pandasの基本をざっくりまとめてみる

pandasとは?
公式サイトの説明はこちらから↓
Wikipediaさんによる説明↓
pandasは、プログラミング言語Pythonにおいて、データ解析を支援する機能を提供するライブラリである。特に、数表および時系列データを操作するためのデータ構造と演算を提供する[1]。PandasはBSDライセンスのもとで提供されている[2]。
ざっくりいうと、pythonで配列を扱う際にわかりやすく表示させたり、配列のデータをいじったりしやすくするためのモジュール。
やっていこう
Series
Seriesとは、1次元配列のようなオブジェクト。pandasのベースはnumpyのarray。
作成してみる↓
from pandas import Series, DataFrame
import pandas as pd
# Series
sample_pandas_data = pd.Series([0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
print(sample_pandas_data)出力結果↓
0 0
1 10
2 20
3 30
4 40
5 50
6 60
7 70
8 80
9 90
dtype: int64indexを指定する
# index を alphabetで
sample_pandas_index_data = pd.Series(
[0 ,10, 20, 30, 40, 50, 60, 70, 80, 90],
index=['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'])
print(sample_pandas_index_data)出力結果↓
a 0
b 10
c 20
d 30
e 40
f 50
g 60
h 70
i 80
j 90
dtype: int64それぞれを取り出す。
print('データの値:', sample_pandas_index_data.values)
print('インデックスの値', sample_pandas_index_data.index)出力結果↓
データの値: [ 0 10 20 30 40 50 60 70 80 90]
インデックスの値 Index(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'], dtype='object')DataFrameを使う。
attri_data1 = {'ID': ['100', '101', '102', '103', '104'],
'City':['Tokyo', 'Osaka', 'Kyoto', 'Hokkaido', 'Tokyo'],
'Birth_year': [1990, 1989, 1992, 1997, 1982],
'Name':['Hiroshi', 'Aiko', 'Yuki', 'Satoru', 'Steve']}
attri_data_frame1 = DataFrame(attri_data1)
print(attri_data_frame1)出力結果↓
ID City Birth_year Name
0 100 Tokyo 1990 Hiroshi
1 101 Osaka 1989 Aiko
2 102 Kyoto 1992 Yuki
3 103 Hokkaido 1997 Satoru
4 104 Tokyo 1982 Steveindexをアルファベットに変える。
attri_data_frame_index1 = DataFrame(attri_data1, index=['a', 'b', 'c', 'd', 'e'])
print(attri_data_frame_index1)出力結果↓
ID City Birth_year Name
a 100 Tokyo 1990 Hiroshi
b 101 Osaka 1989 Aiko
c 102 Kyoto 1992 Yuki
d 103 Hokkaido 1997 Satoru
e 104 Tokyo 1982 Steve「jupyter notebook」ではこのように綺麗に表示してくれる。
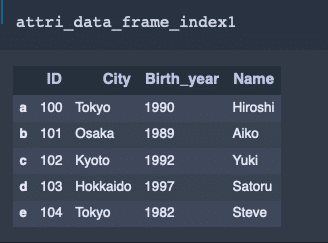
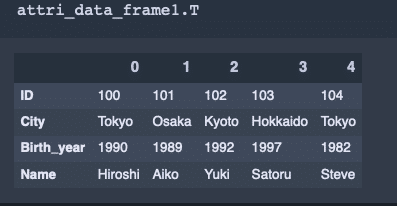
行列操作
行と列を入れ替える。
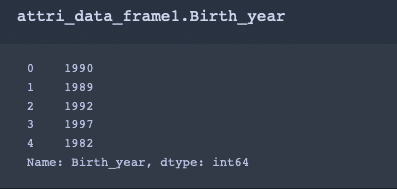
特定の列のみを取り出す。
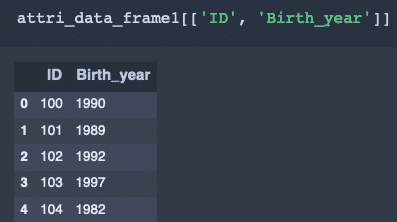
複数の列を取り出す。
フィルター
該当データの抽出。
attri_data_frame1[attri_data_frame1['City'] == 'Tokyo']出力結果↓
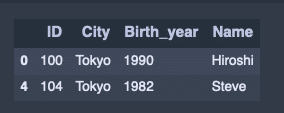
「True or False」で返す。
attri_data_frame1['City'] == 'Tokyo'出力結果↓
0 True
1 False
2 False
3 False
4 True
Name: City, dtype: bool複数の条件。
attri_data_frame1[attri_data_frame1['City'].isin(['Tokyo', 'Osaka'])]出力結果↓

行や列の削除
*元データは変更されない。
attri_data_frame1.drop(['Birth_year'], axis = 1)出力結果↓

データの結合
結合させるデータの用意。
attri_data2 = {'ID': ['100', '101', '102', '105', '107'],
'Math':[50, 43, 33, 76, 98],
'English': [90, 30, 20,50, 30],
'Sex':['F', 'F', 'F', 'M', 'M']}
attri_data_frame2 = DataFrame(attri_data2)
print(attri_data_frame2)出力結果↓
ID Math English Sex
0 100 50 90 F
1 101 43 30 F
2 102 33 20 F
3 105 76 50 M
4 107 98 30 M結合させる。
pd.merge(attri_data_frame1, attri_data_frame2)出力結果↓
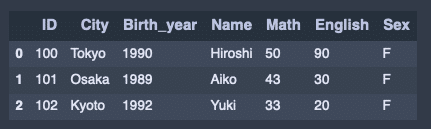
集計。
attri_data_frame2.groupby('Sex')['Math'].mean()出力結果↓
Sex
F 42
M 87
Name: Math, dtype: int64ソート
データの準備。
attri_data2 = {'ID': ['100', '101', '102', '103', '104'],
'City':['Tokyo', 'Osaka', 'Kyoto', 'Hokkaido', 'Tokyo'],
'Birth_year': [1990, 1989, 1992, 1997, 1982],
'Name':['Hiroshi', 'Aiko', 'Yuki', 'Satoru', 'Steve']}
attri_data_frame2 = DataFrame(attri_data2)
attri_data_frame_index2 = DataFrame(attri_data2)
attri_data_frame_index2 = DataFrame(attri_data2,index=['e', 'b', 'a', 'd', 'c'])
attri_data_frame_index2出力結果↓
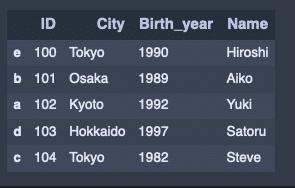
indexによるソート。
attri_data_frame_index2.sort_index()出力結果↓
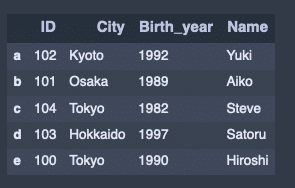
値によるソート。降順。
attri_data_frame_index2.Birth_year.sort_values()出力結果↓
c 1982
b 1989
e 1990
a 1992
d 1997
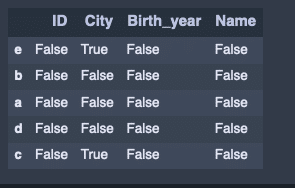
Name: Birth_year, dtype: int64条件に適したデータの比較。
attri_data_frame_index2.isin(['Tokyo'])出力結果↓
欠損値の取り扱い
データの準備。nameを全てnanにする。
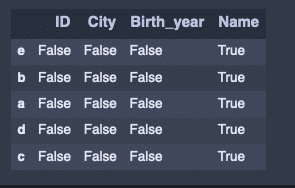
attri_data_frame_index2['Name'] = np.nan
attri_data_frame_index2.isnull()出力結果↓
nullを判定し、合計を求める。
attri_data_frame_index2.isnull().sum()出力結果↓
ID 0
City 0
Birth_year 0
Name 5
dtype: int64階層型インデックス
階層型インデックスとは?
A、複数の軸で階層的にインデックスを設定したもの。
したのようなやつ↓
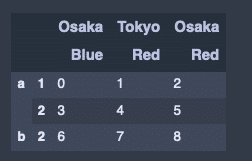
hier_df = DataFrame(
np.arange(9).reshape((3,3)),
index = [
['a', 'a', 'b'],
[1,2,2]
],
columns = [
['Osaka', 'Tokyo', 'Osaka'],
['Blue', 'Red', 'Red']
]
)
hier_df出力結果↓
indexとcolumnsに名前をつける。
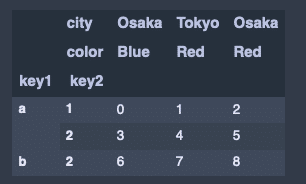
# indexに名前をつける
hier_df.index.names = ['key1', 'key2']
# カラムに名前をつける
hier_df.columns.names = ['city', 'color']
hier_df出力結果↓
カラムの絞り込み。
hier_df['Osaka']出力結果↓
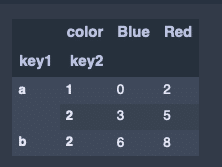
indexを軸にした集計。階層毎の要約的統計量
hier_df.sum(level = 'key2', axis = 0)出力結果↓

列合計
hier_df.sum(level = 'color', axis = 1)出力結果↓
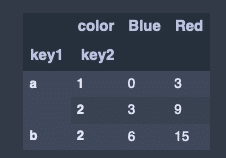
indexの要素の削除。
hier_df.drop(['b'])出力結果↓

データの結合
4つの結合パターン。
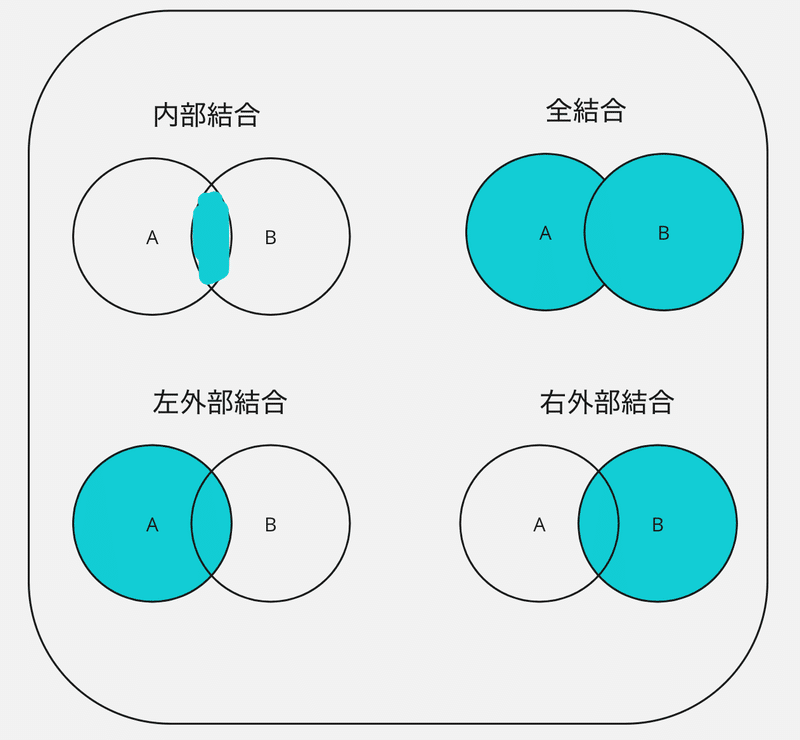
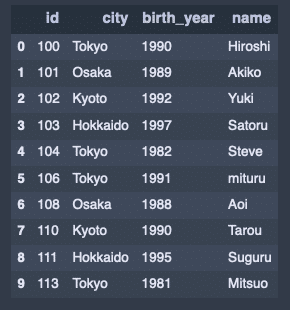
データの準備。
data1 = {
'id': ['100', '101', '102', '103', '104', '106', '108', '110', '111', '113'],
'city': ['Tokyo', 'Osaka', 'Kyoto', 'Hokkaido', 'Tokyo', 'Tokyo', 'Osaka', 'Kyoto', 'Hokkaido', 'Tokyo'],
'birth_year': [1990, 1989, 1992, 1997, 1982, 1991, 1988, 1990, 1995, 1981],
'name': ['Hiroshi', 'Akiko', 'Yuki', 'Satoru', 'Steve', 'mituru', 'Aoi', 'Tarou', 'Suguru', 'Mitsuo']
}
df1 = DataFrame(data1)
df1出力結果↓
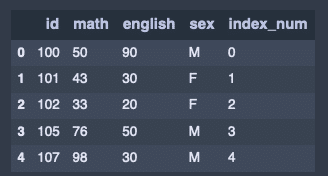
data1 = {
'id': ['100', '101', '102', '105', '107'],
'math': [50, 43, 33, 76, 98],
'english': [90, 30, 20, 50, 30],
'sex': ['M', 'F', 'F', 'M', 'M'],
'index_num': [0, 1, 2, 3, 4]
}
df2 = DataFrame(data1)
df2出力結果↓
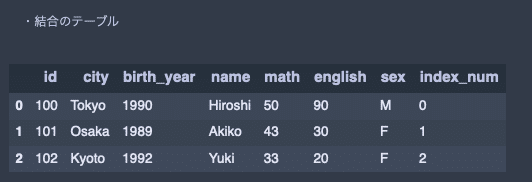
内部結合。
# データのマージ(内部結合。キーは自動的に認識されるが、onで明示的に指定可能)
print('・結合のテーブル')
pd.merge(df1, df2, on = 'id')出力結果↓
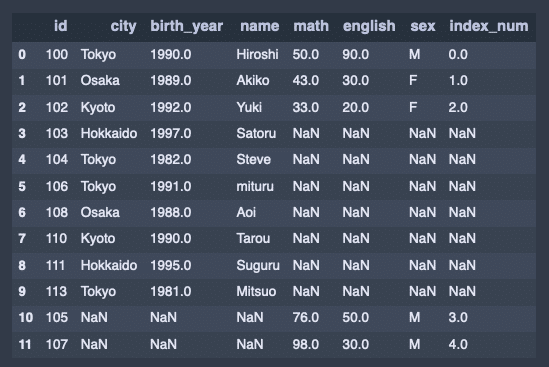
全結合。
# データのマージ(全結合)
pd.merge(df1, df2, how = 'outer')出力結果↓
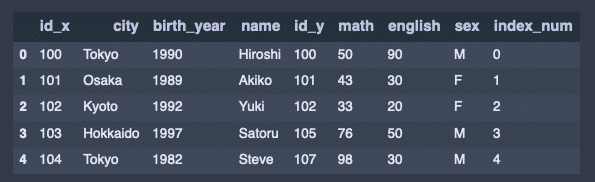
indexによるマージ。
pd.merge(df1, df2, left_index = True, right_on = 'index_num')出力結果↓
左外部結合。
pd.merge(df1, df2, how = 'left')出力結果↓
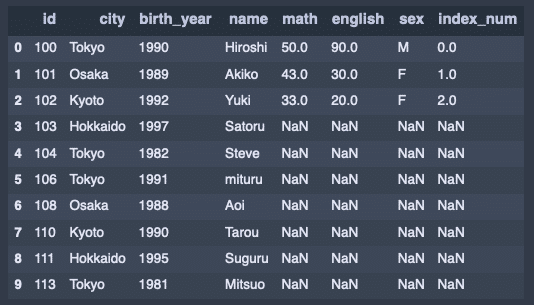
新しいデータの準備。
data3 = {
'id':['117', '118', '119', '120', '125'],
'city':['Chiba', 'kanagawa', 'Tokyo', 'Fukuoka', 'Okinawa'],
'birth_year': [1990, 1989, 1992, 1997, 1982],
'name': ['Suguru', 'Kouichi', 'Satochi', 'Yukie', 'Akari']
}
df3 = DataFrame(data3)
df3出力結果↓
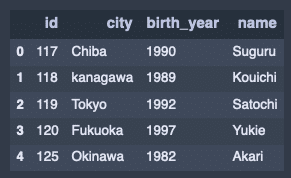
縦結合。
concat_data = pd.concat([df1, df3])
concat_data出力結果↓
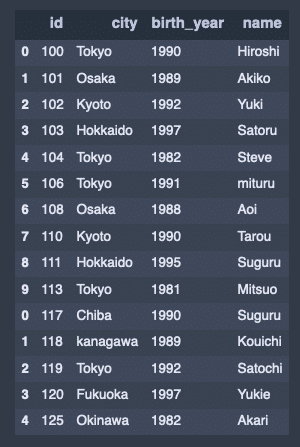
ピボット操作
hier_df = DataFrame(
np.arange(9).reshape((3, 3)),
index = [
['a', 'a', 'b'],
[1, 2, 2]
],
columns = [
['Osaka', 'Tokyo', 'Osaka'],
['Blue', 'Red', 'Red']
]
)
hier_df出力結果↓
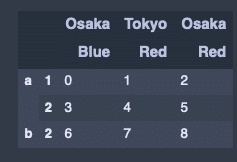
「blue、red」の列を行に変換。
hier_df.stack()出力結果↓
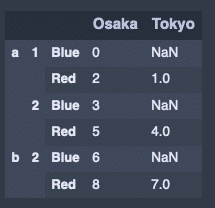
行を列に変換。
hier_df.stack().unstack()出力結果↓
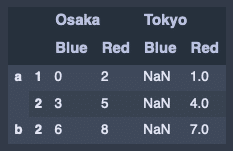
重複があるデータの削除
データの準備。
dupli_data = DataFrame({
'col1': [1, 1, 2, 3, 4, 4, 6, 6],
'col2': ['a', 'b', 'b', 'b', 'c', 'c', 'b', 'b']
})
print('元のデータ')
dupli_data出力結果↓

重複判定。
dupli_data.duplicated()出力結果↓
0 False
1 False
2 False
3 False
4 False
5 True
6 False
7 True
dtype: bool重複削除。
dupli_data.drop_duplicates()出力結果↓

マッピング処理
上のデータの参照となるデータの作成。
city_map = {
'Tokyo': 'Kanto',
'Hokkaido': 'Hokkaido',
'Osaka': 'Kansai',
'Kyoto': 'Kansai'
}
city_map出力結果↓
{'Tokyo': 'Kanto',
'Hokkaido': 'Hokkaido',
'Osaka': 'Kansai',
'Kyoto': 'Kansai'}参照データを結合させる。
df1['region'] = df1['city'].map(city_map)
df1出力結果↓
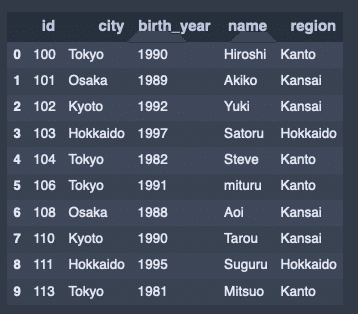
無名関数とmapを組み合わせる。
df1['up_two_num'] = df1['birth_year'].map(lambda x: str(x)[0:3])
df1出力結果↓
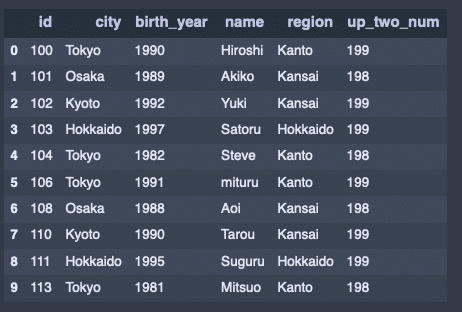
ビン分割
# 分割の粒度
birth_year_bins = [1980, 1985, 1990, 1995, 2000]
# ビン分割の実施
birth_year_cut_data = pd.cut(df1.birth_year, birth_year_bins)
birth_year_cut_data出力結果↓
0 (1985, 1990]
1 (1985, 1990]
2 (1990, 1995]
3 (1995, 2000]
4 (1980, 1985]
5 (1990, 1995]
6 (1985, 1990]
7 (1985, 1990]
8 (1990, 1995]
9 (1980, 1985]
Name: birth_year, dtype: category
Categories (4, interval[int64]): [(1980, 1985] < (1985, 1990] < (1990, 1995] < (1995, 2000]]集計結果。
pd.value_counts(birth_year_cut_data)出力結果↓
(1985, 1990] 4
(1990, 1995] 3
(1980, 1985] 2
(1995, 2000] 1
Name: birth_year, dtype: int64名前をつける。
group_names = ['early1980s', 'late1980s', 'early1990s', 'late1990s']
birth_year_cut_data = pd.cut(df1.birth_year, birth_year_bins, labels = group_names)
pd.value_counts(birth_year_cut_data)出力結果↓
late1980s 4
early1990s 3
early1980s 2
late1990s 1
Name: birth_year, dtype: int64分割数の指定。2つにする。
pd.cut(df1.birth_year, 2)出力結果↓
0 (1989.0, 1997.0]
1 (1980.984, 1989.0]
2 (1989.0, 1997.0]
3 (1989.0, 1997.0]
4 (1980.984, 1989.0]
5 (1989.0, 1997.0]
6 (1980.984, 1989.0]
7 (1989.0, 1997.0]
8 (1989.0, 1997.0]
9 (1980.984, 1989.0]
Name: birth_year, dtype: category
Categories (2, interval[float64]): [(1980.984, 1989.0] < (1989.0, 1997.0]]pd.value_counts(pd.qcut(df1.birth_year, 2))出力結果↓
(1980.999, 1990.0] 6
(1990.0, 1997.0] 4
Name: birth_year, dtype: int64データの集約とグループ演算
df1出力結果↓
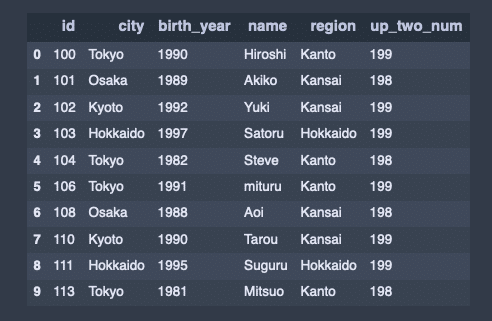
サイズ情報
df1.groupby('city').size()出力結果↓
city
Hokkaido 2
Kyoto 2
Osaka 2
Tokyo 4
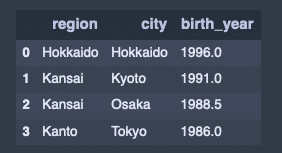
dtype: int64cityを軸に、birth_yearの平均値を求める。
df1.groupby('city')['birth_year'].mean()出力結果↓
city
Hokkaido 1996.0
Kyoto 1991.0
Osaka 1988.5
Tokyo 1986.0
Name: birth_year, dtype: float64df1.groupby(['region', 'city'])['birth_year'].mean()出力結果↓
region city
Hokkaido Hokkaido 1996.0
Kansai Kyoto 1991.0
Osaka 1988.5
Kanto Tokyo 1986.0
Name: birth_year, dtype: float64df1.groupby(['region', 'city'], as_index = False)['birth_year'].mean()出力結果↓
for group, subdf in df1.groupby('region'):
print('=========================================')
print('Region Name:{0}'.format(group))
print(subdf)出力結果↓
=========================================
Region Name:Hokkaido
id city birth_year name region up_two_num
3 103 Hokkaido 1997 Satoru Hokkaido 199
8 111 Hokkaido 1995 Suguru Hokkaido 199
=========================================
Region Name:Kansai
id city birth_year name region up_two_num
1 101 Osaka 1989 Akiko Kansai 198
2 102 Kyoto 1992 Yuki Kansai 199
6 108 Osaka 1988 Aoi Kansai 198
7 110 Kyoto 1990 Tarou Kansai 199
=========================================
Region Name:Kanto
id city birth_year name region up_two_num
0 100 Tokyo 1990 Hiroshi Kanto 199
4 104 Tokyo 1982 Steve Kanto 198
5 106 Tokyo 1991 mituru Kanto 199
9 113 Tokyo 1981 Mitsuo Kanto 198
欠損データの扱い方
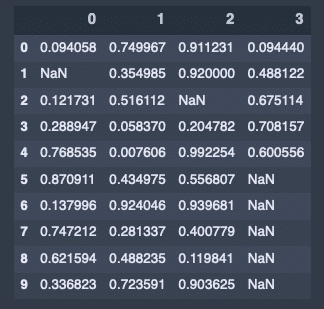
データの準備
import numpy as np
from numpy import nan as NA
import pandas as pd
df = pd.DataFrame(np.random.rand(10, 4))
# NAにする
df.iloc[1, 0] = NA
df.iloc[2:3, 2] = NA
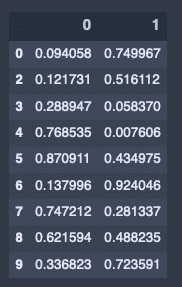
df.iloc[5:, 3] = NAdf出力結果↓
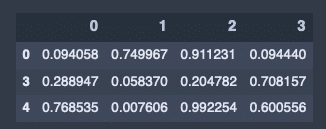
リストワイズ削除(Nan)がある行を全て取り除く。
# リストワイズ削除
df.dropna()出力結果↓
ペアワイズ削除。利用可能なデータのみを用いる。
# ペアワイズ
df[[0, 1]].dropna()出力結果↓
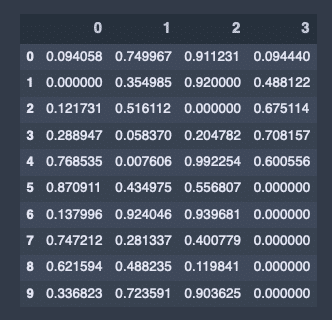
Fillnaで埋める。Nanを0にする。
# fillnaで埋める
df.fillna(0)出力結果↓
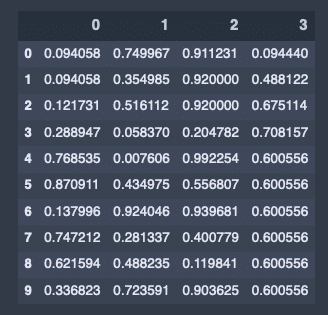
前の値で埋める。
# 前の値で埋める
df.fillna(method = 'ffill')出力結果↓
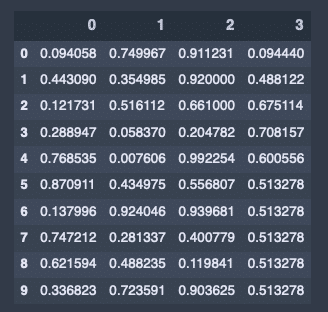
平均代入法。Nanを平均値で埋める。
# 平均値で埋める
df.fillna(df.mean())出力結果↓
時系列データの取り扱い。
データの準備。
# 時系列データの処理と変換
import pandas_datareader.data as pdr
start_date = '2001/1/2'
end_date = '2016/12/30'
fx_jpusdata = pdr.DataReader('DEXJPUS', 'fred', start_date, end_date)fx_jpusdata.head()出力結果↓
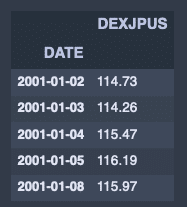
特定の年月のデータを参照する。
fx_jpusdata['2016-04']出力結果↓
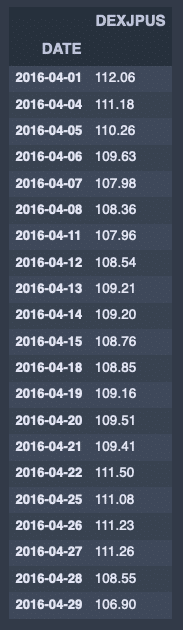
fx_jpusdata.resample('M').last().head()出力結果↓
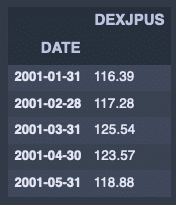
欠損がある場合。
fx_jpusdata.resample('D').last().head()出力結果↓
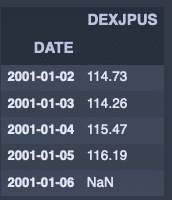
fx_jpusdata.resample('D').ffill().head()出力結果↓
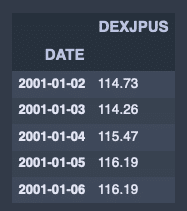
# データをずらして比率を計算する
fx_jpusdata.shift(1).head()出力結果↓
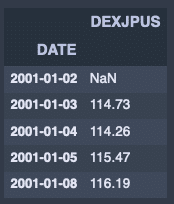
fx_jpusdata_ratio = fx_jpusdata / fx_jpusdata.shift(1)
fx_jpusdata_ratio.head()出力結果↓
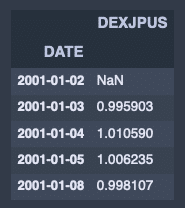
平均移動。
fx_jpusdata.head()出力結果↓
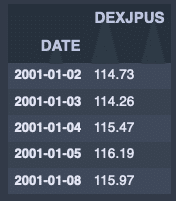
fx_jpusdata.rolling(3).mean().head()出力結果↓
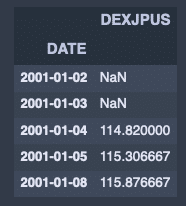
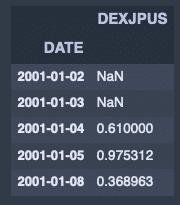
fx_jpusdata.rolling(3).std().head()出力結果↓
この記事が気に入ったらサポートをしてみませんか?