LLMを使ってデスクトップマスコットに命を吹き込む
Takaさんの「フィーちゃんをデスクトップマスコットにするのに本気を出した話」をベースに作っています。
同じものを使っても面白くないのでライブラリを変えたり、文章の生成をChatGPTからLLMに、合成音声をCevio AIからVOICEVOXに変えてやってみました。
テキストの送信以外にマイクで会話できる機能を追加しました。
あと、Unityを使うのはこれが初めてなのでコードに何かあればコメントをください。
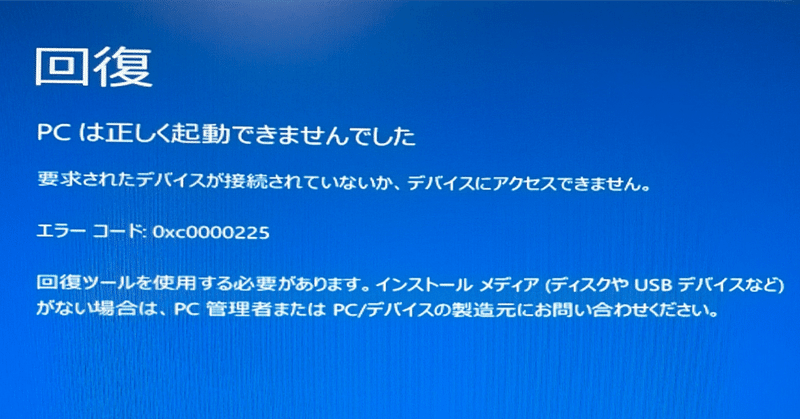
GPU使用率を見る感じ6GBでもギリギリ使えるようになってると