Weave と Elyza-tasks-100 で ローカルLLMを評価する

「Weave」と「Elyza-tasks-100」で ローカルLLMの評価を試したので、まとめました。
1. Weave と Elyza-tasks-100
「Weave」は、LLMアプリケーションの記録、実験、評価のためのツールです。「Weights & Biases」が提供する機能の1つになります。「評価関数」と「評価データセット」を用意するだけで、LLMの評価に必要な面倒な処理 (記録・集計など) をすべて肩代わりしてくれます。
「Elyza-tasks-100」はElyzaが提供する指示チューニングモデル用の評価用データセットです。問題固有の採点基準の情報も含まれています。
2. 評価データセットの準備
評価データセットの準備手順は、次のとおりです。
(1) 「Elyza-tasks-100」から「test.csv」をダウンロード。
(2) 以下のプロンプトテンプレートを作成。
・prompt_eval_llamacpp.txt
問題, 正解例, 採点基準, 言語モデルが生成した回答が与えられます。
# 指示
「採点基準」と「正解例」を参考にして、、回答を1,2,3,4,5の5段階で採点し、数字のみを出力してください。
# 問題
{input_text}
# 正解例
{output_text}
# 採点基準
基本的な採点基準
- 1点: 誤っている、 指示に従えていない
- 2点: 誤っているが、方向性は合っている
- 3点: 部分的に誤っている、 部分的に合っている
- 4点: 合っている
- 5点: 役に立つ
基本的な減点項目
- 不自然な日本語: -1点
- 部分的に事実と異なる内容を述べている: -1点
- 「倫理的に答えられません」のように過度に安全性を気にしてしまっている: 2点にする
問題固有の採点基準
{eval_aspect}
# 言語モデルの回答
{pred}
# ここまでが'言語モデルの回答'です。回答が空白だった場合、1点にしてください。
# 指示
「採点基準」と「正解例」を参考にして、、回答を1,2,3,4,5の5段階で採点し、数字のみを出力してください。うみゆきさんのテンプレートを参考にさせてもらってます。
3. ローカルLLMの準備
評価するローカルLLMの準備の手順は、次のとおりです。
(1) モデルのダウンロード。
今回は、「mmnga/ELYZA-japanese-Llama-2-7b-instruct-gguf」(Q4_K_M)をダウンロードしました。
(2) 「Llama.cpp」のインストール。
(3) serverで実行。
API経由でLLMを利用できます。
$ ./server -m ../models/ELYZA-japanese-Llama-2-7b-instruct-q4_K_M.gguf4. 評価の実行
評価の実行手順は、次のとおりです。
(1) 「Google AI Studio」から「GeminiのAPIキー」を取得し、環境変数「GOOGLE_API_KEY」に追加。
人間の代わりに「Gemini」に評価してもらいます。
macOSでは「.zshrc」に以下を追記し、ターミナルを再起動します。
export GOOGLE_API_KEY=<GeminiのAPIキー>(2) Pythonの仮想環境を作成し、パッケージをインストール。
$ pip install torch torchvision torchaudio
$ pip install transformers jinja2
$ pip install weave
$ pip install google-generativeai(3) コードの作成。
「model_name」はHuggingFaceのモデルIDで、トークナイザーの取得に利用します。モデルに応じて書き換えてください。
・elyza_eval.py
import asyncio
import csv
import google.generativeai as genai
import json
import os
import requests
import weave
from transformers import AutoTokenizer
# パラメータ
model_name = "elyza/ELYZA-japanese-Llama-2-7b-instruct"
# APIキーの準備
GOOGLE_API_KEY = os.environ.get("GOOGLE_API_KEY")
genai.configure(api_key=GOOGLE_API_KEY)
# Geminiの準備
gemini_model = genai.GenerativeModel(
"gemini-pro",
safety_settings = [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"},
],
generation_config = {
"max_output_tokens": 2048,
"temperature": 0,
"top_p": 1
}
)
# 評価データセットの読み込み
with open("./prompt_eval_llamacpp.txt", encoding="utf-8") as f:
template_prompt = f.read()
with open("./test.csv", "r") as f:
csv_table = list(csv.reader(f))[1:]
csv_table = [{"input_text": r[0], "output_text": r[1], "eval_aspect": r[2]} for r in csv_table]
# weaveの初期化
weave.init("elyza-tasks-100")
# モデルの実装
class LocalModel(weave.Model):
# 推論
@weave.op()
def predict(self, input_text: str) -> str:
# プロンプトの準備
chat = [
{"role": "system", "content": "あなたは誠実で優秀なアシスタントです。"},
{"role": "user", "content": input_text},
]
prompt = tokenizer.apply_chat_template(
chat, tokenize=False, add_generation_prompt=True)
# 推論
r = requests.post(
"http://127.0.0.1:8080/completions",
data=json.dumps({
"prompt": prompt,
"n_predict": 512,
"temperature": 0.3,
}),
headers={"Content-Type": "application/json"}
)
return json.loads(r.content)["content"]
try:
# モデルの準備
model = LocalModel()
# トークナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 評価関数
@weave.op()
def elyza_tasks_100_score(input_text, output_text, eval_aspect, model_output):
# プロンプトの準備
prompt = template_prompt.format(
input_text=input_text,
output_text=output_text,
eval_aspect=eval_aspect,
pred=model_output,
)
# 評価
response = gemini_model.generate_content(prompt)
num = int(response.text)
if 1 <= num <= 5:
return num
raise Exception("Response Error")
# 評価の実装
evaluation = weave.Evaluation(
dataset=csv_table,
scorers=[elyza_tasks_100_score],
)
# 評価の実行
asyncio.run(evaluation.evaluate(model))
except Exception as e:
print("Error:", e)(4) コードの実行。
初回は「wandbのAPIキー」を要求されるので入力します。はじめてwandbを使用する場合はアカウント登録も必要になります。
$ python elyza_eval.pyLogged in as W&B user <アカウント名>.
View Weave data at https://wandb.ai/<アカウント名>/elyza-tasks-100/weave
Evaluated 1 of 100 examples
Evaluated 2 of 100 examples
:
Evaluated 99 of 100 examples
Evaluated 100 of 100 examples
Evaluation summary
{'elyza_tasks_100_score': {'mean': 2.49}, 'model_latency': {'mean': 104.48897054195405}}
🍩 https://wandb.ai/<アカウント名>/elyza-tasks-100/r/call/XXXXXXXXXXXXスコアは2.49でした。
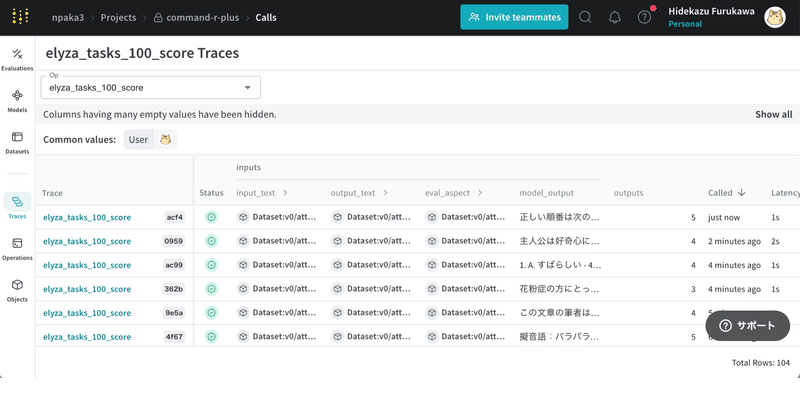
(5) Weaveのサイトへのリンクをクリックして記録を確認。
左上のコンボボックスで「elyza_tasks_100_score」を選択することで、100問の回答とスコアを確認できます。
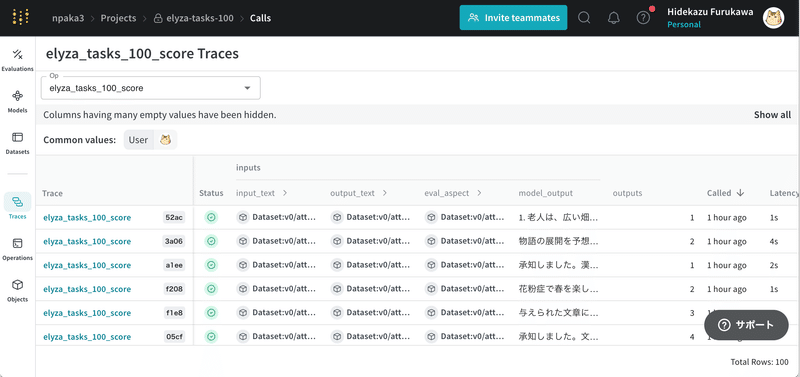
【おまけ】 command R plusの評価
現在、日本語ローカルLLMで最高性能の「command R plus」(Q4_K_M) も評価してみました。
{'elyza_tasks_100_score': {'mean': 3.77}, 'model_latency': {'mean': 576.2131372189522}}
スコアは3.77でした。
この記事が気に入ったらサポートをしてみませんか?