
超解像について (その1・SRCNN まで)

こんにちはこんばんは、teftef です。今回は画像を拡大縮小することに関してです。2 回に分けて書きます。これは前半で比較的よく知られていることが書かれています。(個人的に超解像に興味がわいたので1か月くらい文献追ってました)
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
※この記事は有料となっていますが、最後まで内容が読めます。
ベクタ画像・ラスタ画像

まずは画像形式に関する基本情報です。画像を保存する際の拡張子 ( . の後) として jpeg, png, webp, svg, GIF, EPS , AI, PDF ,…といろいろあります。これらは大きく分けて、ベクタ画像とラスタ画像に分かれていて、画像の表現方法が違います。
ベクタ画像(PS , AI, PDF など)はベクトルというだけあって、画像が点や線で数学的に表現されており、数式計算を用いて描画されます。そのため、ロゴや幾何学的な図形を表現するのに使われています。ベクタ画像は拡大縮小をしても、その都度計算されるため画質が維持されるという利点があります。
対して、ラスタ画像は (jpeg, png, webp, GIF など) はピクセルの集まりで表現されているので、写真やイラストのような複雑なディテールを持った画像を正確に表現することができます。このようにピクセル毎に情報があるので、細かい色やグラデーションの表現が得意となっています。しかしながら、一度ラスタ画像に対して拡大縮小編集をすると元の画質を取り戻すことが難しくなります。
私たちがよく使う形式は圧倒的に後者のラスタ画像であり、 jpeg , png が多いと思います。 (jpeg はロッシー圧縮で、画質を犠牲にして圧縮率を上げていて、たいして png はロスレス圧縮で画質を落とさずに保存できるという話は今回しません。)
4K モニターなどの登場やカメラの高性能化により、高画質な画像・映像コンテンツを再生することができる出力器が身近になり、従来の低画質なコンテンツを高画質化して出力したいというニーズが高まっています。しかし、従来の低画質の画像を大きな画面で映したいときに、ガビガビな画質になってしまうことがあります。また、画像の細かい部分を拡大してみようとすると、ピクセルが大きく拡大されるだけでそれ以上細かくならないことを体験たことがある人は多いと思います。画像を拡大するときに画質を落とさずにする手法が必要になってきいます。
アップスケーリング
この記事では、まずは画像を拡大(アップスケーリング)することに焦点を置いて進んでいきます。
最近傍法
最近傍法(Nearest Neighbor Interpolation)は最もシンプルな方法であり、画像の各ピクセルの値(RGB値)を参照して、新しい位置にその値をコピーします。計算の処理速度が速く、複雑な計算が不要であるというメリットがありますが、拡大時にはジャギー(不連続的な線や角)が出やすいというデメリットがあります。

バイリニア補間
バイリニア補間(Bilinear Interpolation)は画像を拡大(または縮小)する際に新しいピクセルの値(RGB値)を、元の画像の最も近い 4 つのピクセルの値(RGB値)から計算します。計算方法は、求めたいピクセルの(最も近い既知の)周囲 4 つのピクセル(左上、右上、左下、右下)の値の加重平均を求めます。この際に重みは求めたいピクセル位置と 4 つのピクセルとの距離をに基づいて決定します。バイリニア補間は、最近傍法よりもスムーズな画像を拡大できますが、画像のエッジや細かいテクスチャの再現性には限界があります。

バイキュービック補間
バイキュービック補間(Bicubic Interpolation)ではバイリニア補間が2x2の近隣 4 ピクセルの値(RGB値)を使うのに対して、バイキュービック補間は 4x4 の近隣 16 ピクセルの値(RGB値)を使用します。計算方法は、求めたいピクセルの(最も近い既知の)周囲 16 つのピクセルの値の加重平均を求めます。これにより、より多くの情報を利用して新しいピクセルの値を計算します。この際に重みは求めたいピクセル位置と 16 つのピクセルとの距離をに基づいて決定します。この結果、バイキュービック補間は最近傍法やバイリニア補間よりも計算が複雑になりますが、高品質な画像が得られるというメリットがあります。

超解像 (Super-Resolution)

今まで書いてきた、アップスケーリング手法ではアルゴリムに沿った計算を行うことで画像のサイズを変更することが主な目的となっています。アップスケーリング手法はすばやく正確に画像を拡大することができますが、画像を大きくするにつれて画質が劣化してしまうというデメリットがあります。
超解像(Super-Resolution)は、低解像度の画像を高解像度の画像に変換する技術です。単にピクセルを増やすだけでなく、失われた細部やテクスチャを復元することを目指します。映像や医療画像、衛星画像などの分野での応用されています。単一の低解像度画像から高解像度画像を生成する「単一画像超解像」や、複数の低解像度画像を組み合わせて高解像度画像を生成する「多重画像超解像」など、さまざまな方法がありますが、今回は主に単一画像超解像についてです。
スパースコーディングを用いた超解像
まず、少し昔の超解像についてです。特定の画像や信号の特徴を捉える基底ベクトルやパッチの集合(辞書)を使用して高解像度画像を再構築する手法を用いています。
高解像度の画像パッチを使用して辞書 D_h が訓練され、次に同じ高解像度の画像を意図的に低解像度に変換(例えば、ぼかす)して、低解像度の画像パッチを生成します。このパッチを用いて低解像度の辞書 D_l を訓練します。低解像度の画像からパッチを抽出し、低解像度の辞書 D_l を使用して、最適なパッチの組み合わせを探します(ラッソ回帰 {Lasso Regression} などを用いる)。これがスパース表現となります。得られたスパース表現を利用して、辞書内の対応する高解像度のパッチを組み合わせて、全体の高解像度画像を再構築します。

やっていることは機械学習と似ていますが(辞書は潜在変数のようなものにあたる)、この頃はどちらかというとアルゴリズムを用いて機械的に解いているという感覚が強いです。
SRCNN
時が進み、超解像は計算機資源(GPU)の性能向上とコンピュータビジョンの発展により 2010 年代から深層学習を用いた手法が登場しました。2014 年に Dong et al.によって CNN (畳み込みニューラルネットワーク)を用いた超解像が提案されました。
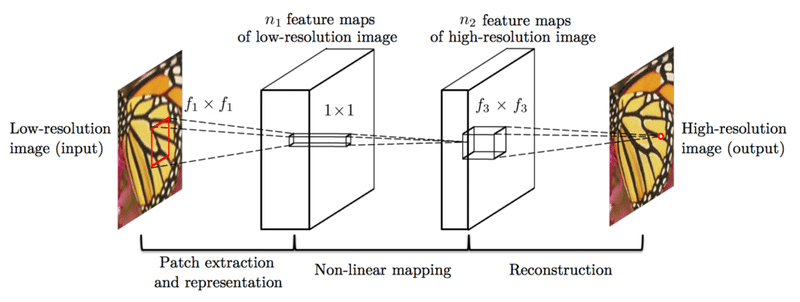
SRCNN は基本的に ( Conv + Relu ) 3 層というシンプルなレイヤーで構成されています。
def __init__(self) -> None:
super(SRCNN, self).__init__()
# Feature extraction layer.
self.features = nn.Sequential(
nn.Conv2d(1, 64, (9, 9), (1, 1), (4, 4)),
nn.ReLU(True)
)
# Non-linear mapping layer.
self.map = nn.Sequential(
nn.Conv2d(64, 32, (5, 5), (1, 1), (2, 2)),
nn.ReLU(True)
)
# Rebuild the layer.
self.reconstruction = nn.Conv2d(32, 1, (5, 5), (1, 1), (2, 2))
# Initialize model weights.
self._initialize_weights()https://github.com/Lornatang/SRCNN-PyTorch/blob/main/model.py
学習データセットには元の画像をバイリニア補間、バイキュービック補間を用いて縮小した低解像度画像 (LR) のペアを用いています。
損失関数として平均二乗誤差 (MSE)を用います。再構築された高解像度画像と実際の高解像度画像との差を最小化します。
このようなシンプルなアーキテクチャでも意外と高い品質の画像を生成することが可能となっています。

このように 簡単な 3 層ほどの CNN を用いたネットワークアーキテクチャ超解像ができていることがわかります。この CNN はそこまで多くの計算資源を必要としないシンプルな構造であり、 SRCNN を用いることで高画質な画像が得られそうです。
問題点
表現力の問題
しかし、SRCNN を用いた超解像をよく見てみると、ぼやけていることがわかります。これはCNN の表現力と人間の知覚に大きなずれがあることを意味しています。SRCNN ではネットワークが 3 層であるため、表現力が限られていることが理由に挙げられそうです。
データセットの問題
また、よく考えてみると、そもそも学習データセットのペアに、実画像とバイリニア補間、バイキュービック補間を用いて縮小した低解像度画像 (LR) のペアを用いることが正しいか?という疑問が残ります。
計算コストの問題
さらに、データセットを用意する際に使用する計算がネックになってしまうということがあります。バイリニア補間、バイキュービック補間の計算コストが意外と大変だったりします。
解決策と次回予告
というわけで、この問題点を何とかしたいのですが、だいぶ長くなるので、次回に続きます。
参考文献
最後に
最後まで読んでいただきありがとうございました。アップスケーリングの基本から CNN を用いた超解像までの大まかな流れを書きました。次回はこの SRCNN の後継版である SRGAN , Real-ESRGAN , DiffBir についてです。
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(4,800 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 :ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
この記事が気に入ったらサポートをしてみませんか?