Fireworks.aiでVercel AI SDKを使う

Fireworks.ai という日本ではまだあまり知られていないサービスを NextJSで使ってみたいと思います。加えてVercel AI SDKは、Fireworks.aiのAPIやモデルを簡単に利用できるユーティリティを提供しています。公式ガイドに従って、このユーティリティを使用してチャットボットとテキスト補完アプリを作成する方法を試してみます。
Fireworks.aiのREST APIはOpenAIのものと互換性があるので、OpenAIのJavaScript SDKを使ってリクエストを行います。これにより、Fireworks.aiのモデルを移行したり試したりするのがとても簡単になります。
Llama 2 Chatbot を作ってみる
Next.jsアプリの作成
Next.jsアプリケーションを作成し、Vercel AI SDKとOpenAI APIクライアントであるaiとopenaiをそれぞれインストールします。FireworksのREST APIはOpenAIのものと互換性があるので、OpenAIのJavaScript SDKを使ってリクエストを行います。
Vercelで管理が可能な適当なプライベートリポジトリをGitHubに作って作業開始します。
pnpmのインストール
パッケージマネージャーは npm とか yarn とか pnpm が選べますが、ここでは公式が pnpm なので pnpm で試していきます。
Windows の場合、公式ではNode.js がインストールされていない場合、PowerShell環境を揃えていないひとは「npm install -g pnpm」でOK。PowerShellの場合は iwr (≒wget)を使うそうです。
「iwr https://get.pnpm.io/install.ps1 -useb | iex」
権限エラーが出る人は
PowerShell Get-ExecutionPolicyこの辺をご参照ください
https://manumaruscript.com/vscode-activate-error/
セキュリティポリシーを変更して実行すれば動きますがターミナルを立ち上げる度にこのポリシー変更を適用しなければなりません。都度オプションをつけて実行するのは面倒なので、
VSCodeの setting.json を 「Ctrl + ,」または、メニューバーから基本設定 > 設定 で設定画面を開き、右上の📄アイコンで開いたら以下のように記述しちゃいましょう。
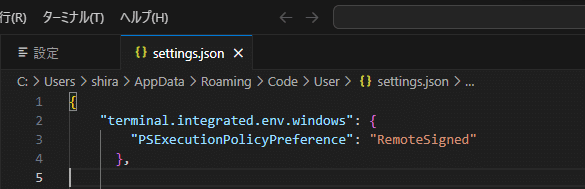
{
"terminal.integrated.env.windows": {
"PSExecutionPolicyPreference": "RemoteSigned"
},
...以下設定が続く...pnpm dlx create-next-app my-ai-app
このコマンドで新しいプロジェクトを作成したいところですが、my-ai-appという名前はやめたいのと、リポジトリ名やnpmの命名規則があるので、小文字で「vercel-llama2」という空っぽのリポジトリがあるとします。README.mdを削除しないと作成できないので削除して、以下のようにコマンド投入します。
rm README.md
cd ..
pnpm dlx create-next-app ./vercel-llama2
cd vercel-llama2
pnpm install ai openai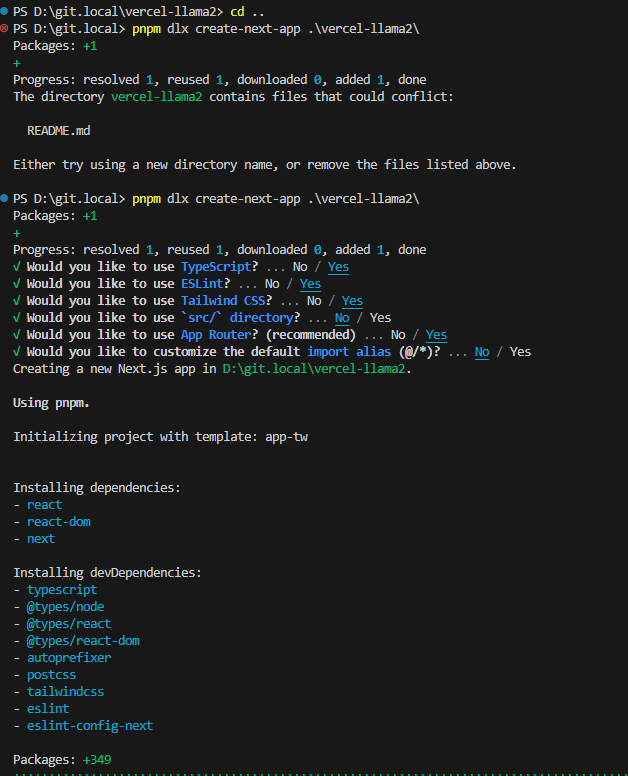
ここで pnpm dev として初期のサイトが http://localhost:3001/ に生成されていることを確認しましょう。
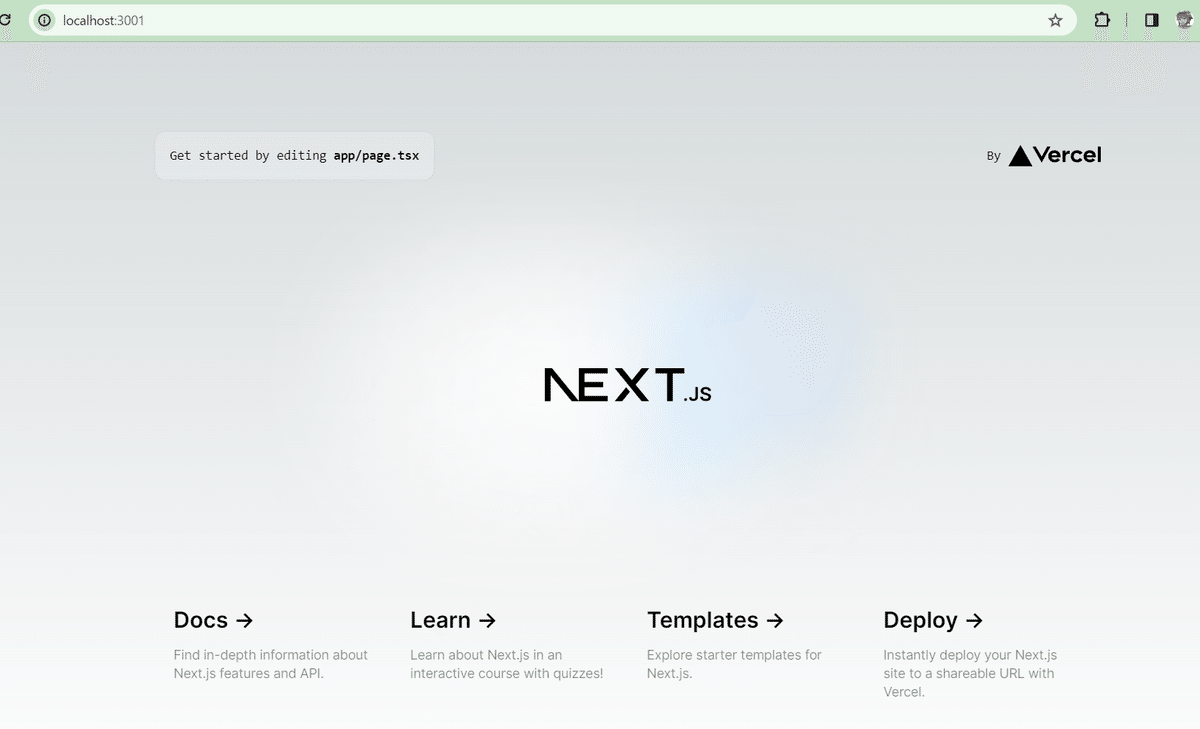
コンソール上では ctrl+C でpnpm devを抜けることができますが、このまま続きを実装していきましょう。保存するたびに更新されます。
FireworksのAPIキーを.envに追加
プロジェクトルートに .env ファイルを作成し、Fireworks API Key を追加します。
https://app.fireworks.ai/api-keys
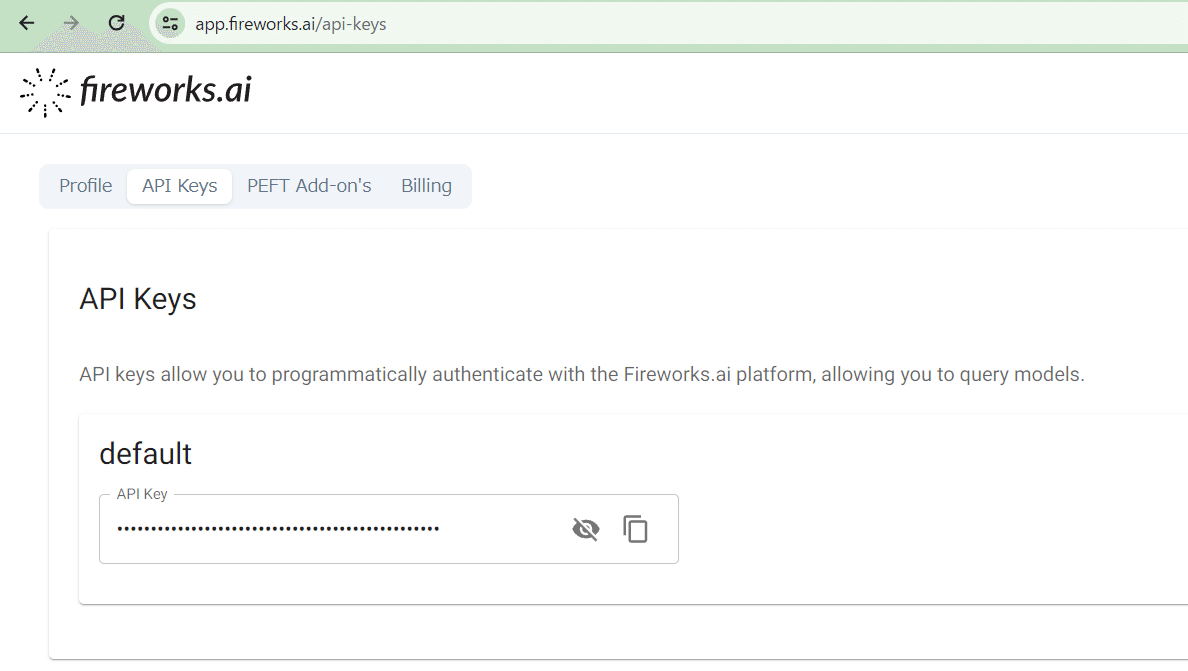
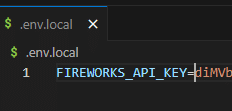
公式では .env ファイルを作れと言いますが、さすがにこれをgithubで管理するのはよろしく無いので .env.local ファイルを作成して記載
FIREWORKS_API_KEY=xxxxxxxxx
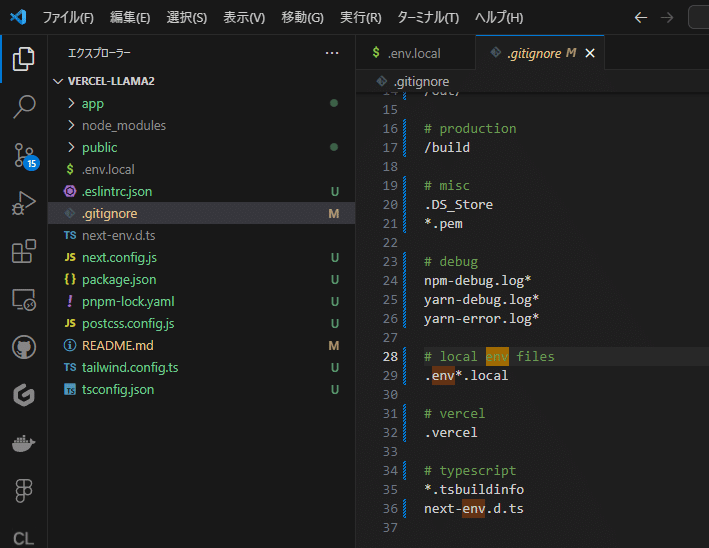
.gitignoreにも .env*.local が記載されていることを確認しましょう
ルートハンドラの作成
Next.jsのRoute Handlerを作成します。このRoute Handlerは、Edge Runtimeを使用してFireworks経由でチャット完了を生成し、Next.jsにストリームバックします。
この例では、app/api/chat/route.tsに typescriptファイルを作って(フォルダ作成を2回、新規ファイル route.ts)
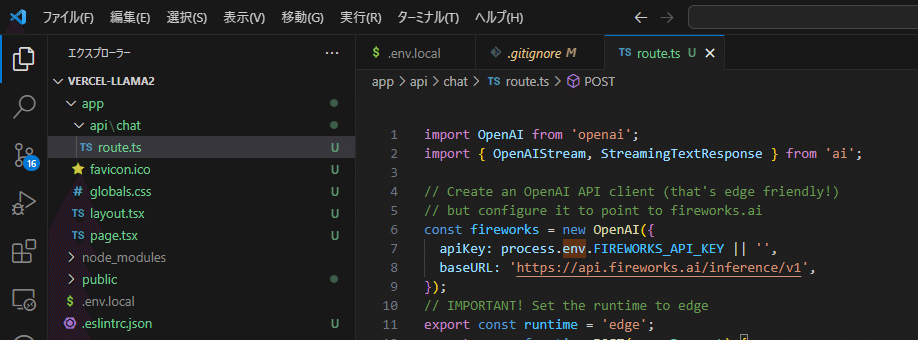
以下のコードでルートハンドラを作成し、文字列のメッセージ配列を含むPOSTリクエストを受け取ります。
app/api/chat/route.ts
import OpenAI from 'openai';
import { OpenAIStream, StreamingTextResponse } from 'ai';
// Create an OpenAI API client (that's edge friendly!)
// but configure it to point to fireworks.ai
// OpenAI API クライアントを作成します。ただし、fireworks.ai を指すように設定します。
const fireworks = new OpenAI({
apiKey: process.env.FIREWORKS_API_KEY || '',
baseURL: 'https://api.fireworks.ai/inference/v1',
});
// IMPORTANT! Set the runtime to edge
// 重要!ランタイムをエッジに設定します。
export const runtime = 'edge';
export async function POST(req: Request) {
// Extract the `messages` from the body of the request
const { messages } = await req.json();
// Ask Fireworks for a streaming chat completion using Llama 2 70b model
// @see https://app.fireworks.ai/models/fireworks/llama-v2-70b-chat
// Llama 2 70bモデルを使用したストリーミングチャット補完をFireworksに依頼します
const response = await fireworks.chat.completions.create({
model: 'accounts/fireworks/models/llama-v2-70b-chat',
stream: true,
max_tokens: 1000,
messages,
});
// Convert the response into a friendly text-stream.
// レスポンスをフレンドリーなテキストストリームに変換
const stream = OpenAIStream(response);
// Respond with the stream
// ストリームで応答
return new StreamingTextResponse(stream);
}Vercel AI SDKは、上記をシームレスにするために2つのユーティリティヘルパーを提供しています。まず、Fireworksから受け取ったストリーミング応答をOpenAIStreamに渡します。このメソッドは、レスポンス内のテキストトークンをデコード/抽出し、単純な消費のために適切に再エンコードします。そして、その新しいストリームを StreamingTextResponse に直接渡すことができます。これは通常の Node/Edge Runtime Response クラスを拡張したもう一つのユーティリティクラスで、おそらく必要なデフォルトのヘッダを備えています (ヒント: 'Content-Type': 'text/plain; charset=utf-8' は既に設定されています)。
これでは訳がわかりませんのでちょっと解説すると、
ai/reactのなかにChat()の実装があるようです。
UIを繋ぐ
ユーザーからプロンプトを収集し、完了をストリームで戻すために使用するフォームを持つ Client コンポーネントを作成します。
app/page.tsx
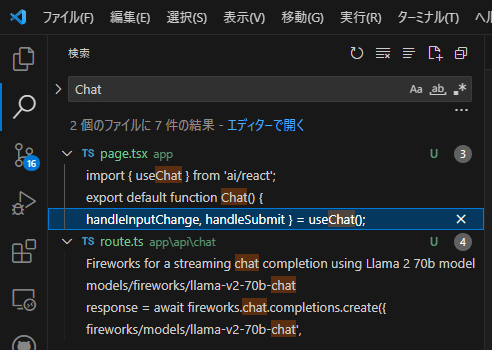
'use client';
import { useChat } from 'ai/react';
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat();
return (
<div className="mx-auto w-full max-w-md py-24 flex flex-col stretch">
{messages.map(m => (
<div key={m.id}>
{m.role === 'user' ? 'User: ' : 'AI: '}
{m.content}
</div>
))}
<form onSubmit={handleSubmit}>
<label>
何か言ってください:
<input
className="fixed w-full max-w-md bottom-0 border border-gray-300 rounded mb-8 shadow-xl p-2"
value={input}
onChange={handleInputChange}
/>
</label>
<button type="submit">Send</button>
</form>
</div>
);
}pnpm devしてあればこんな画面になるはずです。
下のプロンプトに適当なテキストを突っ込んでみましょう。
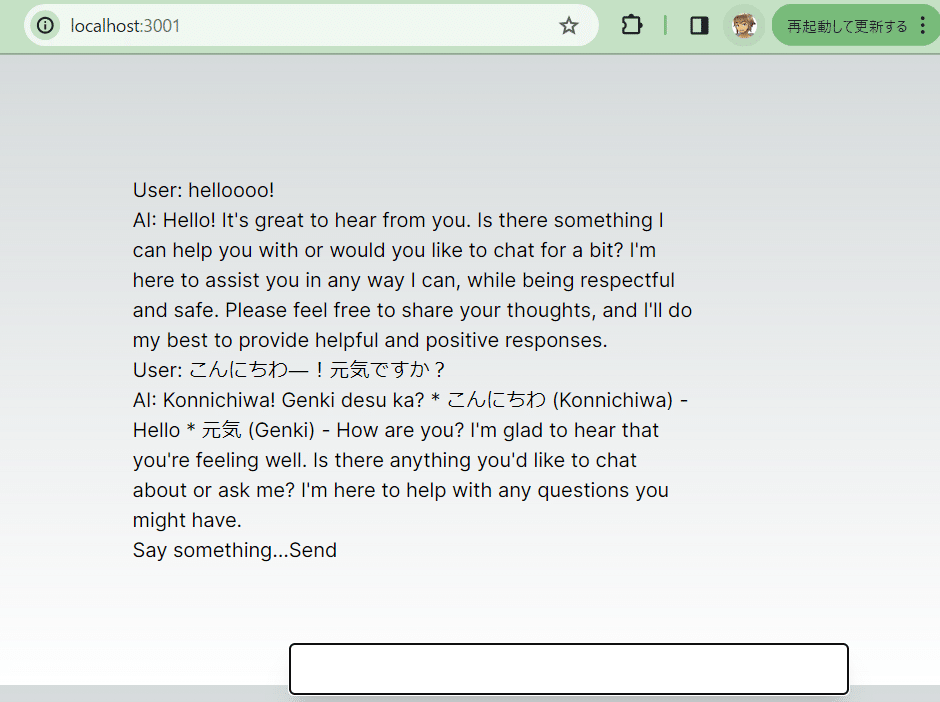
デフォルトでは、useChatフックは上記で作成したPOSTルートハンドラを使用します(デフォルトは/api/chatです)。useChat({ api: '...'}) に api prop を渡すことで、これをオーバーライドできます。
コンピレーションAPIの使用
ChatGPTのAPIなどでよく使われるテキストコンピレーション(Text Completion、テキストの補完/推論/生成)を実装しましょう。
上記のチャットボットの例と同様に、Next.jsのRoute Handlerを作成して、Fireworks経由でテキスト補完を生成し、Next.jsにストリームバックします。プロンプト文字列を含むPOSTリクエストを受け付けます:
app/api/completion/route.ts
import OpenAI from 'openai';
import { OpenAIStream, StreamingTextResponse } from 'ai';
// Create an OpenAI API client (that's edge friendly!)
// but configure it to point to fireworks.ai
const fireworks = new OpenAI({
apiKey: process.env.FIREWORKS_API_KEY || '',
baseURL: 'https://api.fireworks.ai/inference/v1',
});
// IMPORTANT! Set the runtime to edge
export const runtime = 'edge';
export async function POST(req: Request) {
// Extract the `prompt` from the body of the request
const { prompt } = await req.json();
// Ask Fireworks for a streaming chat completion using Llama 2 70b model
// @see https://app.fireworks.ai/models/fireworks/llama-v2-70b-chat
const response = await fireworks.completions.create({
model: 'accounts/fireworks/models/llama-v2-70b-chat',
stream: true,
max_tokens: 1000,
prompt,
});
// Convert the response into a friendly text-stream.
const stream = OpenAIStream(response);
// Respond with the stream
return new StreamingTextResponse(stream);
}
UIを繋ぐ
useCompletion フックを使うと、UI の配線が簡単になります。デフォルトでは、useCompletion フックは上で作成した POST Route Handler を使います (デフォルトは /api/completion です)。useCompletion({ api: '...'}) に api prop を渡すことで、これをオーバーライドできます。
app/page.tsx を上書き修正します
import OpenAI from 'openai';
import { OpenAIStream, StreamingTextResponse } from 'ai';
// Create an OpenAI API client (that's edge friendly!)
// but configure it to point to fireworks.ai
const fireworks = new OpenAI({
apiKey: process.env.FIREWORKS_API_KEY || '',
baseURL: 'https://api.fireworks.ai/inference/v1',
});
// IMPORTANT! Set the runtime to edge
export const runtime = 'edge';
export async function POST(req: Request) {
// Extract the `prompt` from the body of the request
const { prompt } = await req.json();
// Ask Fireworks for a streaming chat completion using Llama 2 70b model
// @see https://app.fireworks.ai/models/fireworks/llama-v2-70b-chat
const response = await fireworks.completions.create({
model: 'accounts/fireworks/models/llama-v2-70b-chat',
stream: true,
max_tokens: 1000,
prompt,
});
// Convert the response into a friendly text-stream.
const stream = OpenAIStream(response);
// Respond with the stream
return new StreamingTextResponse(stream);
}「吾輩は猫である…名前は…」と訊いてみました。

完了後のデータベースへの保存
生成結果をストリーミングで返したあとでデータベースに保存したい、というのはよくあることです。OpenAIStream アダプタは、オプションのコールバックをいくつか受け取ることができます。
app/api/completion/route.ts
import OpenAI from 'openai';
import { OpenAIStream, StreamingTextResponse } from 'ai';
// OpenAI API クライアントを作成 ただし、fireworks.ai を指すように設定します。
// Create an OpenAI API client (that's edge friendly!)
// but configure it to point to fireworks.ai
const fireworks = new OpenAI({
apiKey: process.env.FIREWORKS_API_KEY || '',
baseURL: 'https://api.fireworks.ai/inference/v1',
});
// IMPORTANT! Set the runtime to edge
export const runtime = 'edge';
export async function POST(req: Request) {
// Extract the `prompt` from the body of the request
const { prompt } = await req.json();
// Ask Fireworks for a streaming chat completion using Llama 2 70b model
// @see https://app.fireworks.ai/models/fireworks/llama-v2-70b-chat
const response = await fireworks.completions.create({
model: 'accounts/fireworks/models/llama-v2-70b-chat',
stream: true,
max_tokens: 1000,
prompt,
});
// Convert the response into a friendly text-stream
const stream = OpenAIStream(response, {
onStart: async () => {
// This callback is called when the stream starts
// You can use this to save the prompt to your database
// but this function is not existing...
await savePromptToDatabase(prompt);
},
onToken: async (token: string) => {
// This callback is called for each token in the stream
// You can use this to debug the stream or save the tokens to your database
console.log(token);
},
onCompletion: async (completion: string) => {
// This callback is called when the stream completes
// You can use this to save the final completion to your database
// but this function is not existing...
await saveCompletionToDatabase(completion);
},
});
// Respond with the stream
return new StreamingTextResponse(stream);
}
…ということですが、実装がないようです。
VercelのDiscussionsで訊いておこう…
今度はこれをサービスにしていきます。
続きはAICU社のほうで書きます!
この記事が気に入ったらサポートをしてみませんか?