
Stable Baselines 3 入門 (1) - 強化学習アルゴリズム実装セット

強化学習アルゴリズム実装セット「Stable Baselines 3」の基本的な使い方をまとめました。
・Python 3.8.12
・Stable Baselines 1.6.0
・gym 0.21.0
1. Stable Baselines 3
「Stable Baselines 3」は、OpenAIが提供する強化学習アルゴリズム実装セット「OpenAI Baselines」の改良版です。
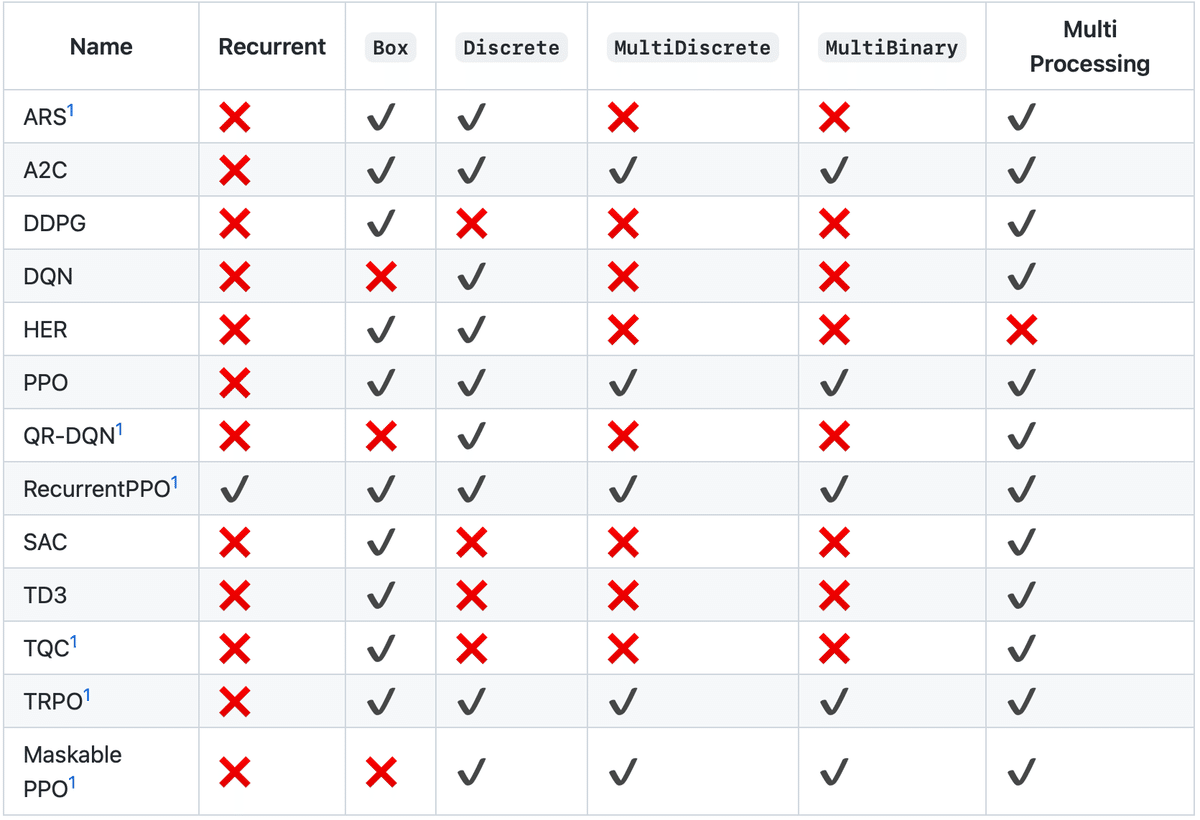
提供されている強化学習アルゴリズムは、次のとおりです。
2. OpenAI Gym
「OpenAI Gym」は、OpenAIが提供するシングルエージェント強化学習環境セットです。
同じ学習コードで異なる学習環境を簡単に試せるように、学習環境の標準的なAPIも提供します。
「OpenAI Gym」の学習環境の主なAPIは、次のとおりです。
・reset() : 学習環境のリセット
・step() : 学習環境の1ステップ実行
・render() : 学習環境の描画
・close() : 学習環境の解放
・seed() : 乱数シードの指定
・observation_space : 状態空間
・action_space : 行動空間
3. Stable Baselines 3とOpenAI Gymのインストール
「Stable Baselines 3」と「OpenAI Gym」のインストール手順は、次のとおりです。
(1) Pythonの仮想環境を準備。
「Python 3.7以降」をインストールします。
(2) 「Stable Baselines 3」のインストール。
$ pip install 'stable-baselines3[extra]'(3) 「OpenAI Gym」のインストール。
「OpenAI Gym」は学習対象となる学習環境を提供するパッケージです。今回は「Cart Pole」を使うので「Classic Control」をインストールします。
$ pip install 'gym[classic_control]'
4. Cart Poleの学習
「Cart Pole」はカードを左右移動させて、棒を倒さないようにバランスをとるゲームです。
(1) 「Cart Pole」の学習および推論を行うコードの作成。
・train_cartpole.py
import gym
from stable_baselines3 import PPO
# 学習環境の準備
env = gym.make('CartPole-v1')
# モデルの準備
model = PPO('MlpPolicy', env, verbose=1)
# 学習の実行
model.learn(total_timesteps=128000)
# 推論の実行
state = env.reset()
while True:
# 学習環境の描画
env.render()
# モデルの推論
action, _ = model.predict(state, deterministic=True)
# 1ステップ実行
state, rewards, done, info = env.step(action)
# エピソード完了
if done:
break
# 学習環境の解放
env.close()
(2) 「Cart Pole」の学習および推論を行うコードの実行。
$ python train_cartpole.py学習中は、学習状況のログが出力されます。
Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
---------------------------------
| rollout/ | |
| ep_len_mean | 22.2 |
| ep_rew_mean | 22.2 |
| time/ | |
| fps | 2573 |
| iterations | 1 |
| time_elapsed | 0 |
| total_timesteps | 2048 |
---------------------------------
-----------------------------------------
| rollout/ | |
| ep_len_mean | 27.8 |
| ep_rew_mean | 27.8 |
| time/ | |
| fps | 1881 |
| iterations | 2 |
| time_elapsed | 2 |
| total_timesteps | 4096 |
| train/ | |
| approx_kl | 0.008973258 |
| clip_fraction | 0.112 |
| clip_range | 0.2 |
| entropy_loss | -0.686 |
| explained_variance | 0.00273 |
| learning_rate | 0.0003 |
| loss | 9.83 |
| n_updates | 10 |
| policy_gradient_loss | -0.0178 |
| value_loss | 55.3 |
-----------------------------------------
:
-----------------------------------------
| rollout/ | |
| ep_len_mean | 500 |
| ep_rew_mean | 500 |
| time/ | |
| fps | 1418 |
| iterations | 63 |
| time_elapsed | 90 |
| total_timesteps | 129024 |
| train/ | |
| approx_kl | 0.001315634 |
| clip_fraction | 0.0208 |
| clip_range | 0.2 |
| entropy_loss | -0.243 |
| explained_variance | 0.338 |
| learning_rate | 0.0003 |
| loss | 0.00326 |
| n_updates | 620 |
| policy_gradient_loss | 0.000429 |
| value_loss | 7.69e-07 |
-----------------------------------------学習後は、学習済みモデルで推論が実行され、画面表示で動作確認できます。
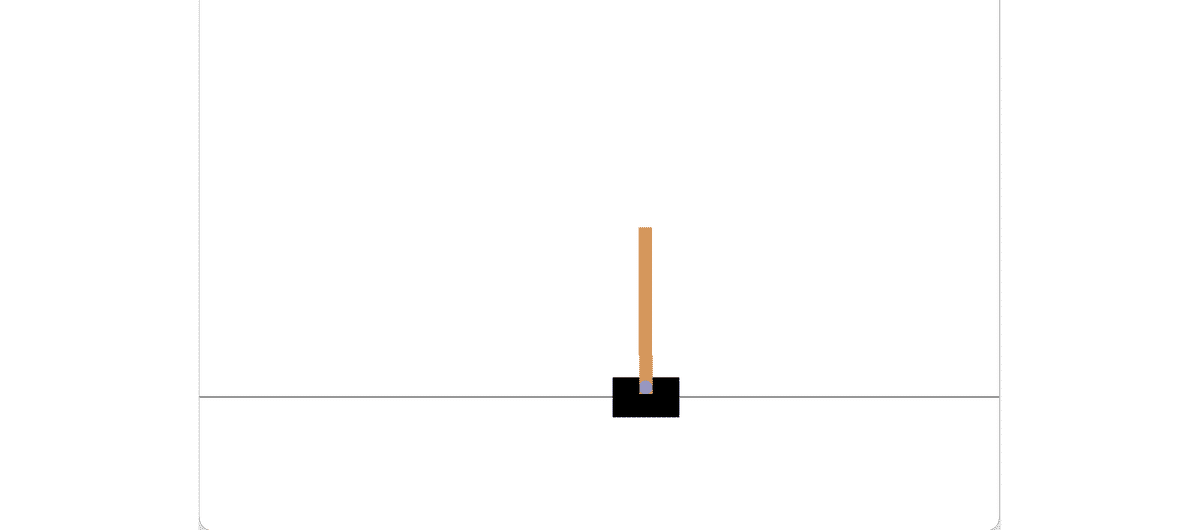
【おまけ】 学習環境一覧の確認
以下のコードで、利用可能な学習環境一覧を取得できます。
・env_list.py
from gym import envs
for spec in envs.registry.all():
print(spec.id)実行結果は、次のとおりです。
$ python env_list.pyALE/Tetris-v5
ALE/Tetris-ram-v5
ALE/Asterix-v5
:
Humanoid-v4
HumanoidStandup-v2
HumanoidStandup-v4【おまけ】 行動空間と状態空間の確認
以下のコードで、学習環境の行動空間と状態空間を確認できます。
・check_space.py
import gym
from gym.spaces import *
# 環境ID
ENV_ID = 'CartPole-v1'
# 空間の出力
def print_spaces(label, space):
# 空間の出力
print(label, space)
# Box/Discreteの場合は最大値と最小値も表示
if isinstance(space, Box):
print(' 最小値: ', space.low)
print(' 最大値: ', space.high)
if isinstance(space, Discrete):
print(' 最小値: ', 0)
print(' 最大値: ', space.n-1)
# 学習環境の準備
env = gym.make(ENV_ID)
# 行動空間と状態空間の型の出力
print('環境ID: ', ENV_ID)
print_spaces('行動空間: ', env.action_space)
print_spaces('状態空間: ', env.observation_space)実行結果は、次のとおりです。
$ python check_space.py 環境ID: CartPole-v1
行動空間: Discrete(2)
最小値: 0
最大値: 1
状態空間: Box([-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38], (4,), float32)
最小値: [-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38]
最大値: [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38]次回
この記事が気に入ったらサポートをしてみませんか?