
LLMのハルシネーションを検知する方法

LLMのハルシネーション検知手法に関するこちらの記事を読み、興味を持ったので調べてみました。
記事のベースとなっているのは以下の論文のようです。
上記を参考に、ハルシネーション検知に対する考え方や、各検知手法について簡単にまとめました。
前提
テストは以下の前提とします。これを「ブラックボックステスト」と呼んでいます。
外部知識は利用しない
LLMの内部挙動を見ない
生成された回答のみを使ってテストする
ハルシネーションを検知するには?
同じ質問に対して複数の回答を生成させて、出力間の一貫性を見ます。
回答に一貫性があるほどハルシネーションが少ないと言えます。
テキスト同士の一貫性の算出方法
以下のような手法があります。
Cosine similarity
N-gram language model
BERTScore
Question-Answering
Natural Language Inference (NLI)
LLM prompting
論文作者チームによる算出用コードもSelfCheckGPTという名前で公開されているので、簡単に試してみることもできそうです。
各手法の概要
Cosine similarity
SentenceTransformerなど任意の方法でテキストをエンベディングし、ベクトル同士のコサイン類似度を算出する。
N-gram language model
N-gram単位でのテキストの一致度を見る。
BERTScore
Cosine similarityとN-gramを組み合わせたような手法。
N-gram単位での一致を見る代わりに、BERTでエンベディングされたトークン同士の類似度を見る。テキスト間で最もコサイン類似度の高いトークン同士を紐付けてスコア化する。

Question-Answering
比較元テキストから選択式の質問を生成する。
別途用意したQAモデルで、各テキストを参照して質問に回答させ、どれだけ回答が一致しているかを見る。

なお、Question-Answeringモデル自体についてはこちらの論文で書かれています。
Natural Language Inference (NLI)
自然言語処理タスクの一つであるNLI用のモデルを用いる。
「前提(premise)=比較元テキスト」と「仮説(hypothesis)=比較先テキスト」がどれだけ矛盾しているかを予測する。

LLM prompting
LLMに評価してもらう。
SelfCheckGPTではyes/noで回答させていますが、スコアを回答させることも可能です。
yes or no
# 参考 https://github.com/potsawee/selfcheckgpt/blob/f30483d97b5f0f887d44c1a507c02d72526b15a5/demo/experiments/selfcheck_prompt/openai_gpt3_prompt.py#L16
Context: {}
Sentence: {}
Is the sentence supported by the context above?
Answer Yes or No:scoring
# 参考 https://learn.deeplearning.ai/quality-safety-llm-applications/lesson/3/hallucinations
prompt = f"""You will be provided with a text passage \
and your task is to rate the consistency of that text to \
that of the provided context. Your answer must be only \
a number between 0.0 and 1.0 rounded to the nearest two \
decimal places where 0.0 represents no consistency and \
1.0 represents perfect consistency and similarity. \n\n \
Text passage: {dataset['response'][index]}. \n\n \
Context: {dataset['response2'][index]} \n\n \
{dataset['response3'][index]}."""精度比較
論文内ではLLM promptingが最も精度が高いという結果が出ています。
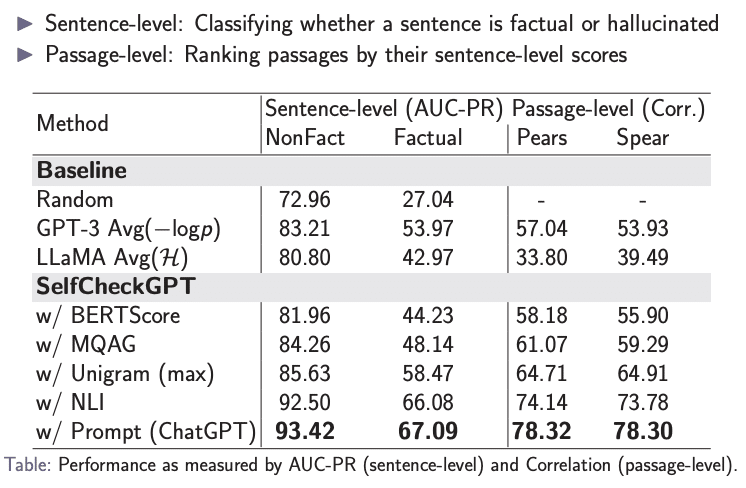
まとめ
ハルシネーションの検知方法:同じ質問に対して複数の回答を生成させて、出力間の一貫性を見る。
出力間の一貫性もLLMに評価してもらうことが可能。
参考文献
[2303.08896] SelfCheckGPT: Zero-Resource Black-Box Hallucination
[1904.09675] BERTScore: Evaluating Text Generation with BERT
How to Detect Hallucinations in LLMs | by Iulia Brezeanu | Jan, 2024 | Towards Data Science
DeepLearning.AI Quality and Safety for LLM Applications
DLAI - Learning Platform Beta従来のBLEUscoreでは正しく評価できない! 自然言語に最適な人間に近い評価基準BERTScore登場! | AI-SCHOLAR | AI:(人工知能)論文・技術情報メディア
Header Photo by Unsplash Micah Boswell
この記事が気に入ったらサポートをしてみませんか?