
ネジの不具合箇所を自動検知させる外観検査コードの作成

1.はじめに
私はAI企業で製造業向けのAI搭載外観検査装置を営業として販売しています。
元来、製造業では品質不良を流出させることが出来ない業界です。製造現場で不良品の流出を止める必要があり、常に品質の平準化が求められています。それに加え昨今では人が採用できず、十分な人的リソースを確保できません。そんな背景から人が行っていた外観検査を自動化させ省人化させる流れがあります。
今回私はそういった過酷な環境にいる、製造業の人々の負担を軽くなる様な検査装置をエンジニア視点を持って、販売していきたいと思っております。
営業をするため実際に外観検査モデルを作成~実装できる人材であれば、お客様に対して「現場で使えるAI検査装置」を提案が出来ると考えました。そういった考えの基、アイデミ―に入学し、製造業で使える外観検査AIコードを作成いたしました。
《不具合品の表示例》

2.開発環境
・Surface Laptop i5
・Windows 10 Pro
・Google Colaborabory
・Python(Ver 3.8.5)
3.使用したライブラリ
・OpenCV
Open Source Computer Vision Libraryの略で画像処理・画像解析に使用するライブラリ。
・Numpy
Pythonで数値計算を行うためのライブラリ。
・Matplotlib
プログラミング言語Pythonおよびその科学計算用ライブラリNumPyのためグラフ描画ライブラリ
・PyTorch
コンピュータビジョンや自然言語処理で利用されているTorchを元に作られた、Pythonのオープンソースの機械学習ライブラリ
・YOLOv5(You Only Look Once)
Pytorchをベースに作られている、物体検出アルゴリズム。処理速度が非常に速いのが特徴で、リアルタイムに物体検出を行うことも可能
4.学習データ
①自身でネジ購入~撮像まで実施
自身でネジを1型式(100個)購入し撮像まで実施。80個の良品画像と20枚のNG画像を作成。
《良品》

《不良品》
・傷

・マーカー

②水増しデータ作成
また、OK/NGを学習させてるだけではなくバウンディングボックスを不具合箇所に表示させるためYolo5を活用しました。YOLOv5に不具合箇所を学習させるため、20枚のNG画像を基に70枚の学習用画像と30枚の検証用画像を水増し作業を実施しました。
#画像反転
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
#Google ドライブを Google Colab にマウント
from google.colab import drive
drive.mount('/content/drive')
!ls ./drive/MyDrive
# 指定したディレクトリの中身を一覧で取得
path_shuusei = os.listdir('/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品')
#読み込んだ画像データをまとめるためのリスト
img_shuusei = []
#読み込みたい画像のファイルパスの数だけ繰り返し処理
for i in range(len(path_shuusei)):
img = cv2.imread('/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品/' + path_shuusei[i])
print(path_shuusei[i])
my_img = cv2.flip(img, 0)
#画像ファイルに保存
cv2.imwrite(path_shuusei[i]+"反転.jpg", my_img)
#ノイズ除去
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
#Google ドライブを Google Colab にマウント
from google.colab import drive
drive.mount('/content/drive')
!ls ./drive/MyDrive
# 指定したディレクトリの中身を一覧で取得
path_shuusei = os.listdir('/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品')
#読み込んだ画像データをまとめるためのリスト
img_shuusei = []
#読み込みたい画像のファイルパスの数だけ繰り返し処理
for i in range(len(path_shuusei)):
img = cv2.imread('/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品/' + path_shuusei[i])
print(path_shuusei[i])
my_img = cv2.fastNlMeansDenoisingColored(img)
#画像ファイルに保存
cv2.imwrite(path_shuusei[i]+"ノイズ除去.jpg", my_img)
#マスキング
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
#マスクの指定
# 指定したディレクトリの中身を一覧で取得
path_shuusei = os.listdir('/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品')
#読み込んだ画像データをまとめるためのリスト
img_shuusei = []
#読み込みたい画像のファイルパスの数だけ繰り返し処理
for i in range(len(path_shuusei)):
img = cv2.imread('/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品/' + path_shuusei[i])
mask = cv2.imread("/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品水増し/マスキング/circle-2.png",255)#"/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品水増し/マスキング/circle-2.png", 0)
mask=np.max(mask,axis=2)
mask = cv2.resize(mask, (img.shape[1], img.shape[0]))
retval, mask = cv2.threshold(mask, 0, 255, cv2.THRESH_BINARY_INV)
mask = cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR)
my_img = cv2.bitwise_and(img, mask)
#画像ファイルに保存
cv2.imwrite(path_shuusei[i]+"マスキング.jpg", my_img)
#回転180°
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from PIL import Image
# 指定したディレクトリの中身を一覧で取得
path_shuusei = os.listdir('/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品')
#読み込んだ画像データをまとめるためのリスト
img_shuusei = []
#読み込みたい画像のファイルパスの数だけ繰り返し処理
for i in range(len(path_shuusei)):
im = Image.open("/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品/" + path_shuusei[i])
im_rotate = im.rotate(180, expand=True)
#画像ファイルに保存
cv2.imwrite(path_shuusei[i]+"回転180度.JPG", np.array(im_rotate))
#回転90°
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from PIL import Image
# 指定したディレクトリの中身を一覧で取得
path_shuusei = os.listdir('/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品')
#読み込んだ画像データをまとめるためのリスト
img_shuusei = []
#読み込みたい画像のファイルパスの数だけ繰り返し処理
for i in range(len(path_shuusei)):
im = Image.open("/content/drive/MyDrive/画像_OK_NG品/OK_NG品/NG品/" + path_shuusei[i])
im_rotate = im.rotate(180, expand=True)
#画像ファイルに保存
cv2.imwrite(path_shuusei[i]+"回転180度.JPG", np.array(im_rotate))③アノテーション自動生成
参考文献で記載URLを基に一度アノテーションの自動生成をコード記載し実施
%cd /content/drive/MyDrive
%mkdir Colab
%cd /content/drive/MyDrive/Colab
# yolov5ダウンロード
!git clone https://github.com/ultralytics/yolov5.git
# パッケージのインストール
%cd /content/drive/MyDrive/Colab/yolov5
!pip install -r requirements.txt
import cv2
import numpy as np
def shading_correction(img):
kernel = np.ones((15,15),np.uint8)
img_bg = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
img_corrected = cv2.absdiff(img_bg, img)
return img_corrected
def make_debris_extents(img):
# ラベリング処理
n, label, data, center = cv2.connectedComponentsWithStats(img)
sizes = data[1:, -1]
# サイズフィルター
rects = []
for j in range(1, n):
if 16<sizes[j-1] and sizes[j-1]<15000:
# 各オブジェクトの外接矩形を抽出
d = 8
w = data[j][2]+d+d
h = data[j][3]+d+d
if 18<=w and w<=256 and 18<=h and h<=256:
x0 = data[j][0]-d
y0 = data[j][1]-d
rects.append((int(x0), int(y0), int(w), int(h)))
return rects
def make_yolo_annotation(img_width, img_height, class_id, xmin, ymin, xmax, ymax):
'''
YOLO形式のアノテーション(yolov5)
'''
xcenter = (xmax + xmin)/img_width/2.0
ycenter = (ymax + ymin)/img_height/2.0
width = (xmax - xmin)/img_width
height = (ymax - ymin)/img_height
annotation_text = '{} {} {} {} {}\n'.format(class_id, xcenter, ycenter, width, height)
return annotation_text
def process_image(image_name):
Mypath_input = '/content/drive/MyDrive/training/train/images/'
Mypath_output = '/content/drive/MyDrive/training/train/ano/'
with open(Mypath_output + image_name+'.txt', 'w') as fa:
img_orig = cv2.imread(Mypath_input + image_name+'.jpg', 0)
img_result = cv2.cvtColor(img_orig, cv2.COLOR_GRAY2BGR)
img_corrected = shading_correction(img_orig)
ret, img_bin = cv2.threshold(img_corrected, 40, 255, cv2.THRESH_BINARY)
rects = make_debris_extents(img_bin)
for rect in rects:
x0 = rect[0]
y0 = rect[1]
w = rect[2]
h = rect[3]
x1 = x0 + w
y1 = y0 + h
cv2.rectangle(img_result, (x0, y0), (x1, y1), color=(0, 0, 255), thickness=3)
class_id = 0
annotation_text = make_yolo_annotation(
img_orig.shape[1], img_orig.shape[0], class_id,
x0, y0, x1, y1)
fa.write(annotation_text)
# 結果画像を書き出し
cv2.imwrite(Mypath_output + image_name+'_result.jpg', img_result)
def main():
for i in range(1,101):
process_image(str(i))
if __name__ == '__main__':
main()!pip install -r /content/drive/MyDrive/Colab/yolov5/requirements.txt!python /content/drive/MyDrive/Colab/yolov5/train.py --batch 16 --epochs 400 --data /content/drive/MyDrive/Colab/yolov5/data/dataset.yaml --cfg /content/drive/MyDrive/Colab/yolov5/data/yolov5s.yaml《自動アノテーション_学習結果》
※後述の記載コードと同様に学習を実施
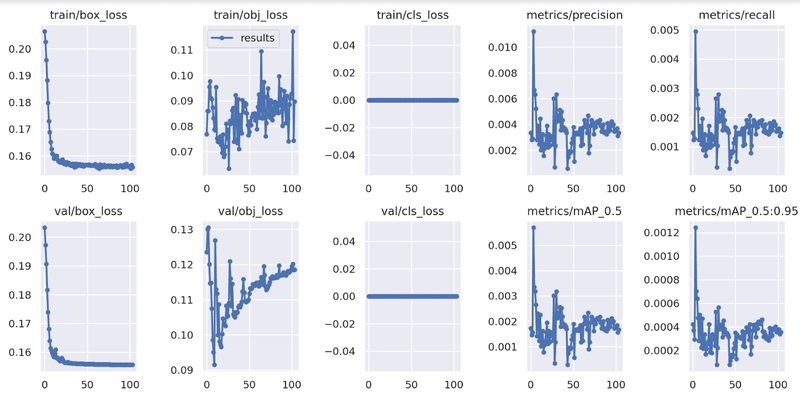
presisionの数値上昇見られず

既存の精度では使えないので、labellmgを活用
④labelImgを活用しアノテーションの精度向上
学習用画像に対して1つずつアノテーションを付与する作業実施
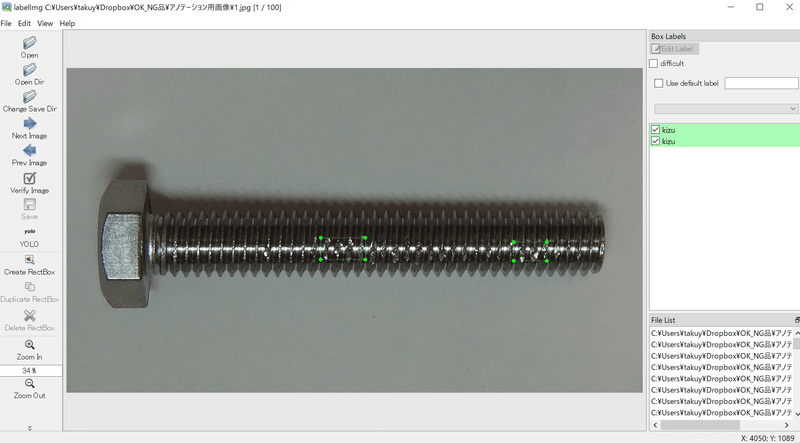
学習データだけではなく、検証用データ側にもアノテーション作業実施


results.png を見て、学習を重ねるにつれlossが順調に減っていき、precisionが順調に上がっていくことが確認できた。
《フォルダ構成》
アノテーションの準備ができたら、yolov5による学習に必要なファイル一式をフォルダーにまとめる
training/
dataset.yaml
yolov5s.yaml
train/
images/
*.jpg
labels/
classes.txt
*.txt
test/
images/
*.jpg
labels/
classes.txt
*.txt
val/《dataset.yaml》dataset.yamlには学習画像、評価画像の場所、クラス数、クラス名を記述
# train and val datasets (image directory or *.txt file with image paths)
train: /content/drive/MyDrive/Colab/yolov5/data/train/images
val: /content/drive/MyDrive/Colab/yolov5/data/vaid/images
# number of classes
nc: 2
# class names
names: ['kizu','maker']《yolov5s.yaml》
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]5.学習
!python /content/drive/MyDrive/Colab/yolov5/train.py --batch 16 --epochs 400 --data /content/drive/MyDrive/Colab/yolov5/data/dataset.yaml --cfg /content/drive/MyDrive/Colab/yolov5/data/yolov5s.yaml以下は学習の過程です。

推論の評価
#推論の評価
%cd /content/drive/MyDrive/Colab/yolov5
!python detect.py --source /content/drive/MyDrive/Colab/yolov5/data/vaid/images/1.jpg --weights /content/drive/MyDrive/Colab/yolov5/runs/train/exp11/weights/best.pt
《結果》

《定量結果》

mAp50は矩形で正しく読み込めている面積が全体の約60%を占めている結果
6.まとめ
今回作成した、コードの精度で言うとまだ現場で採用してもらえるレベルではないと感じています。ただ、現状どの様に改善していくのかなど、課題に対する解決方法は今回の成果物を通して学習することが出来ました。それを次回実案件で対応し、お客様に満足して貰える精度に引き上げられる提案を自社のデータサイエンティストとコミュニケーション取りながら進めていきたいと感じました。
今回苦労したポイントとしてはAIの精度をどの様に出すかという所です。最初参考URLでは矩形をコードで自動抽出していたので、真似てみましたが、出力結果の精度は非常に低かったです。アノテーション作業を地道に1枚ずつ実施し、AIに教え込むことでやっと精度が向上していきました。こういった苦労を感じられたのは非常に良い収穫でした。
7.参考文献
この記事が気に入ったらサポートをしてみませんか?