これは衝撃!1.5Bで超高性能LLM!RWKV-5-World-v2

Transformerという手法は必ずしも万能でも効率的でもない。
むしろTransformerは非効率的だというのが一般的な見解だ。しかし、Transformerには実績があり、実績という壁の前には多少(かどうかわからないが)の非効率は無視される。
他にもHyenaなどもっと効率的と思われる手法が提案されているが、そうした提案の一つがRWKVである。
そもそもなぜTransformerが必要になったかというと、それまで言語モデルに用いられていたRNN(Recurrent Neural Network)は並列処理が難しかったからだ。並列処理が難しい理由は簡単で、言葉というのは過去から未来へ向かって一方向に進むからである。
言語モデルは全て「この文章に続く単語は何か」を予測し、それを連鎖的に繰り返していくが、RNNは単語をひとつひとつ選んでいかないと次の単語を原理的に予測できない。
これを並列化するためにRNNのような構造をやめて、文章中の単語感の関係をKey,Value,Queryという単位で分散的に把握し、注意機構で「どの単語に注目すると次の単語がわかるか」を学習するのがTransformerである。
並列化が可能な分、効率が悪くなるのは原理的な問題とも言える。
それに対してRWKVは、RNNの構造を保ちながらも並列化を実現するアルゴリズムだ。

RWKVではQuery,Key,Valueではなく、R、W、K、Vというパラメータの学習を行う。だからRWKV(ルワクフ)と呼ぶ。
通常のRNNでは時間とともに減衰していくゲートと呼ばれる機構が必要で、このせいで並列化ができないが、RWKVではWの値を変化させるだけで同様の時間減衰を表現できる。
しかも、できあがったニューラルネットは行列と行列の積は用いず、行列とベクトルの積のみで計算可能で、スマートフォンやスマートウォッチなどで高速な推論ができるとされていた。
これまでもRWKVは繰り返しウォッチしていたが、今回発表されたRWKV-5-World-v2は次元の違う性能になっていると感じたので再び紹介する。
RWKV-5-World-v2はわずか1.5Bサイズであり、これはかなり小さくて高性能とされているLlama2-7Bの1/4以下のサイズということになる。そのうえ、Llama2は日本語性能が低いのだが、RWKV-5-World-v2は英語はもちろん日本語性能が極めて高いように感じる。
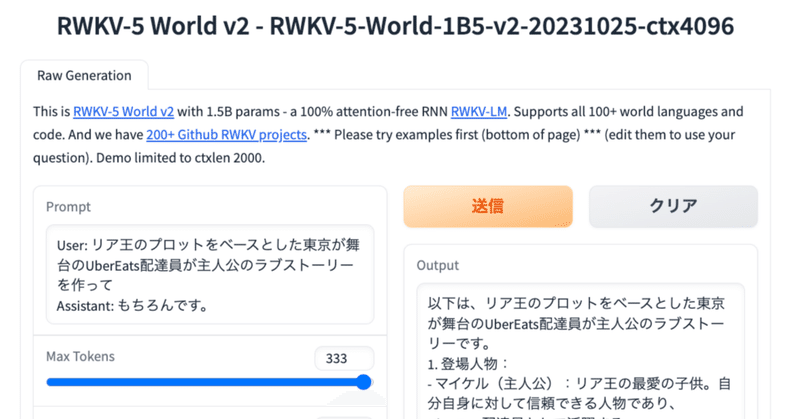
たとえばこんな会話が可能だ。
User: リア王のプロットをベースとした東京が舞台のUberEats配達員が主人公のラブストーリーを作って
Assistant: もちろんです。
以下は、リア王のプロットをベースとした東京が舞台のUberEats配達員が主人公のラブストーリーです。
1. 登場人物:
- マイケル(主人公):リア王の最愛の子供。自分自身に対して信頼できる人物であり、UberEats配達員として活躍する。
- ミッキー(配達員):UberEats配達員で、マイケルと同じくらい信頼できる存在。彼はマイケルと同じくらい強い感情を抱いており、彼との関係も深い。
- ジョン(親友):リア王の親友で、UberEats配達員でもある。彼はマイケルと同じくらい信頼できる存在であり、彼との関係も深い。
2. ストーリー:
- マイケルとミッキーは幼馴染みであり、一緒に過ごす日々が楽しいものだった。ある日、両者が UberEats配達員として働き始めた。
- UberEats配達員として働くことで、両者はより多くの時間を共有しながら仕事をしていけるようになった。しかし、UberEats配達員として働いているうちに様々な問題やトラこんな文章がわずか1.5Bのモデルから出てくるのはそれだけで驚異的だ。
まだ日本語能力ベンチマークを走らせていないが、これからやるつもりである。
その脅威の性能は軽量ゆえにだれでもHuggingFace Spacesで試すことができる。
ぜひお試しあれ