
乱立するAIモデルをすべて同じ方式で利用できる非常に野心的なサービスを解説!『Amazon Bedrock超入門』より 第2回 ~Bedrockとモデル(1)~

企業の基幹業務を支えるERPを理解するために、SAPの基礎知識からプロジェクトの進め方、ERPの運用に必要な業務知識まで基礎からわかりやすく解説した『Amazon Bedrock超入門』から書籍内容を抜粋してご紹介。第2回はChapter1「Amazon Bedrockを開始する」から「1-2 Bedrockとモデル(1)」です。
1-2 Bedrockとモデル
■ Bedrockコンソールを開く
Bedrock のページに移動すると、Overview という表示にBedrock の概要説明が表示されます。これは、Bedrock の入口となるところです。ここにある「使用を開始」というボタンをクリックすると、Bedrock のコンソールに移動します。

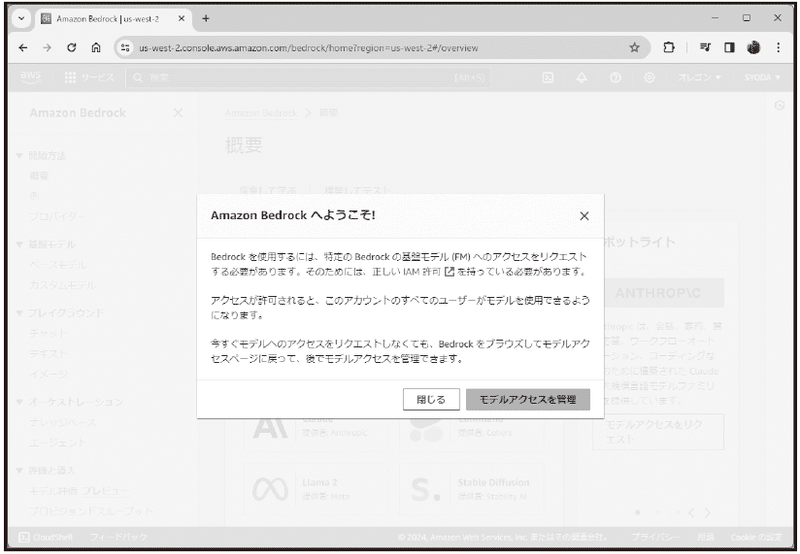
初めてアクセスしたときには、画面に「Amazon Bedrock へようこそ!」という表示が現れます。これは利用に関する注意書きで、Bedrock を利用するには特定の基盤モデルへのアクセスをリクエストする必要がありますよ、という説明です。そのまますぐに基盤モデルを使うのであれば、「モデルアクセスを管理」というボタンをクリックすればいいでしょう。ただし、ここではモデルの利用の前にBedrockコンソールについて見ておきたいので、「閉じる」ボタンで表示を閉じてください。
Column
リージョンに注意!
Bedrock を利用開始するとき、注意しておきたいのが「リージョン」です。AwS は世界中にデータセンターがあり、どこにプロジェクトを配置するか設定できます。これが「リージョン」です。画面の右上に表示されているアカウント名の左側の表示が、現在使っているリージョンになります。この部分をクリックすると利用可能なリージョンがプルダウンして現れ、変更することができます。
Bedrock には多数のAI モデルが用意されていますが、リージョンにより使えるモデルが変わります。最初は「バージニア北部(us-east-1)」というリージョンを使うようにして下さい。これはAWS の最初のデータセンターが設置されたリージョンで、AWS のすべての機能はこのリージョンから実装されていきます。その他のリージョンを選択した場合、AI モデルや一部の機能が使えないことがあります。
概要画面について
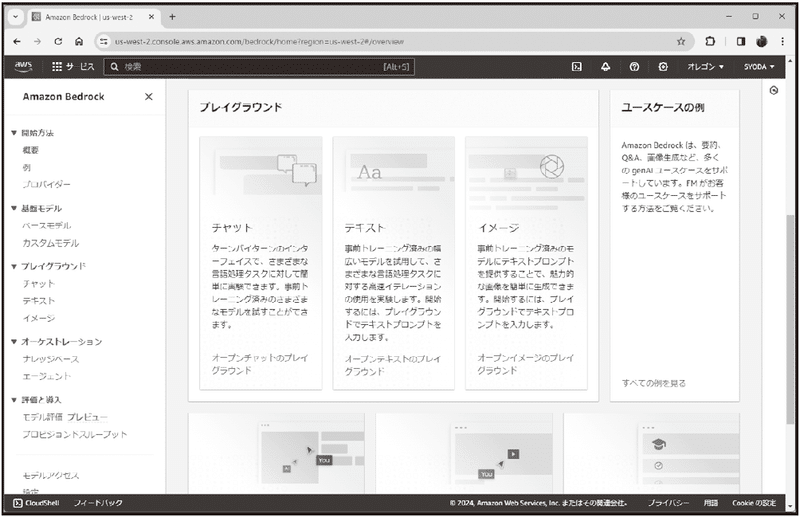
注意のメッセージを閉じると、「概要」という画面が現れます。これは、Bedrock のホームとなるところです。ここにはいくつかの情報が整理され表示されています。
最上部には「探索して学ぶ」という表示があり、そこに「基盤モデル」と表示されています。これは、「基盤モデル(後述)」と呼ばれるモデルの一覧です。ここから利用したいモデルの詳細情報のページを開くことができます。

その下には「プレイグラウンド」という表示があります。これは基盤モデルをその場で利用できる機能のリンクです。ここから使いたいプレイグラウンドをクリックして開くことができます。
基盤モデルとは?
ここで、「基盤モデル(Foundation model)」という用語が登場しました。基盤モデルというのは、AI モデルの中で「事前学習によりユーザーがモデルを訓練することなく広範囲なタスクを処理することができる汎用的な機械学習モデル」のことです。まぁ、わかりやすくいえば「何もしなくても最初から話したり作ったりできるようになっているモデル」ですね。
ChatGPT のようなモデルが登場する以前、AI モデルといえは、さまざまなタスクごとに自分で学習させて使うのが一般的でした。例えばテキストを生成するモデルでも、「英日の翻訳タスクのモデル」「テキストの要約をするモデル」というように、用途ごとにモデルが作成され、これらを個別に使って動いていたのですね。
その後、こうした特定の用途に限定したものでなく、それまでのモデルとは比較にならないほどの膨大なパラメータと学習データを使って訓練した「大規模言語モデル(Large Language Model、LLM)」と呼ばれるものが登場しました。こうしたLLM は、さまざまなタスクに対応でき、また事前に膨大なデータを元に学習済みであるため、自分でデータを学習させなくともすぐに使い始めることができます。更には、ほぼ完成されたモデルに自分のデータを追加で学習させてチューニングすることもできます。
こうした「どんなタスクも使える学習済みのLLM」が、基盤モデルです。基盤モデルは誰でもすぐに使うことができます。それまでのように、自分の目的に合わせてデータを用意して訓練する必要もありません。
現在、テキストやイメージを作る「生成AI モデル」と呼ばれるものが次々と登場していますが、これらはすべて基盤モデルに相当するものを利用しています。皆さんの頭の中にあるAI モデルのイメージは、この基盤モデルのことだと考えていいでしょう。本書でも、基盤モデルを使えるようになることを目標に説明をしていきます。
書籍目次
chapter1 Amazon Bedrockを開始する
1-1 Bedrockの準備
生成AIモデルの現状
AIプラットフォームの登場
Bedrockとは?
AWSを開始する
AWSにサインインする
1-2 Bedrockとモデル
Bedrockコンソールを開く
Bedrockコンソールのページ
基盤モデルを利用する
モデルの利用は「プレイグラウンド」から
chapter2 プレイグラウンドの利用
2-1 テキスト生成のプレイグラウンド
プレイグラウンドとは?
テキストのプレイグラウンド
モデル利用時のプレイグラウンド画面
他のモデルを試してみよう
AIは、文の続きを考える
チャットのプレイグラウンドについて
「テキスト」と「チャット」の違い
2-2 プロンプトデザインを理解しよう
プロンプトの基本
プレフィックスとサフィックス
例を使って学習させる
指示を補足する
日本語でダメなら英語で!
2-3 パラメータの働き
パラメータの種類
ランダム性と多様性のパラメータ
長さのパラメータ
Repetitionsのパラメータ
パラメータの使い方
chapter3 イメージのプレイグラウンド
3-1 イメージ生成を利用する
イメージのプレイグラウンドについて
プロンプトを書いて描かせよう
イメージ生成のプロンプト
さまざまな場所と状況
どんなイメージがほしいのか?
イメージ生成のパラメータ
「イメージ」のパラメータの調整について
3-2 より高度なモデルの利用
SDXLとTitan Image Generator G1
Titan Image Generator G1の画面
バリエーションの作成
パラメータについて
イメージ生成はコストに注意!
3-3 イメージの編集
Editモードとは?
イメージを編集する
マスクプロンプトを使う
編集は万能ではない
chapter4 SageMakerノートブックの利用
4-1 SageMakerとポリシーの準備
SageMakerとは?
Studioとノートブック
SageMakerを開く
ロールを作成する
ロールにポリシーを追加する
4-2 ノートブックの作成
ノートブックを利用する
ノートブックを起動する
コードを実行する
アイコンバーとサイドパネル
Bedrockの機能を利用する
SageMakerでノートブックを終了する
SageMakerダッシュボードで確認する
chapter5 Pythonによるテキスト生成モデルの利用
5-1 Colaboratoryを準備しよう
JupyterとColaboratory
SageMakerノートブックとColabの違い
Colabでノートブックを作る
コードを書いて動かそう
セルの働き
アイコンバーとツール類
AWSルートユーザーのアクセスキーを作成する
5-2 Bedrockのテキスト生成モデルを使う
BedrockとBoto3
Boto3からBedrockクライアントを作成する
プロバイダーのモデル情報を得る
特定モデルの情報を得る
特定モードの基盤モデルを得る
「# @param」について
モデルへのアクセスはBedrockではない
5-3 Bedrock Runtimeでモデルにアクセスする
BedrockとBedrock Runtime
invoke_modelでモデルにアクセスする
Titan Text G1-Expressを利用する
Titanのパラメータを指定する
Jurassic-2を利用する
Jurassic-2からの応答
Jurassic-2のパラメータ設定
Claudeを利用する
Claudeからの応答
Claudeのパラメータ設定
モデルのAPI仕様について
chapter6 Pythonによるイメージ生成モデルの利用
6-1 SDXLによるイメージ生成
イメージ生成とSDXL
SDXLにアクセスする
SDXLの戻り値について
Base64データのファイル保存
パラメータを利用する
パラメータを指定してイメージ生成する
ネガティブプロンプトについて
6-2 Titan Image Generator G1の利用
Titan Image Generator G1にアクセスする
Titan Image Generator G1のパラメータ
6-3 イメージの編集
SDXLのイメージ編集
編集用のパラメータ
イメージのバリエーションを生成する
マスクイメージを使う
Titan Image Generator G1のイメージ編集
chapter7 生成モデルを使いこなす
7-1 生成モデルの様々な機能
ストリームを利用する
ストリームで応答を受け取る
チャット機能を実装する
7-2 ベンダー提供パッケージ
Jurassic-2のパッケージについて
ai21.Completionを利用する
複数の応答を得る
Claudeパッケージの利用
completions.createでアクセスする
チャットとして利用する
Claudeのストリーミング利用
Bedrockで提供されていない機能は使えない
chapter8 LangChainの利用
8-1 LangChainを使う
LangChainとは?
LangChainの準備を整える
LangChainでBedrockにアクセスする
パラメータの指定
8-2 LangChainでチャットを行う
チャットを利用する
チャットを使いこなす
チャットの連続実行
ConversationChainを利用する
8-3 テンプレートの利用
テンプレートの利用
PromptTemplateクラスの利用
テンプレートを使ってみる
チャットテンプレート「ChatPromptTemplate」
ファイルを要約する
関数で前処理・後処理を行う
RunnableSequenceの仕組み
関数とRunnableLambda
LangChainの世界はもっともっと広い!
chapter9 Python以外の環境におけるBedrock利用
9-1 curlによるBedrockの利用
HTTPアクセスとcurl
curlコマンドについて
Jurassic-2にアクセスする
Colabでcurlを実行する
Titan Text G1-Expressを利用する
SDXLでイメージを作成する
9-2 JavaScriptからBedrockを利用する
AWS JavaScript SDKについて
プロジェクトを作成する
Visual Studio Codeを利用しよう
JavaScriptからBedrockにアクセスする
Titan Text Express-G1を利用する
Claudeを利用する
SDXLでイメージを生成する
curlを利用してBedrockにアクセス
その他にもBedrock用パッケージはある!
chapter10 Embeddingとセマンティック検索
10-1 Embeddingとその利用
Embeddingとは?
Titan Embeddings G1-Textを使う
セマンティック類似性
コサイン類似度の関数を用意する
セマンティック類似性の関数を用意する
プロンプトどうしのセマンティック類似性を調べる
10-2 セマンティック検索
セマンティック検索とは?
用途に合うパソコンを選定する
検索プログラムを作る
セマンティック検索の用途
10-3 マルチモーダルEmbedding
マルチモーダルのEmbedding
マルチモーダルEmbeddingを使う
イメージとイメージのセマンティック検索
似ているイメージを検索する
テキストでイメージを検索する
Embeddingはもう1つの生成モデル
この記事が気に入ったらサポートをしてみませんか?