024, 1024), (1152, 896), (896, 1152), (1216, 832), (832, 1216), (1344, 768), (768, 1344), (1536, 640), (640, 1536)]
ASPECT_RATIO_TAGS = [
"<|aspect_ratio:square|>",
"<|aspect_ratio:wide|>",
"<|aspect_ratio:tall|>",
"<|aspect_ratio:wide|>",
"<|aspect_ratio:tall|>",
"<|aspect_ratio:wide|>",
"<|aspect_ratio:tall|>",
"<|aspect_ratio:ultra_wide|>",
"<|aspect_ratio:ultra_tall|>",
]
RATING_MODIFIERS = ["safe"]
RATING_TAGS = ["<|rating:general|>"]
FIRST_TAGS = ["no humans, 1other", "no humans, scenery", "1girl", "1boy"]
YEAR_MODIFIERS = [None, "newest", "recent", "mid"]
LENGTH_TAGS = ["<|length:very_short|>", "<|length:short|>", "<|length:medium|>", "<|length:long|>", "<|length:very_long|>"]
QUALITY_MODIFIERS_AND_AESTHETIC = ["masterpiece", "best quality", "very aesthetic", "absurdres"]
NEGATIVE_PROMPT = "nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, abstract"
# プロンプトの生成ループ
for rating_modifier, rating_tag in zip(RATING_MODIFIERS, RATING_TAGS):
negative_prompt = NEGATIVE_PROMPT
if "nsfw" in rating_modifier:
negative_prompt = negative_prompt.replace("nsfw, ", "")
for dimension, aspect_ratio_tag in zip(DIMENSIONS, ASPECT_RATIO_TAGS):
for first_tag in FIRST_TAGS:
dart_prompts = []
for i in range(0, NUM_PROMPTS_PER_VARIATION * len(YEAR_MODIFIERS), BATCH_SIZE):
length = random.choice(LENGTH_TAGS)
dart_prompts += get_prompt(model, BATCH_SIZE, rating_tag, aspect_ratio_tag, length, first_tag)
num_prompts_for_each_year_modifier = NUM_PROMPTS_PER_VARIATION
for j, year_modifier in enumerate(YEAR_MODIFIERS):
for prompt in dart_prompts[j * num_prompts_for_each_year_modifier : (j + 1) * num_prompts_for_each_year_modifier]:
prompt = prompt.replace("(", "\\(").replace(")", "\\)")
quality_modifiers = random.sample(QUALITY_MODIFIERS_AND_AESTHETIC, random.randint(0, 4))
quality_modifiers = ", ".join(quality_modifiers)
qm = f"{quality_modifiers}, " if quality_modifiers else ""
ym = f", {year_modifier}" if year_modifier else ""
image_index = len(prompts)
width, height = dimension
rm_filename = rating_modifier.replace(", ", "_")
ym_filename = year_modifier if year_modifier else "none"
ft_filename = first_tag.replace(" ", "")
image_filename = f"{image_index:08d}_{rm_filename}_{width:04d}x{height:04d}_{ym_filename}_{ft_filename}.webp"
final_prompt = f"{qm}{prompt}, {rating_modifier}{ym} --n {negative_prompt} --w {width} --h {height} --f {image_filename}"
prompts.append(final_prompt)
# ファイルに出力
with open(output_file_path, "w") as f:
f.write("\n".join(prompts))
print(f"完了しました。{len(prompts)}個のプロンプトが{output_file_path}に書き込まれました。")
if __name__ == '__main__':
if len(sys.argv) != 3:
print("Usage: python script.py <model_name> <output_file_path>")
else:
MODEL_NAME = sys.argv[1]
output_file_path = sys.argv[2]
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, torch_dtype=torch.bfloat16)
model.to("cuda")
NUM_PROMPTS_PER_VARIATION = 60
BATCH_SIZE = 8
generate_prompts(model, output_file_path, NUM_PROMPTS_PER_VARIATION, BATCH_SIZE)promptGEN.py <モデルの名前/PATH> <出力先>【具体例】
python promptGEN.py "D:/LLM/dart-v2-moe-sft" "E:/desktop/dart_prompts.txt"上記のようにして作られたpromptが以下になります。
②huggingfaceの設定
新しいデータセットのリポジトリを作成
なら『tori29umai/dart_img』を控えておく。
次にアクセストークンを発行。書きこみ権限の方を控えておく。
一応NSFW画像が生成される事故に備えて、Not-For-All-Audiencesタグをつけておくといいでしょう。
③Vast.aiレンタル
まずvast.AIで適当な鯖をレンタルします。この手順は割愛。こんなマニアックなことやりたい奇特な人は自分で調べられるやろ(慢心
適当にここら辺借りておきます。

④インスタンスを開く
OPENをクリック

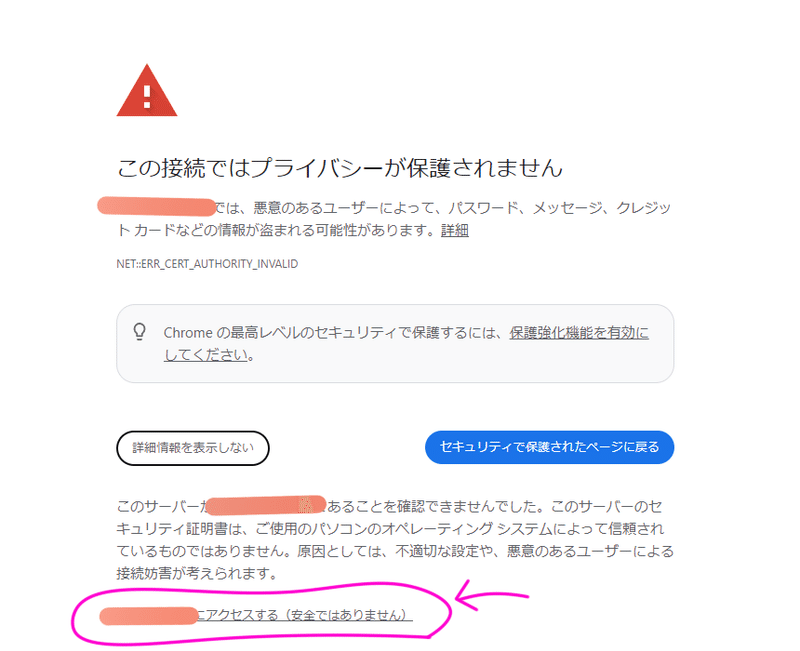
セキュリティーに怒られるので、詳細情報を表示し、〇〇にアクセスする(安全ではありません)をクリックする
⑤Terminalを開く
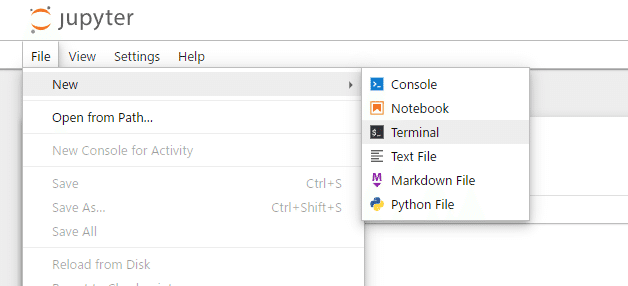
以下のコマンドを一行ずつ実行
torchはあらかじめイメージにインストールされていましたが最新版にしてよ!みたいな警告がでたのでそっちにしました。
git clone -b dev https://github.com/kohya-ss/sd-scripts.git
cd sd-scripts
pip3 install --upgrade torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
pip install -U xformers
pip install --upgrade -r requirements.txt
pip install bitsandbytes==0.41.1
pip install scipy
pip install wget
sudo apt-get update
sudo apt update
sudo apt install git-lfs
git lfs install
sudo apt-get install libgl1-mesa-glx -y
sudo apt-get install unzip
curl -LJO https://gist.github.com/tori29umai0123/b710efabf3781f137359fa1616da85f4/archive/de02efdc45a32c33c18d2b4d53f11108cb824ea0.zip
unzip -j "b710efabf3781f137359fa1616da85f4-de02efdc45a32c33c18d2b4d53f11108cb824ea0.zip" "b710efabf3781f137359fa1616da85f4-de02efdc45a32c33c18d2b4d53f11108cb824ea0/HF_upload_sdxl_gen_img.py" -d ./
accelerate config
- This machine
- No distributed training
- NO
- NO
- NO
- all
- bf16スクリプトを実行する前にローカルで生成したdart_prompts.txtをサーバーに手動で『sd-scripts/dart_prompts.txt』になるようにアップロードしておきます。
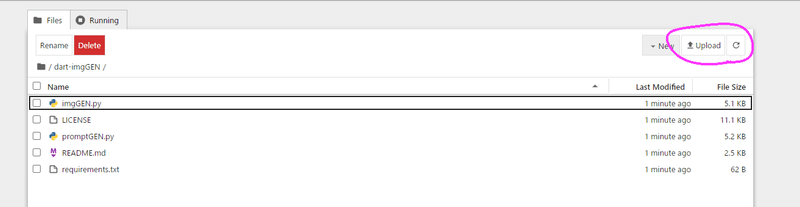
アップロードするリポジトリ名と、アクセストークンを聞かれるので入力。
あとはひたすら画像生成を待つだけです。
python HF_upload_sdxl_gen_img.py
上記のようにして作られたのが以下のデータセットです。
終わったらインスタンスを閉じること。
しかしこのままだとNSFW画像が入っている可能性もあるので、それらを選別する必要があります。
⑥生成された画像をAIでSFW/NSFW分類&タグづけ
生成された画像からNSFWを取り除く&ついでにキャプションもつけてしまいます。
アップロードされた画像をローカルにDLし、一つのフォルダにまとめます。
①で作ったローカルの仮想環境でさらに以下のコマンド
pip install opencv-python-headless numpy Pillow tqdm onnx onnxruntime-gpu huggingface-hub以下のスクリプトを作成。
nsfw_filter_with_tagger.py
import csv
import glob
import os
from pathlib import Path
import cv2
import numpy as np
import torch
from PIL import Image
from tqdm import tqdm
import onnx
import onnxruntime as ort
from huggingface_hub import hf_hub_download
import shutil
# 画像サイズ
IMAGE_SIZE = 448
def preprocess_image(image):
image = np.array(image)
image = image[:, :, ::-1] # BGRからRGBへ変換
# 画像を正方形にパディングする
size = max(image.shape[0:2])
pad_x = size - image.shape[1]
pad_y = size - image.shape[0]
pad_l = pad_x // 2
pad_t = pad_y // 2
image = np.pad(image, ((pad_t, pad_y - pad_t), (pad_l, pad_x - pad_l), (0, 0)), mode="constant", constant_values=255)
interp = cv2.INTER_AREA if size > IMAGE_SIZE else cv2.INTER_LANCZOS4
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE), interpolation=interp)
image = image.astype(np.float32)
return image
def run_batch(path_imgs, input_name, ort_sess, rating_tags, general_tags, thresh, nsfw_dir, sfw_dir):
imgs = np.array([im for _, im in path_imgs])
probs = ort_sess.run(None, {input_name: imgs})[0] # ONNXの出力
probs = probs[: len(path_imgs)]
undesired_tags = []
remove_underscore = True
caption_separator = ", "
tag_freq = {}
undesired_tags = []
for (image_path, _), prob in zip(path_imgs, probs):
combined_tags = []
general_tag_text = ""
character_tag_text = ""
tag_confidences = {tag: prob[i] for i, tag in enumerate(rating_tags)}
max_nsfw_score = max(tag_confidences.get("questionable", 0), tag_confidences.get("explicit", 0))
max_sfw_score = tag_confidences.get("general", 0)
destination = nsfw_dir if max_nsfw_score > max_sfw_score else sfw_dir
tag_file_path = os.path.join(destination, os.path.splitext(os.path.basename(image_path))[0] + ".txt")
# タグを一行で保存
for i, p in enumerate(prob[4:]):
if i < len(general_tags) and p >= thresh:
tag_name = general_tags[i]
if remove_underscore and len(tag_name) > 3:
tag_name = tag_name.replace("_", " ")
if tag_name not in undesired_tags:
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
general_tag_text += caption_separator + tag_name
combined_tags.append(tag_name)
# 先頭のカンマを取る
if len(general_tag_text) > 0:
general_tag_text = general_tag_text[len(caption_separator) :]
if len(character_tag_text) > 0:
character_tag_text = character_tag_text[len(caption_separator) :]
with open(tag_file_path, 'w') as f:
f.write(", ".join(combined_tags))
# 画像を適切なフォルダにコピー
try:
shutil.copy(image_path, os.path.join(destination, os.path.basename(image_path)))
print(f"{image_path} を {destination} にコピーしました。")
except Exception as e:
print(f"{image_path} を {destination} にコピーできませんでした。エラー: {e}")
def main():
print("Hugging Faceからwd14 taggerをロード中")
onnx_path = hf_hub_download(MODEL_ID, "model.onnx")
csv_path = hf_hub_download(MODEL_ID, "selected_tags.csv")
print("wd14 taggerのONNXを実行中")
print(f"ONNXモデルをロード中: {onnx_path}")
ort_sess = ort.InferenceSession(onnx_path)
with open(csv_path, "r", encoding="utf-8") as f:
reader = csv.reader(f)
header = next(reader)
rows = list(reader)
assert header == ["tag_id", "name", "category", "count"]
rating_tags = [row[1] for row in rows if row[2] == "9"]
general_tags = [row[1] for row in rows if row[2] == "0"]
image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.webp']
image_paths = []
for ext in image_extensions:
image_paths.extend(list(Path(input_dir).rglob(ext)))
b_imgs = []
# tqdmのtotalパラメータにリストの長さを渡す
for image_path in tqdm(image_paths, total=len(image_paths), smoothing=0.0):
image_path = str(image_path)
base_name = os.path.splitext(os.path.basename(image_path))[0]
if (os.path.exists(os.path.join(sfw_dir, base_name + ".webp")) and os.path.exists(os.path.join(sfw_dir, base_name + ".txt"))) or \
(os.path.exists(os.path.join(nsfw_dir, base_name + ".webp")) and os.path.exists(os.path.join(nsfw_dir, base_name + ".txt"))):
print(f"{image_path} は既に処理されています。")
continue
try:
image = Image.open(image_path)
image = image.convert("RGB") if image.mode != "RGB" else image
image = preprocess_image(image)
b_imgs.append((image_path, image))
except Exception as e:
print(f"画像を読み込めません: {image_path}, エラー: {e}")
continue
if len(b_imgs) >= batch_size:
run_batch(b_imgs, ort_sess.get_inputs()[0].name, ort_sess, rating_tags, general_tags,thresh, nsfw_dir, sfw_dir)
b_imgs = []
if b_imgs:
run_batch(b_imgs, ort_sess.get_inputs()[0].name, ort_sess, rating_tags, general_tags,thresh, nsfw_dir, sfw_dir)
print("処理完了!")
if __name__ == "__main__":
MODEL_ID = "SmilingWolf/wd-swinv2-tagger-v3"
input_dir = "E:/desktop/dart_v2_sft_img"
sfw_dir = "E:/desktop/sfw"
nsfw_dir = "E:/desktop/nsfw"
if not os.path.exists(sfw_dir):
os.makedirs(sfw_dir)
if not os.path.exists(nsfw_dir):
os.makedirs(nsfw_dir)
batch_size = 16
thresh = 0.35
main()
python nsfw_filter_with_tagger.pyRTX3090で6時間位放置して仕分けできました。
というワケで改めて仕分けてできたSFWのみのデータセットを以下のリポジトリにアップロードしました!
これでようやく誰でも気兼ねなく使えるアニメ絵柄風データセットが完成しました!!!やったー!!!!
ところでさ、これ何に使うの?さ、さぁ・・・???(なんか最近優秀なコントロールネットがごりごりでてきて今更自作する必要なくない?
この記事が気に入ったらサポートをしてみませんか?