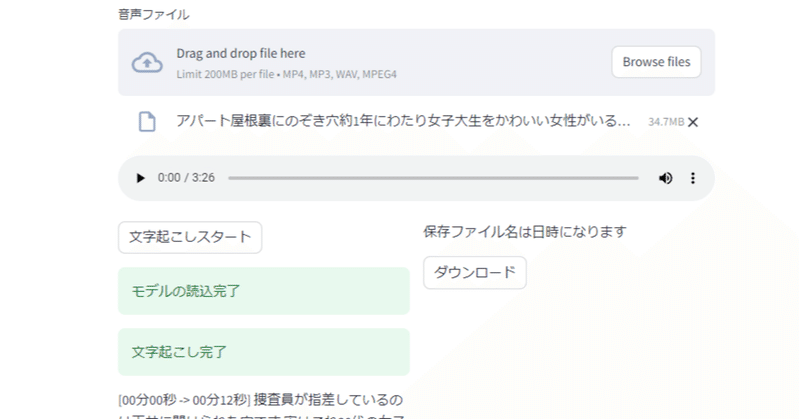
サクッと作った文字起こしWebアプリ

OpenAIのwhisperとstreamlitを使い、文字起こしWebアプリを作りました。
Streamlit Community Cloudの都合でwhisperのサイズの大きいモデルを使えないので、同じ制度で使えるfaster-whisperのmediumを使っています。
faster-whisper-large-v2はStreamlit Community Cloudでダウンロードができなかったので使っていません。
faster-whisperを使う理由としては、引用にある様に同じ制度を保ち、モデルの大きさを半分にしCPUでも高速で使えるため。
This implementation is up to 4 times faster than openai/whisper for the same accuracy while using less memory. The efficiency can be further improved with 8-bit quantization on both CPU and GPU.(原文)
この実装は、同じ精度を保ちながら、openai/whisperよりも最大4倍高速ですし、より少ないメモリを使用します。効率は、CPUとGPUの両方で8ビットの量子化を行うことでさらに向上させることができます。(翻訳)
試す分にはstreamlitに公開しているものいいのですが、小さいサイズのモデルやCPUを使っているので制度や変換が遅いです。
高速で大きいサイズのモデルを使いたい場合はローカルで実行が必要です。
これからローカルでの使い方を説明します。
ローカルでの使い方
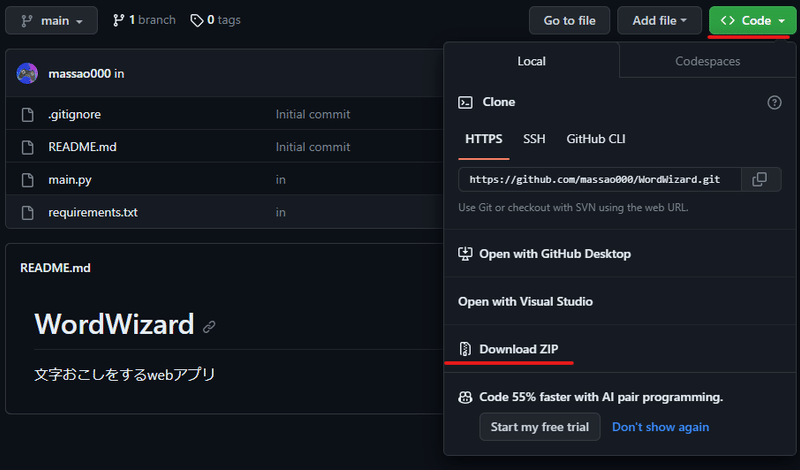
GitHubから必要なコードをダウンロードします。
簡単なダウンロード方方法
1.Codaをクリック
2.Download ZIPをクリック
環境作り
Pythonの仮想環境(venv)を作成します。
GitHubからダウンロードしたWordWizardのディレクトリに移動してコマンドを入力する
仮想環境の作成▼
$ py -m venv .venv
もしくは
$ python -m venv .venv.venvが仮想環境名になります。
環境起動▼
$ .venv\Scripts\activate環境に入った状態でパッケージをインストールします。
パッケージのインストール▼
$ pip install -r requirements.txt最終のディレクトリ構造
WordWizard
├─.venv
├─.gitignore
├─main.py
├─README.md
└─requirements.txt実行前に
一部のコードを変更します。
64行目のコメントアウトして、63行目をアンコメント(実行可能状態)します。
わからない場合は最後にコードを記載しているのでmain.pyにコピペしてください。
変更前▼
# model_size = "large-v2"
model_size = "medium"変更後▼
model_size = "large-v2"
# model_size = "medium"アプリの起動
コマンドプロンプトからコマンドを実行します。
$ streamlit run main.pyローカルで実行するmain.pyコード
from faster_whisper import WhisperModel
import streamlit as st
import datetime
from io import BytesIO
import math
import torch
def disassembly(seconds):
minutes = int(seconds // 60)
seconds = math.ceil(seconds % 60)
# 秒が60になる場合、分を増やし秒を0にリセット
if seconds == 60:
minutes += 1
seconds = 0
print(f"{minutes}分 {seconds}秒")
return str(minutes).zfill(2), str(seconds).zfill(2)
st.set_page_config(
page_title="Word Wizard App",
page_icon="✏️",
layout="centered",
initial_sidebar_state="expanded",
menu_items={
'Report a bug': "https://www.extremelycoolapp.com/bug",
'About': "# This is a header. This is an *extremely* cool app!"
}
)
st.markdown(
'''
whisperを使ってwebで文字起こしができるアプリになります。
''')
uploaded_file = st.file_uploader("音声ファイル", type=["mp4", "mp3", "wav"])
file_flag = False
download_flag = False
texts = []
device = "cuda" if torch.cuda.is_available() else "cpu"
if uploaded_file is not None:
upload_bytes = BytesIO(uploaded_file.getvalue())
if "mp4" in uploaded_file.name:
st.video(upload_bytes)
else:
st.audio(upload_bytes)
file_flag = True
col1, col2 = st.columns(2)
with col1:
start = st.button("文字起こしスタート")
if start and file_flag:
# placeholder_result = st.empty()
container = st.container()
with st.spinner('モデルの読込...'):
model_size = "large-v2"
# model_size = "medium"
model = WhisperModel(model_size, device=device, compute_type="int8")
container.success('モデルの読込完了')
with st.spinner('文字起こし中...'):
segments, info = model.transcribe(upload_bytes, beam_size=5, vad_filter=True)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
placeholder = st.empty()
with placeholder.container():
for segment in segments:
# out = f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}"
minutes_start, seconds_start = disassembly(segment.start)
minutes_end, seconds_end = disassembly(segment.end)
out = f"[{minutes_start}分{seconds_start}秒 -> {minutes_end}分{seconds_end}秒] {segment.text}"
st.write(out)
texts.append(out)
else:
# placeholder_result.success('文字起こし完了')
container.success('文字起こし完了')
download_flag = True
else:
pass
with col2:
if download_flag:
now = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
# title = st.text_input("保存ファイル名", now)
st.write("保存ファイル名は日時になります")
text = "\n".join(texts)
download_two = st.download_button("ダウンロード", text, f"{now}.txt")
else:
st.info("文字起こしが完了するとダウンロードボタンが出現します")
st.divider()
st.markdown(
'''
[X](https://twitter.com/siro020) [GitHub](https://github.com/massao000)
''')この記事が気に入ったらサポートをしてみませんか?