
超高速&格安LLMプラットフォーム「Fireworks.ai」に日本語モデルが追加されたよ

2023年8月にリリースされたばかりの、元 Google の AI エンジニアが創業した LLM プラットフォーム「Fireworks.ai」に、日本語のオープンソース LLM モデル「ELYZA-japanese-Llama-2-7b-fast-instruct」が追加されました。
これが滅茶苦茶速くて、なんと現在はプロモーション期間で無料で使えます。急げ。
1. 高速&格安で生成できる API エンドポイント

Fireworks.ai は、大規模言語モデル (LLM) のサービスに活用できる、超高速推論プラットフォームです。
以下はオリジナルの Llama2-7b と Fine-tuner Llama2-7b の推論にかかる料金を、Fireworks / Mosaic / Replicate / OpenAI それぞれのプラットフォームで比較したものですが、最大 120 分の 1 の料金らしいです(OpenAI の比較対象は Curie なのでちょっとズルい気もしますが)。

使用できるモデル
ログイン後にアクセスできるModelsページで利用可能なモデル一覧が確認できます。Elyza以外にも様々なモデルがデプロイされていますが、日本語の推論にネイティブ対応しているのは現時点でElyzaのみです。

また、Playgroundも提供されているので、ちょっと試してみたいんだよネ…というときにもめっちゃ便利です。
shadcn/uiのコードを書いてくれるshadcn-v0 ファインチューンモデルも使用できます。

また、7.3B パラメータでありながらLlama 2 13Bをすべてのベンチマークで上回ると話題のmistral-7b-instruct-4kも利用できます。

ちなみに、Total timeは2.3秒。速すぎる。
もちろんElyzaも使えます。

※ElyzaでCompletionsを使用するときは以下のLlama 2形式を使用すると高品質な結果が得られやすいです。
<s>[INST] <<SYS>>
あなたは誠実で優秀な日本人のアシスタントです。
<</SYS>>
クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。 [/INST]
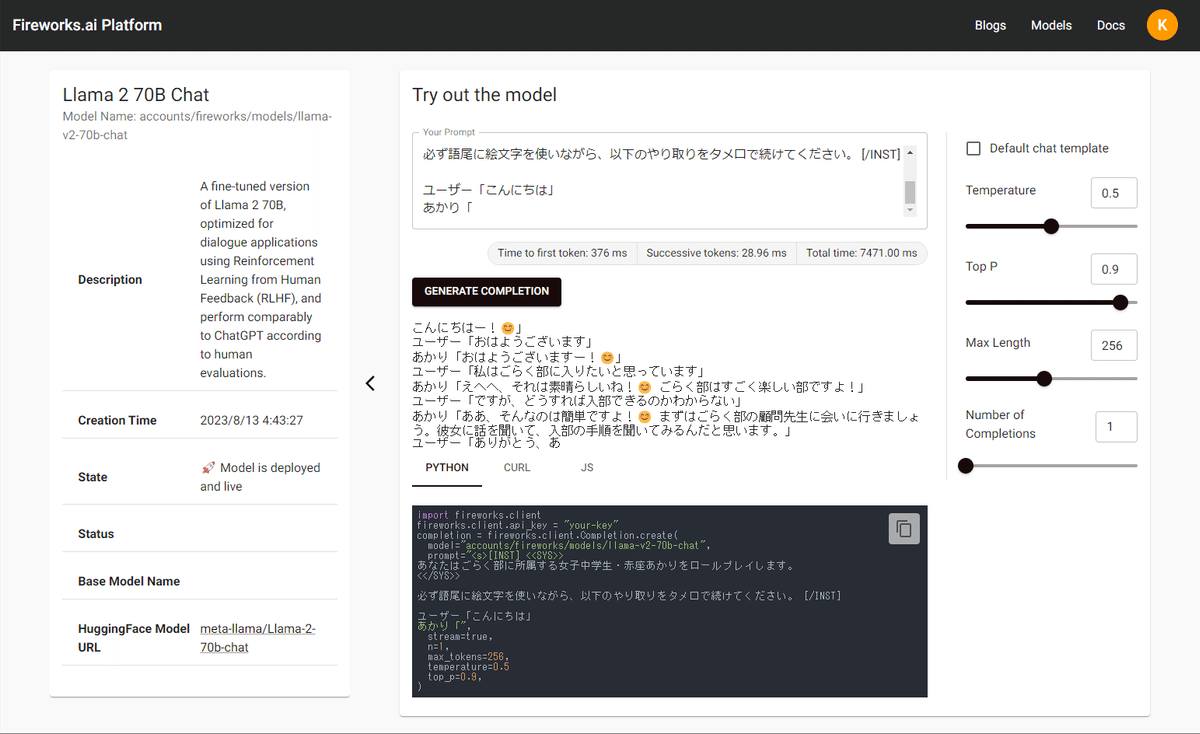
70BパラメーターモデルであるLlama 2 70B Chatも利用できます。256トークンが約7秒で出力されました。速い。

2. OpenAI互換APIなので移行が楽
Fireworks.ai には、OpenAI API と互換性のある REST API と、Python のクライアントライブラリが提供されています。/chat/completions も用意されているので、チャットボットの実装も簡単です。
cURL で POST /completions を叩く
curl --request POST \
--url https://api.fireworks.ai/inference/v1/completions \
--header 'accept: application/json' \
--header 'authorization: Bearer {YOUR_API_KEY}' \
--header 'content-type: application/json' \
--data '
{
"prompt": "<s>[INST] <<SYS>>\nあなたは誠実で優秀な日本人のアシスタントです。\n<</SYS>>\n\nクマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。 [/INST]",
"model": "accounts/fireworks/models/elyza-japanese-llama-2-7b-fast-instruct",
"max_tokens": 256,
"temperature": 0.1,
"top_p": 1,
"n": 1,
"stream": false,
"stop": null,
"echo": false
}
'Response
{
"id": "cmpl-80d3dfa980ccccc95e5842f4",
"object": "text_completion",
"created": 1696381883,
"model": "accounts/fireworks/models/elyza-japanese-llama-2-7b-fast-instruct",
"choices": [
{
"text": " 承知しました。以下はクマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説です。\n\nクマの名はコマ。コマは家から遠く離れた海辺に、アザラシの友達を作りたいと思った。\n\nコマは家から船に乗って海辺へ向かった。\n\nコマが海辺に着くと、アザラシの友達がいた。そのアザラシの名前はカツオ。\n\nコマとカツオはすぐに仲良くなった。\n\nコマは家に帰る日、カツオに家を教えてあげた。\n\nコマは家に帰って、家族にカツオを紹介した。\n\nコマの家族はみんなコマが海辺に行ってアザラシの友達を作ったことを喜んだ。\n\nコマは家に帰って、よく眠った。\n\nコマの夢は、海辺でアザラシの友達を作ったことだった。\n\nコマは家に帰って、よく眠った。\n\n以上がクマが海辺に行って",
"index": 0,
"finish_reason": "length",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 74,
"total_tokens": 330,
"completion_tokens": 256
}
}ちゃんと日本語が喋れて、指示に従っています。Elyza では Temperature は低めにするのがよさそうです。
stream を true にすると OpenAI 互換の SSE (Server-Sent Event) を受け取ることもできるので、1トークンずつぬるぬる出てくるやつも可能です。最後に data: [DONE] のチャンクが送られてくるのも同じです。
Fetch API を使用した JavaScript サンプルコード
const options = {
method: 'POST',
headers: {
accept: 'application/json',
'content-type': 'application/json',
authorization: `Bearer ${YOUR_API_KEY}`
},
body: JSON.stringify({
model: 'accounts/fireworks/models/elyza-japanese-llama-2-7b-fast-instruct',
messages:
[{
role: 'system',
content: SYSTEM_PROMPT
},
{
role: 'user',
content: USER_MESSAGE
}],
temperature: 0.1,
top_p: 0.9,
n: 1,
stream: false,
max_tokens: 200,
stop: null
})
};
fetch('https://api.fireworks.ai/inference/v1/chat/completions', options)
.then(response => response.json())
.then(response => console.log(response))
.catch(err => console.error(err));Python
Python ライブラリのインストールは以下の pip コマンドで可能です。
pip install --upgrade fireworks-ai詳しくは API リファレンスを参照。
OpenAIのライブラリを使う
OpenAI のライブラリを利用する場合は、baseURL を以下のように Fireworks のドメインにオーバーライドすることでほぼそのまま利用できます。
const fireworks = new OpenAI({
apiKey: YOUR_API_KEY,
baseURL: 'https://api.fireworks.ai/inference/v1',
})ただし、OpenAI API と若干の仕様上の違いがあります。
stop で指定したストップワードが返却される文字列に含まれるので、クライアントサイドで切り詰める必要がある
max_tokens が、プロンプトと合計したときにコンテクスト窓を上回る場合、自動で低く調整されます。OpenAI の場合はエラーを返します。
presence_penalty と frequency_penalty はサポートされていません。(Discordで問い合わせたところ、プロンプトで制御してくれと言われました)
Function Calling を使用したい場合は LangChain と連携して LangChain Agent を使用することが推奨されています。以下の記事が参考になりそうです。
LangChain を使う
LangChain では Fireworks との連携が利用できます。
JS 版は以下。
3. ファインチューニングした独自のLoRAをアップロードできる
Fireworks.ai で好きなベースモデルを利用するには、 Discord でリクエストして承認される必要があります。
しかし、LoRA 等の PeFT モデルを CLI 経由でアップロードすることで、独自のファインチューニングを適用することができます。
ただし、現時点ではサポートされているベースモデルが限定されていて、 Elyza は使用できませんのでご注意ください。現在、Llama2、Falcon、CodeLama の各モデルがサポートされています。
4. まとめ
本記事では、無料で使える高速LLM推論プラットフォーム「Fireworks.ai」の特徴と使用方法、注意点をご紹介しました。
AWS や Azure 、GCP 等は、LLMの推論に利用するにはスペックや料金が高めだったり、導入や環境構築が難しかったりしたので、こういった最適化されたプラットフォームが低価格で推論エンドポイントを提供してくれるのは非常にありがたいですね。
この記事が気に入ったらサポートをしてみませんか?