
Weekly Report 2024/01/31 (wed)
個人的に気になったニュースや自主制作などの週報メモです。
自主制作 / 記事
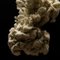
Elemental Anima #0120
Elemental Anima #0120
— takio koizumi | takion.eth (@takion0105) January 26, 2024
Created by :
takio koizumi (Human) x HAL (AI)
🔽Detail / Link pic.twitter.com/YCpziVEAOe
今作は映画"哀れなるものたち"公開が楽しみすぎたのもあり、大好きなヨルゴス・ランティモス監督作品をオマージュし制作しました。そして、先日観た"哀れなるものたち"は、自分を構築する"好きな要素"が混ざりすぎて、あの世界にずっと浸って居たいぐらいハマってしまいました。しっかりと咀嚼しElemental Animaとして作品に残そうと思います。
今作のキーワード
ロブスター、テロメア、ピンクのサンゴ(脳)、外部刺激(感動)、新陳代謝、復活、再生、老化、海・泡(細胞)
[ニュース] AI関連
[3D] Tencent - TIP-Editor
Tencent presents TIP-Editor
— AK (@_akhaliq) January 29, 2024
An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts
paper page: https://t.co/XKYmzpHek1
Text-driven 3D scene editing has gained significant attention owing to its convenience and user-friendliness. However, existing methods still… pic.twitter.com/zNixsvOg6y
今週のTencentさん。3D Gaussian Splattingの領域を指定した部分をプロンプトで編集する技術を発表しています。
[動画] nVidia - Motion-I2V
A new model for converting Images-to-Videos has been introduced: 𝐌𝐨𝐭𝐢𝐨𝐧-𝐈𝟐𝐕
— Gradio (@Gradio) January 30, 2024
Researchers from: NVIDIA AI, The Chinese University of Hong Kong, SenseTime Research, Tsinghua University, CPII, Shanghai AI Laboratory, Avolution AI
Eagerly anticipating a demo on Spaces. https://t.co/jFvZoEytmi pic.twitter.com/9jGTBrB9Hd
いよいよRunwayGen-2のモーションブラシがフレームワークに入ってるものが出ましたね。まだ未確定な部分が多すぎますが、このMotion-I2Vが来たらかなりのトレンドになりそうなので情報を追っていこうと思います。あと、動画のソースを探してみたのですが、見当たらずGradioは何処から持ってきているのか・・・
[3D] Apple - HUGS: Human Gaussian Splats
Appleも3D Gaussian Splattingを活用した新たな技術を公開していました。AppleによるNeRFやGS系のアプローチは観たことが無かったので驚きました。Apple Visionとの相性は抜群だと思うので、Cyberpunk 2077のブレインダンスのように空間のアーカイブを体験出来たら最高です。
[言語] Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
今週のAlibabaさんです。来年ぐらいには全てのスマホに実装されそうですね。
[画像] InstantID - ControlNet対応
InstantIDが約1週間でWubUIのControlNetにも実装されました。やはりコードが公開されてトレンド技術はすぐに実装されますね。
[画像] TikTok - Depth Anything - ControlNet対応
先週紹介したDepth Anythingが早くもControlNetに実装されていました。今までの、depth生成より精度が高くなっているのでありがたいですね。また、モーションブラーの処理も優れているのでAnimateDiffに活用すると連続性を保ちつつ生成できるのでお勧めです。今後、SDXLにも対応して頂けるとありがたいです。
[画像] Grounded-Segment-Anything
以前紹介した、テキストプロンプトで画像内のオブジェクトを特定するモデル「Grounding DINO」と、任意のオブジェクトを分割するSegment Anything Modelが組み合わせたモデルですね。このGithubのページ下部のOSX Demoとの組み合わせも凄いので是非見て下さい。
[画像] Amazon - Diffuse to Choose
Amazonも実用的なアプローチで動き始めましたね。服のバーチャル試着や家具のバーチャル配置ができるのは購入の際にも便利だと思うので、実用化が楽しみです。Amazonの持つデータセットの活用がどこまで大丈夫なのかも今後話題になりそうです。
[画像] Baidu - UNIMO-G
Baiduのマルチモーダルによる画像生成モデルです。テンセント、アリババ、バイドゥと中国企業のムーブが高まりつつありますね。
[動画] Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis
sadtalkerは殆ど口元のみでしたが、こちらは3Dの様にマッピングしつつカメラワークもついているのでリアリティも上がってきましたね。
[AI活用] Midjourney + Runway + AE
Pretty cool use of Runway’s Motion Brush to generate and animate the clothing.
— Cristóbal Valenzuela (@c_valenzuelab) January 24, 2024
h/t https://t.co/tIB0wudQOz pic.twitter.com/ODMyNO1Drv
この活用は演出、シチュエーションを含めて上手いと思いました。服のたなびきによりAI特有のノイズが気にならないのもいいです。
[画像] Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
複雑なプロンプトでも正確な画像を生成する新しいフレームワーク。SDXLにも適応でき、互換性も広いので色々な展開が楽しみです。
[モーション] Multi-Track Timeline Control for Text-Driven 3D Human Motion Generation
タイムラインでモーションをコントロールしつつ、なじませられるのはかなり便利ですね。UnrealやUnityなどにいつか実装して欲しい技術ですね。
[モーション] Media2Face: Co-speech Facial Animation Generation With Multi-Modality Guidance
音声から3Dのフェイシャルアニメーションを生成。頭の動きも説得力ありますね。
[動画] FreeNoise: Tuning-Free Longer Video Diffusion
via Noise Rescheduling
長い尺の動画を生成した際のノイズを安定化するフレームワーク。コードも公開されていて、Animatediffでの生成も出来るので使用してみたいですね。
[市場] 中国で続々とAIモデルが承認され中国国内のAI産業は10兆円規模の市場に
ここ最近の中国のAI技術を追っていると納得感はありますね。かなりの速度で先行しているので、成長した先でどういう問題が発生していくのかを見ていけるのでしっかりとリサーチしていこうと思います。
[企業] Google CloudとHugging Faceが提携 AI開発者にH100などのパワーを提供へ
[ニュース] リアルタイムエンジン関連
[UE] Cinematic Action Scene
クオリティ高すぎて驚きました。どれぐらいリアルタイムで動くのか気になりますね。
[エフェクト] RE:2023 高品質なエフェクトのためのエディター機能とワークフロー紹介
[エフェクト] EmberGen 1.1 Preset リール
4 1/2 minute runthrough of all new or revised presets coming to EmberGen 1.1!#realtimeVFX pic.twitter.com/58XQP32LPV
— JangaFX Software (@JangaFX) January 18, 2024
この記事が気に入ったらサポートをしてみませんか?