
AIの進化を支えるベクターデータベースの役割

ジェネレーティブAIの急速な発展に伴い、大量のデータを効率的に処理するためのベクターデータベースの重要性が高まっています。この記事では、ベクターデータベースの市場動向とそれがジェネレーティブAIにどのように貢献しているかを探ります。
ベクターデータベースとは
定義: ベクターデータベースは、複雑なデータ構造を効率的に処理するために設計されたデータベースの一種です。
特徴: 高次元のベクターを扱う能力があり、伝統的なデータベースよりも高度なデータ分析と検索機能を提供します。
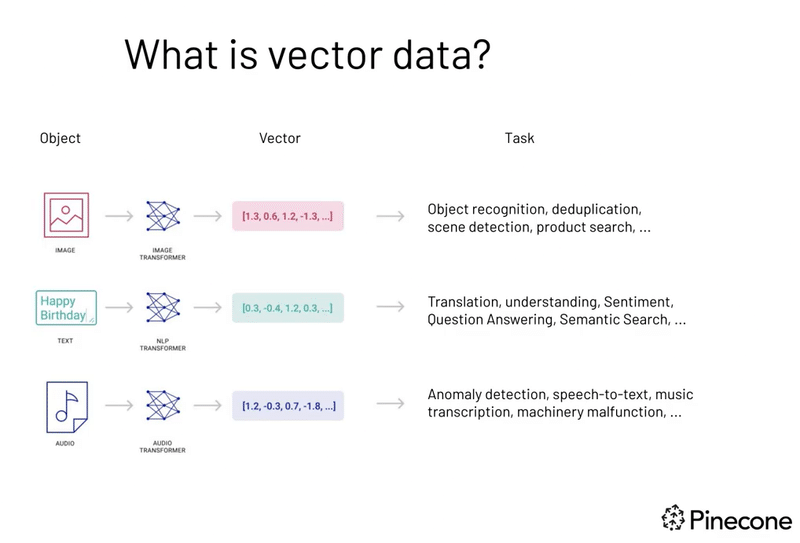
大量データの収容
ジェネレーティブAIの要求: ジェネレーティブAIは膨大なデータを必要とし、これを効率的に管理するためにはベクターデータベースが不可欠です。
データ量の増加: AIモデルの訓練には大量のデータが必要で、この増加するデータ量を管理するのにベクターデータベースが適しています。
精度の高い類似検索とマッチング
検索の課題: AIモデルから生成されるテキストは類似検索やマッチングを必要としますが、従来のキーワードベースの検索方法では不十分です。
ベクターデータベースの利点: これらのデータベースは、複雑な意味論や文脈に基づいて高い関連性と効果を発揮します。
どのように仕事するか:ベクターデータベースの機能として以下のポイントを挙げることができます:
高次元ベクトルデータを用いた迅速な類似性検索の実行。
非構造化データを数値ベクトルに変換して格納し、複雑なデータ型の検索を可能にする。
フォールトトレランスを備えたアーキテクチャにより、システムのダウンタイムを防ぐ。
低遅延での検索性能を提供し、リアルタイムの応答をサポート。
様々なクラウド環境での柔軟なデプロイメントが可能。

マルチモーダルデータ処理のサポート
データの多様性: ジェネレーティブAIはテキストだけでなく、画像や音声などのマルチモーダルデータを扱います。
データベースの対応能力: ベクターデータベースはこれらの多様なデータタイプの処理に適しており、効率的な保存、索引付け、クエリ処理を可能にします。
ベクターデータベースの市場動向
トップ5のデータベース: Yingjun Wu(Founder of RisingWave)のブログによると、市場で注目されているベクターデータベースには、Elasticsearch, Milvus, Pinecone, Weaviate, そしてQdrantが含まれます。Wuさんがこれらの主流なDBらをランドスケープでまとめました。
各データベースの特徴: これらのデータベースはそれぞれ異なる特性を持ち、特定の用途や性能要件に応じて選択されます。

ベクターデータベースの選び方
特定のアプリケーションやニーズに応じて適切なベクターデータベースを選択することが重要です。以下は、異なるシナリオや要件に基づいて適切なデータベースを選択するためのガイドラインです:
Chroma
適用例: ラージランゲージモデル(LLM)アプリケーションの開発
利点: 知識、事実、技能をLLMに容易に組み込める。テキスト文書の管理、テキストからの埋め込みへの変換、類似性検索などの機能が豊富。

Pinecone
適用例: 高次元データに関連するユニークな課題に取り組む大規模な機械学習アプリケーション
利点: 完全に管理されたサービス、高拡張性、リアルタイムデータ取り込み、低遅延検索。

Weaviate
適用例: 多様なMLモデルからのデータオブジェクトとベクター埋め込みの保存、数百万のオブジェクトからの高速検索が必要なケース
利点: 高速検索、柔軟性、スケーラビリティ、セキュリティ、推薦、要約、ニューラル検索フレームワークとの統合。

Faiss
適用例: 密集ベクトルの迅速な類似性検索やクラスタリング、大規模なベクトルセットの検索
利点: C++でコーディングされた高速検索アルゴリズム、Python/NumPyとの完全な統合、GPU実行のサポート。

Qdrant
適用例: 高次元ベクトルの類似性検索、マッチング、推薦、その他の複雑なタスク
利点: 多様なAPI、速度と精度、高度なフィルタリング、様々なデータタイプのサポート、スケーラビリティ、リソース使用の最適化。
これらのベクターデータベースは、それぞれ異なる特徴と強みを持ち、特定の要件やアプリケーションに最適化されています。適切なデータベースを選択することで、効率的なデータ管理と高度な検索機能を実現することができます。
今後の展望
市場の成長: AI技術の進展に伴い、ベクターデータベースの市場も拡大しています。
市場の成長については、ベクターデータベースの世界市場規模は2023年の15億米ドルから、予測期間中に23.3%のCAGRで拡大し、2028年までに43億米ドルに成長すると予測されています。(ソース:https://www.gii.co.jp/report/mama1374760-vector-database-market-by-offering-solutions.html)
技術革新: 新しい技術の開発により、これらのデータベースはより高速で効率的なデータ処理を可能にし、AIアプリケーションの範囲を広げています。
結論
ジェネレーティブAIの進化と共に、ベクターデータベースはこれらのモデルが生成する膨大なデータを管理し、精度の高い検索とマッチングを可能にし、多様なデータタイプの処理をサポートする重要な役割を果たしています。上記ピックアップしたベクターデータベースは、この分野でのイノベーションと市場の成長を象徴しており、今後もAI技術の発展に大きく貢献していくことが期待されます。
この記事が気に入ったらサポートをしてみませんか?