
Webアプリでembeddingを使いLLMの入出力とプログラムを紐づける

はじめに
生成AIとプログラミングを組み合わせた「Webアプリのコンテンツ提供の仕組み」について前回ご説明いたしました。まだ読まれていない方は、ぜひ、下記の記事を読んでいただければと思います。
今回の記事でご紹介するプログラムの実行には、上記の記事内でご説明した環境が必要となります。読み物として読まれる方は、このまま読み進めても問題ありません。
異なる性質のものを繋ぐ
生成AI(ChatGPTなどのLLM)は「曖昧な質問を何となくで回答する仕組み」です。プログラミングは「決められた事を間違いなく実行する仕組み」となります。このように全く異なる性質をもっています。
この相反する2つが協力して一緒に仕事をするためには、お互いの仕組みがコミュニケーションを取りながら動作しなくてはなりません。例えば、生成AIの曖昧な文章での回答をプログラムで利用出来るように、あらかじめ決められた型に当てはめなくてはいけません。
言葉が表現豊かであるが故の難しさ
プログラミングのみで型に当てはめる方法として…たとえば、生成された文字列に特定の文字が含まれていたら、こう動かす…というやり方が考えられます。
例えば下記のような言葉があるとします。
「海に行く」
この言葉を先ほどの方法を元に「海に行く」という意味かどうかを確認するプログラムを組むとなると…「海」と「行く」が入っていたら海に行くんだろう…のように判断させる事が出来ます。
しかし、上記の方法で理解させようとした場合…
「浜辺に向かう」
「シーサイドまで歩く」
「ビーチに移動する」
「海岸へと足を進める」
「海水浴に出かける」
…のような場合も全て「海に行く」という意味になるのに、そうでないと判断されてしまいます。
さらに…
「樹海に行く」
「海老の行く宛」
「海外企業の行く末」
「海王星の行く先」
などは、条件には当てはまっていますが、全然意味が違いますね。このように「特定の単語が出てきたら海に行くと判断させよう」とするのは非常に難しいです。
ではどうすれば良いのでしょう?
相反するものをどのように繋げるか?
これを実現するためには2つの方法が考えられます。
1.生成AIが区分(1が正解、2が間違いなど)や数字(%などの百分率など)のようなプログラム側で判断しやすい値で返す方法。昨今はJSONという形式で出力できるので便利。
2.単語や文章自体をベクトル化し、プログラムで扱う文字や値の意味との距離が近ければ同等であると判断させる方法。
1の方法はLLMをそのまま使うという最もオーソドックスな方法です。何でも応用が効くので、通常はこれを利用することになります。しかし、LLMの入出力はそれなりにコスト(処理時間やお金)がかかるため、全ての処理にLLMを利用していると非常に非効率です。たとえば100x100の文章の相関関係を求めるのには4950個の組み合わせがあります。コストを抑えながらこの組み合わせに対して、ひとつひとつLLMで解決させるのは非常に難しいと思います。さらにいうと生成AIは気まぐれなところがあるため、複雑な相関関係を一度に求めたりする場合に、安定した結果が得られるないという可能性もあります。
そこで2の単語や文章のベクトルを求める方法の出番となる訳です。
ベクトルって何だっけ?
ベクトル…と聞くと拒否反応を示す人もいるかと思います。ですので、ここで簡単に説明しておきたいと思います。
ベクトルというと矢印が思い浮かぶかと思います。しかし、AIにおけるベクトルを矢印でイメージすると理解が難しくなります。特徴や属性などの数字の集まりとしてイメージして下さい。例えば色の場合…
(赤,緑,青)=(255,255,0)
のような3つの数字で表せます。この例では光の三原色の原理から、黄色であることが分かります。そして、要素が3つあるため、「3次元ベクトル」と言えます。AIの世界では「数万次元ベクトル」なんて普通に登場しますので、とても矢印なんかではイメージ出来ないです。どうしても頭の中でイメージしたい場合は、高次元空間内で1つの点を決める…なんていう考え方が良い気がします。
embedding(埋め込み)を使おう
さて、この言葉のベクトル化ですが…embedding(埋め込み)という仕組みを利用します。この仕組みは最近流行りのRAG(Retrieval Augment Generation)でも使われている技術ですね。RAGの仕組み自体はそれほど難しくないのですが、これを思いついた人は凄いと思います。RAGの仕組みはAIとプログラミングがお互いコミュニケーションを取りながら動いている仕組みと言えます。そういう意味ではこの記事で行おうとしている事と同じようなものだと言えますね。
さて、OpenAIのembeddingを使っていこうと考えていますが、このembeddingのAPIは非常に処理が早くて安価です。text-embedding-3-smallというモデルの場合、ひとつの言葉を1536次元ベクトルの数値データとして返してくれます。より高次元のものを出力するモデルもありますが、まずは少ないものから試していきましょう!
ベクトルの類似性を求める
Open AIのAPIはその言葉のベクトルを求める時に使い、それ以外では使いません。組み合わせ全てをAPIで求める必要はありません。
具体的には下記のような計算式でお互いのベクトルの類似性(コサイン類似度)が計算出来ます。
ベクトルAとベクトルBのコサイン類似度 = (Aの各要素 × Bの各要素を掛けた和) / (Aの各要素の2乗の和の平方根 × Bの各要素の2乗の和の平方根)
これでコサイン類似度が求まります。計算の中身は考えなくても大丈夫です。コサイン類似度とは、その言葉と言葉が「どれだけ似ているのか?」とか「どれだけ関連性が深いのか?」を表すというぐらいの理解で問題ありません。
実際にプログラムを動かしてみよう!
下記がプログラムです。説明は必要でしたらChatGPTに聞けば良いので省略しますね。まずは動かしてみましょう!
htmlフォルダに適当な名前(例:EmbeddingsSample)のフォルダを作成し、index.htmlとして保存してください。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Text Similarity with OpenAI Embeddings API</title>
</head>
<body>
<div>
<label for="userText">比較するテキストを入力してください:</label><br>
<input type="text" id="userText">
</div>
<br>
<div id="inputFields">
<label>下記のテキストの中から最も関連性の高いものを探します:</label><br>
<button onclick="addTextField()">テキストを追加</button><br>
<input type="text"><br>
<input type="text"><br>
</div>
<br>
<button onclick="calculateSimilarity()">類似度を計算する</button>
<div id="results"></div>
<script>
let chatGptApiKey = window.prompt("Please enter your OpenAI API key:");
const endPoint = "https://api.openai.com/v1/embeddings";
const embeddingModel = "text-embedding-3-small";
// ベクトルの内積を計算する関数
function dotProduct(vecA, vecB) {
let product = 0;
for (let i = 0; i < vecA.length; i++) {
product += vecA[i] * vecB[i];
}
return product;
}
// ベクトルの大きさ(ノルム)を計算する関数
function norm(vec) {
let sum = 0;
for (let i = 0; i < vec.length; i++) {
sum += vec[i] * vec[i];
}
return Math.sqrt(sum);
}
// 2つのベクトル間のコサイン類似度を計算する関数
function cosineSimilarity(vecA, vecB) {
return dotProduct(vecA, vecB) / (norm(vecA) * norm(vecB));
}
// OpenAIのEmbeddings APIを呼び出す関数
async function getEmbedding(text) {
const response = await fetch(endPoint, {
method: 'POST',
headers: {
'Authorization': `Bearer ${chatGptApiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
model: `${embeddingModel}`,
input: text,
encoding_format: 'float',
})
});
const data = await response.json();
return data.data[0].embedding;
}
// テキストフィールドを追加する関数
function addTextField() {
const inputFields = document.getElementById('inputFields');
const newTextField = document.createElement('input');
newTextField.type = 'text';
inputFields.appendChild(newTextField);
inputFields.appendChild(document.createElement('br'));
}
// メインの処理
async function calculateSimilarity() {
const userText = document.getElementById('userText').value;
const inputFields = document.getElementById('inputFields').querySelectorAll('input');
const texts = Array.from(inputFields).map(inputField => inputField.value);
// ユーザーテキストと各テキストの距離を計算
const userTextEmbedding = await getEmbedding(userText);
const textEmbeddings = await Promise.all(texts.map(getEmbedding));
let mostSimilarTextIndex = -1;
let highestSimilarity = -1;
let results = '';
for (let i = 0; i < texts.length; i++) {
const similarity = cosineSimilarity(userTextEmbedding, textEmbeddings[i]);
if (similarity > highestSimilarity || highestSimilarity === -1) {
highestSimilarity = similarity;
mostSimilarTextIndex = i;
}
results += `The text most similar to "${userText}" is "${texts[i]}" with a similarity score of ${similarity}.<br>`;
}
if (mostSimilarTextIndex !== -1) {
const mostSimilarText = texts[mostSimilarTextIndex];
results += `最も"${userText}"に類似しているテキストは"${mostSimilarText}"です。`;
} else {
results += 'テキストが見つかりませんでした。';
}
document.getElementById('results').innerHTML = results;
}
</script>
</body>
</html>ブラウザを開いてURLを呼び出すと、まずは、前回のように最初にAPIキーを聞かれますので”sk-“ではじまるAPIキーを入力して下さい。
その次に比較するテキストと類似性を計算したいテキスト(複数)を入力して下さい。計算したいテキストを増やしたい場合は「テキストを追加」ボタンを推して下さい。入力が終わったら「類似度を計算する」ボタンを押して下さい。
下記のように結果が表示されるかと思います。
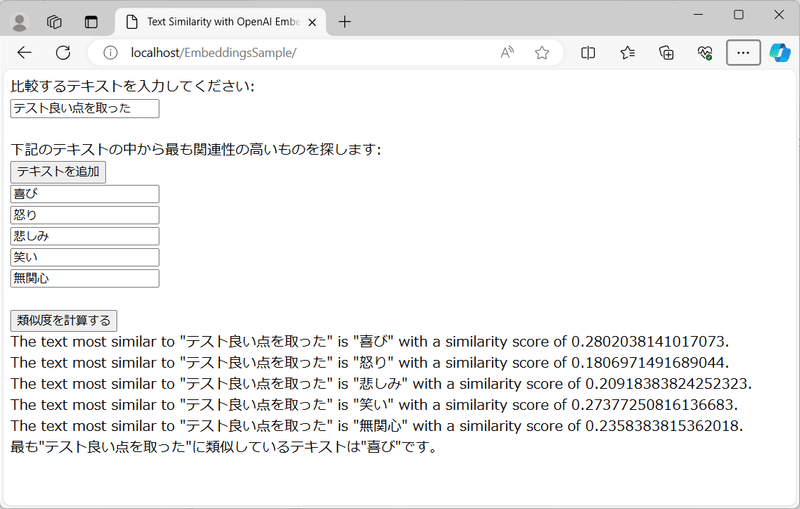
表示されましたか?
このプログラムを元に改造して、ぜひ、いろいろ試してみて下さい!
ファイルも置いておきますので、ご活用ください!
この記事が気に入ったらサポートをしてみませんか?