
オープンデータを集計してみる part2 境界データの加工

はじめに
2回目の今回はデータの具体的な入手方法や加工方法をテーマにしていきたいと思います。前回大した説明もせず、東京の地価公示データと小地域データをダウンロードしました。地価データの選定理由は「点データ」であるのと筆者個人がお金に興味がある程度の理由しかありませんが、小地域データを選んだ理由はそれなりにあります。今回はその辺に触れていけたらと思っている次第です。
ツールについては前回は可視化の際にQgisを使いましたが、今回はPythonを使います。
データの入手と概要
地価公示データ
前回も述べた通りですが、国土数値情報からデータをダウンロードします。具体的には、「1. 国土(水・土地)」の一番下に「地価」という項目があり、その中にある「地価公示(ポイント)」からデータを入手できます。年次や地域を選びダウンロードのアイコンを押せばいいので直感的でわかりやすいかと思います。
データの概要に触れていきます。経緯度からなるポイント形式の位置情報と付随する属性情報となります。データをダウンロードするとzip形式のデータが入手できます。解凍するといくつかデータが入っているかと思いますが、拡張子に「shp」か「geojson」があることを確認してください。
※データ形式などは別の機会に語ります。
小地域データの入手と加工
こちらも前回述べた通りです。e-Statからデータをダウンロードします。e-Stat接続後、「地図」→「境界データダウンロード」→「小地域」→「国勢調査」→「2020年」→「小地域(町丁・字等)(JGD2011)」と進みます。その後は「世界測地系緯度経度・Shapefile」→「13 東京都」→「13000 東京都全域」でダウンロードしました。
次にデータの加工をします。「町丁・字等」という単位は要するに「中央区銀座1丁目」というものです。今回はこれを「中央区銀座」というエリアにしたいのでデータを加工して「銀座」というエリアを作成していきます。
データ作成方法ですが、Pythonという言語を使い行っていきます。詳細は省きますが、コードと実行結果は以下のとおりです。
import geopandas as gpd
import matplotlib.pyplot as plt
import japanize_matplotlib
from shapely.geometry import Polygon, MultiPolygon
# データ読み込み
tokyo_small_erea_gdf = gpd.read_file('Data/r2ka13.shp')
tokyo_small_erea_gdf = tokyo_small_erea_gdf[
(tokyo_small_erea_gdf['CITY'].astype(int) <= 350) &
(tokyo_small_erea_gdf['KEY_CODE'].apply(
lambda x : True if len(x) > 8 else False)
)
]
tokyo_small_erea_gdf['group_key'] = tokyo_small_erea_gdf['KEY_CODE'].apply(
lambda x: x[0:8]
)
tokyo_small_erea_gdf['town_name'] = tokyo_small_erea_gdf['S_NAME'].apply(
lambda x: '' if x is None else x[0 : x.find('丁目') - 1] if '丁目' in x else x
)
# データ編集
tokyo_small_erea_gdf_d = tokyo_small_erea_gdf.dissolve(
by='group_key', aggfunc={"town_name":'first', "JINKO":'sum', "SETAI":'sum'}
)
tokyo_small_erea_gdf_d = tokyo_small_erea_gdf_d[
(tokyo_small_erea_gdf_d['town_name'] != '') &
(tokyo_small_erea_gdf_d['town_name'] != '‐')
]
# ポリゴンのリングを削除する関数を定義
def remove_interior_rings(geometry):
if geometry.geom_type == 'Polygon':
return [Polygon(geometry.exterior)]
elif geometry.geom_type == 'MultiPolygon':
cleaned_polygons = []
for poly in geometry.geoms:
cleaned_polygons.append(Polygon(poly.exterior))
return [MultiPolygon(cleaned_polygons)]
else:
return [geometry]
tokyo_small_erea_gdf_d['geometry'] = tokyo_small_erea_gdf_d['geometry'].apply(
lambda geom: remove_interior_rings(geom)[0]
)
# 地図描画
fig = plt.figure(figsize=(12, 10)) # figureオブジェクト作成
ax1 = fig.add_subplot(2, 1, 1) #2行1列の1番目
ax1.set_title('Before Dissolve')
tokyo_small_erea_gdf.plot(ax=ax1)
ax2 = fig.add_subplot(2, 1, 2) #2行1列の2番目
ax2.set_title('After Dissolve')
tokyo_small_erea_gdf_d.plot(ax=ax2)
txt1 = '出典:政府統計の総合窓口(e-Stat)(https://www.e-stat.go.jp/) 国勢調査(総務省)を加工して作成'
fig.text(0.35, 0, txt1)
plt.tight_layout()
plt.show()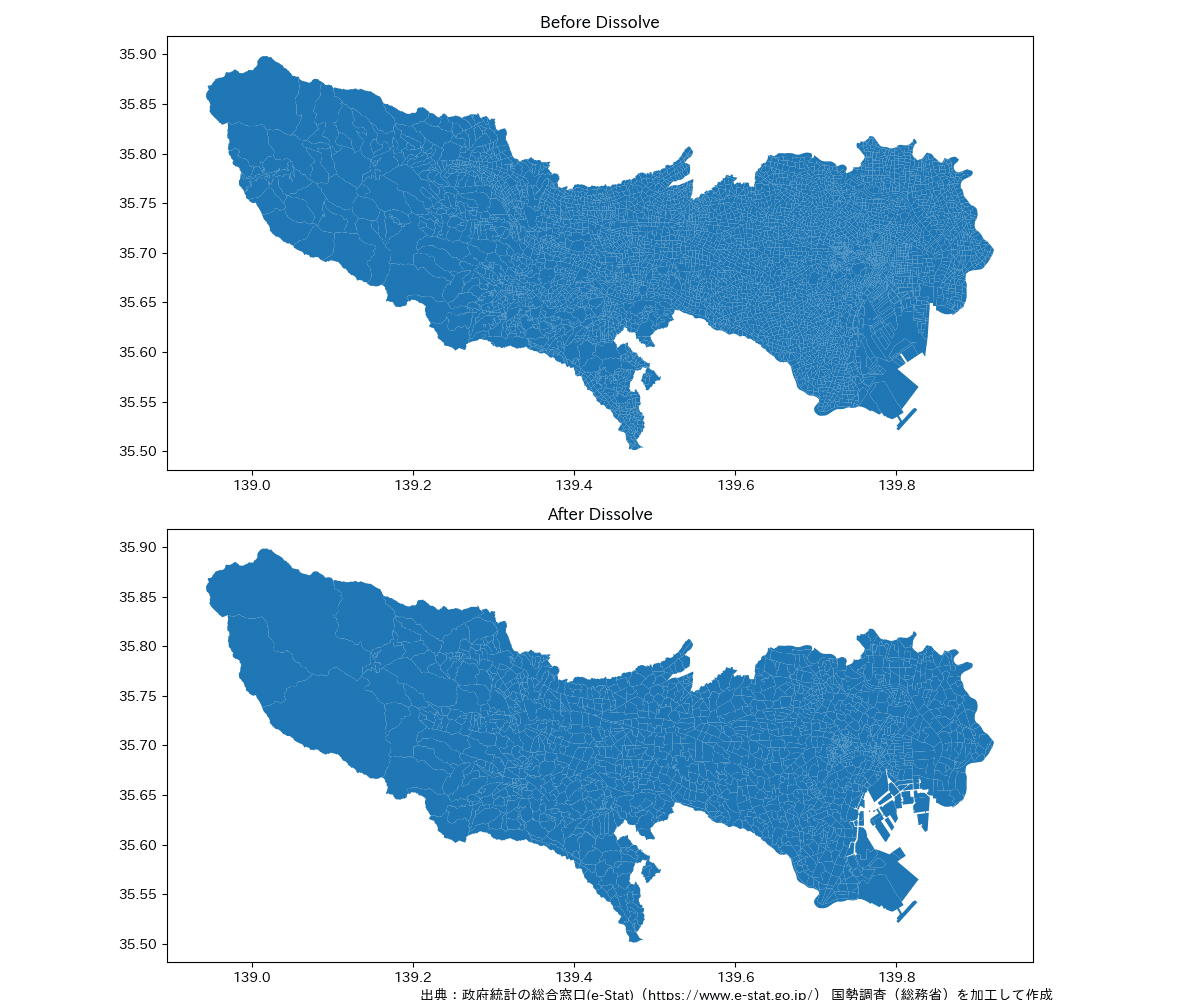
わかりにくいですが、上の図の境界を編集して下の図を作成したということです。
今回わざわざデータを加工した理由はですが大きく以下の2つです。
地価公示のポイントに対して、町丁目の面データはデータが細かすぎて集計があまり意味のあるものになってしまう可能性が高い
土地の値段について語るようなとき、「渋谷」や「銀座」など街の名前で語られることが多い
2つ目について詳しく説明します。例えば友人と遊びに行くプランを話していて、「どこいくー?」のような会話があった時、「渋谷行こう」みたいな返事になるかと思います。「渋谷区行こう!」とか「渋谷一丁目で遊ぼう〜」みたいな感じにはおそらくなりません。こういう場合の「渋谷」は漠然と街としての「渋谷」を指しているのでしょうが、そういうデータはオープンデータの中には見つからなかったので自分で作成することにしました。
おそらく日本には街を語るのが大好きな人が沢山いるはずなので、誰か作ってくれてもいいのに。。
これからの流れ
今回はデータ加工を実施しました。次回は実際に簡易的な集計をしていきます。内容としては作成した街ポリゴンに対して地価の平均などを集計していく予定です。
今回もありがとうございました!