
インデックスってなんだ? 入門編

ここ最近の業務で、頻繁に「SQLのパフォーマンスチューニング」系のバグ対応をすることがあり、知識不足を痛感したので「インデックス」についてのおさらいをしようと思う。
最低限インデックスは知っておこう
経験者ならソロでガンガンタスクを進めていけると思うが、そうでない人はメンバーと相談しあって進めることになる筈。
その会話の中に出てくる言葉の解像度が、有識者と同じ水準じゃないと「何を言っているのかわからない」状態になっていつまでも進まない。
そんな状況に陥らないように、最低限ディスカッションを成立させるための知識をここで身につけよう。
1.超ざっくりインデックスを説明すると……
DBにおけるインデックスとは抽出対象のレコードを効率的に取得するための索引のようなものでウンタラ…………
ともかく、SQLのパフォーマンスについてディスカッションするときに“インデックス”を知らないのでは話にならないというレベルのもの。
文字で言われても(俺は)頭に入ってこないと思うので、図にしてみた。
例えばこんなクエリを想定してみる。
SELECT 会員ID, 店舗コード, 氏名
FROM なんか会員情報管理してるテーブル
WHERE 店舗コード = 'T01'これをインデックスなしで実行するとき、オプティマイザは保存されているデータ順に検索して行くことになり、最悪レコード数最大値ぶんの計算をする羽目になるだろう。

そこでインデックス。
冒頭でチラッと書いたように、インデックス ≒ ソートされた索引を作っておくことで、検索にかかる計算量を減らすことができる。

ざっくり「インデックスは索引のようなもの」と分かったところで、もう少し深掘りしてみる。
インデックス有りの検索(インデックススキャンとか呼ばれてる)をするとき、どんなアルゴリズムで動いているのかを理解していこう。
インデックスによく使われるアルゴリズム…「B-Tree」は、要するに「中央値より大きいか、小さいか」を繰り返し計算するやり方のこと。
文字で言われてもわからないと思うので、ソートされた数字列から 2 を取得するアルゴリズムを想定した図を作ってみた。
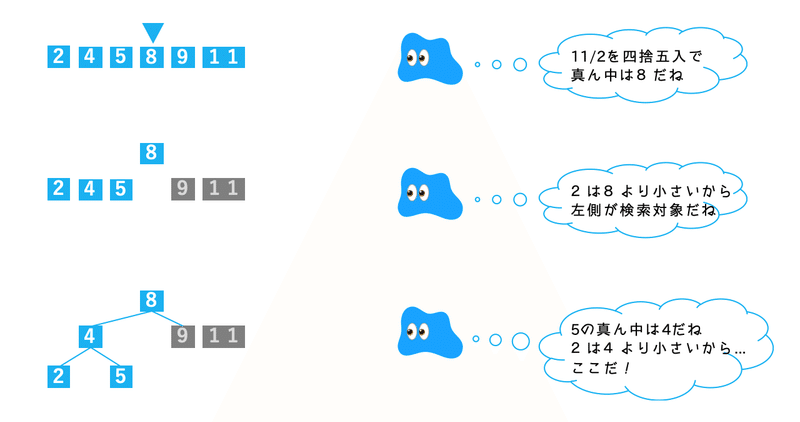
インデックス無しのフルスキャンと比べると、その計算量の少なさがわかるだろう。
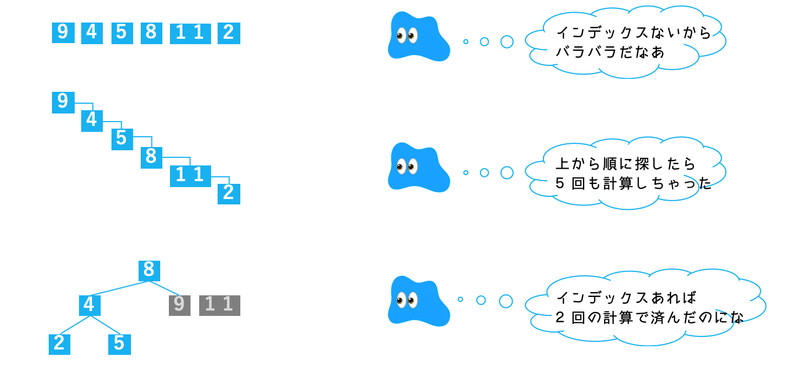
これがインデックスを使うとなんで速くなるのか、の超ざっくり回答。
正直今のタスクレベルではこれだけ知っておけば困りはしないかなって感じ。
これくらいはパッと人に説明できるといいね。
2.良いインデックス / 悪いインデックス!?
インデックスをつけると計算量が減るのか!よしインデックスをつけよう!
……でうまくいくほど単純な話ではないようだ……..。
どういうことかというと、索引をつけて検索量を減らすためには、その索引でどれだけデータが絞り込めるのか?を考えなきゃだめってこと。
例えば…なんかのテーブルの「性別」カラムを絞り込むインデックスは、
「男」「女」の2パターンにしか絞り込めない。
それってわざわざインデックスで絞り込む意味ある?という話。
では「良いインデックス」とはどんなものか?
結論:種類が多いもの。ユニークIDとか更新日とか。
種類が多いもの=索引でめっちゃ絞り込める。この概念は頭の片隅にしっかり置いておこう。
3.よくある誤解
インデックスについて「こうするべき!」みたいな通説はネット上に散見されるけど、その中には誤解も多いからここで訂正して間違った知識をつけないように気をつけよう。
”NULL”はインデックスが使えない?
→ IS NULL / IS NOT NULL は普通に使えるよ。
NOT IN はインデックスが使えない?
→ そんなことない、使えるよ。
WHERE句の条件はインデックス指定順に合わせる?
→ オプティマイザが勝手に良い感じに実行してくれるから関係ないよ。
4.入門編最後に
ここに書いたことは多分、知ってて当たり前くらいの感じでエンジニアは会話してるから、知らないとマジでやばいと思う。忘れたら読み返してインデックスに対するイメージは固めていこう。
次は複合インデックスについてを応用編として書くつもり。
この記事が気に入ったらサポートをしてみませんか?