
toio 入門 (3) - 人工知能によるキューブの操作

「Unity ML-Agents」と「toio SDK for Unity v1.4.0」を使って、人工知能でtoioキューブを操作する方法をまとめました。
・Unity 2020.3
・toio SDK for Unity v1.4.0
・Unity ML-Agents Release 19
前回
1. 学習環境の概要
強化学習エージェント(人工知能)にキューブをターゲットポールまで移動させることを学習させる学習環境を作成します。ターゲットポールは、toioシミュレータで「Ctrl-右クリック」で配置できます。
今回の学習環境の状態・行動・報酬は、次のように設計します。
・状態 : Vector Observation、サイズ5
・0 : キューブのX座標
・1 : キューブのZ座標
・2 : キューブの向き (0.0〜1.0)
・3 : ターゲットポールのZ座標
・4 : ターゲットポールのZ座標
・行動 : Discrete Action、サイズ1
・0 : キューブの操作 (0:なし, 1:左, 2:右, 3:上, 4:下)
・報酬・エピソード完了
・キューブがターゲットポールにたどり着いた時 : 報酬「1.0」+エピソード完了
・プレイマットから落下した時 : エピソード完了
2. 開発環境の準備
開発環境の準備の手順は、次のとおりです。
(1) 「toio SDK for Unity」のインストール
「toio 入門 (1) - 事始め」と同様です。
(2) 「Unity ML-Agents」のインストール
「Unity ML-Agents Release 18 のチュートリアル」とほぼ同じ手順で「Release 19」をインストールします。
3. 学習環境の準備
学習環境を準備する手順は、次のとおりです。
(1) Hierarchyウィンドウの「Main Camera」と「Directional Light」を削除。
(2) Projectウィンドウの「/Assets/toio-sdk/Scripts/Simulator/Resources」の「Cube」と「Stage」を、Hierarchyウィンドウにドラッグ&ドロップ。
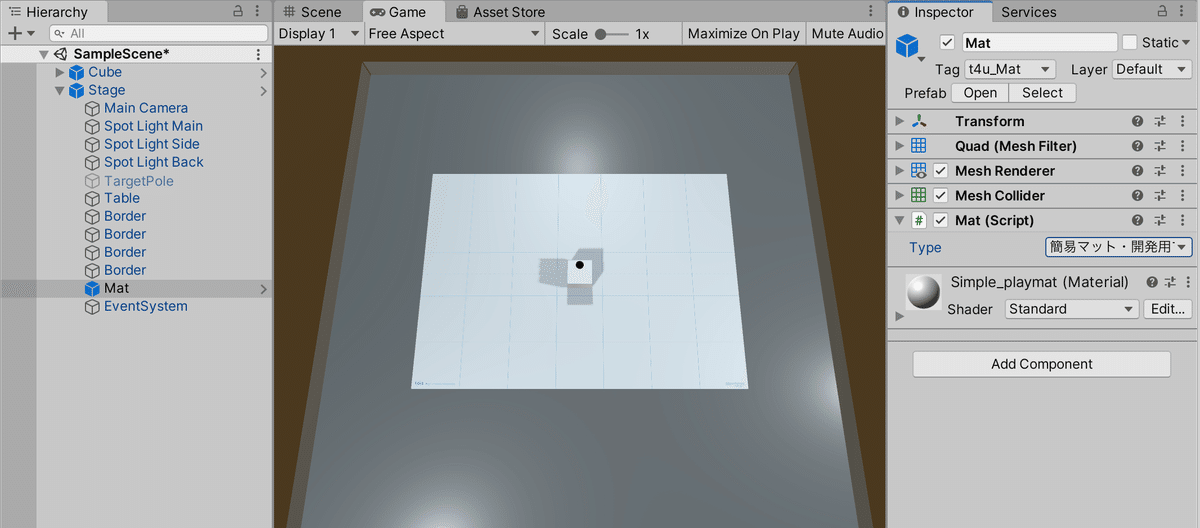
(3) Hierarchyウィンドウで「Stage→Mat」を選択し、Inspectorウィンドウの「Mat → Type」で利用するプレイマットを選択。
以下は、「簡易マット」を選択した時の見た目です。
4. Unity ML-Agentsのコンポーネントの追加
学習環境に「状態」「行動」「報酬」「エピソード完了」の情報を設定するため、「RollerAgent」に「Unity ML-Agents」のコンポーネントを追加します。
・Behaviour Parameters
・Agentクラスを継承したスクリプト
・Decision Requester
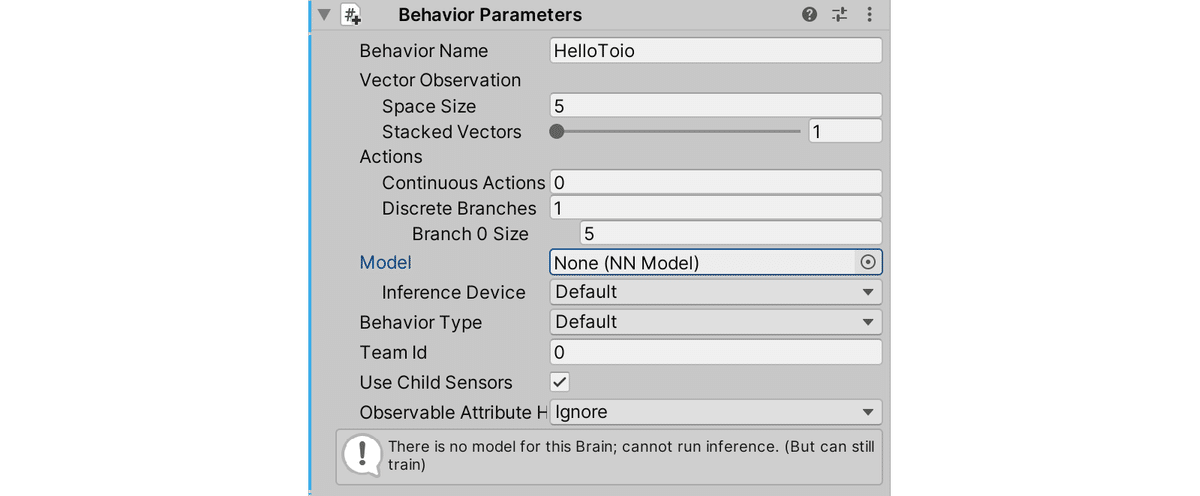
5. BehaviorParametersの追加
「BehaviorParameters」は、強化学習エージェントのパラメータを設定するコンポーネントです。
(1) Hierarchyウィンドウで「Cube」を選択し、「BehaviorParameters」を追加。
(2) 「BehaviorParameters」を以下のように設定。
6. Agentクラスを継承したスクリプトの追加
Agentクラスを継承したスクリプトでは、以下のAgentクラスのメソッドをオーバーライドすることによって、強化学習に関するエージェントの各種処理を実装します。
(1) Hierarchyウィンドウで「Cube」を選択し、新規スクリプト「CubeAgent」を追加し、以下のように編集。
・CubeAgent.cs
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Policies;
using toio;
using toio.Simulator;
// キューブエージェント
public class CubeAgent : Agent
{
// 設定
public ConnectType connectType; // 接続種別
// 参照
CubeManager cm; // キューブマネージャ
Stage stage; // ステージ
Mat mat; // マット
Transform targetPole; //ターゲットポール
GameObject cube; // キューブ
// マットサイズ
float matW = 0.4f;
float matH = 0.3f;
// 初期化時に呼ばれる
async public override void Initialize()
{
// 参照
this.stage = GameObject.FindObjectOfType<Stage>();
this.mat = GameObject.FindObjectOfType<Mat>();
this.targetPole = this.stage.transform.Find("TargetPole");
this.cube = GameObject.Find ("Cube");
// キューブの接続
this.cm = new CubeManager(connectType);
await this.cm.MultiConnect(1);
}
// エピソード開始時に呼ばれる
public override void OnEpisodeBegin()
{
// ターゲットポールのランダム配置
while (true) {
float x = Random.value * matW * 0.8f - (matW * 0.8f / 2f);
float y = Random.value * matH * 0.8f - (matH * 0.8f / 2f);
this.targetPole.position = new Vector3(x, 0, y);
float distance = Vector3.Distance(this.cube.transform.position, this.targetPole.position);
if (distance > 0.06f) {
this.targetPole.gameObject.SetActive(true);
break;
}
}
}
// 状態取得時に呼ばれる
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(this.cube.transform.position.x);
sensor.AddObservation(this.cube.transform.position.z);
sensor.AddObservation(this.cube.transform.rotation.eulerAngles.y/360f);
sensor.AddObservation(this.targetPole.position.x);
sensor.AddObservation(this.targetPole.position.z);
}
// 行動実行時に呼ばれる
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// キューブの操作
int action = actionBuffers.DiscreteActions[0];
foreach (var handle in cm.syncHandles)
{
if (action == 1) handle.Move(0, -40, 100, false); // 左
if (action == 2) handle.Move(0, 40, 100, false); // 左
if (action == 3) handle.Move(40, 0, 100, false); // 上
if (action == 4) handle.Move(-40, 0, 100, false); // 下
}
// プレイヤーがターゲットポールに到着した時
float distance = Vector3.Distance(this.cube.transform.position, this.targetPole.position);
if (distance < 0.03f)
{
AddReward(1.0f);
EndEpisode();
}
// プレイヤーがプレイマットから落下した時
Vector3 cubePos = this.cube.transform.position;
if (cubePos.x < -matW*0.9f/2f || matW*0.9f/2f < cubePos.x || cubePos.z < -matH*0.9f/2f || matH*0.9f/2f < cubePos.z)
{
EndEpisode();
// シミュレータ時のみ
if (this.connectType != ConnectType.Real) {
// キューブの位置と向きの初期化
this.cube.transform.position = new Vector3();
this.cube.transform.rotation = new Quaternion();
}
}
}
// ヒューリスティックモードの行動決定時に呼ばれる
public override void Heuristic(in ActionBuffers actionsOut)
{
float h = Input.GetAxis("Horizontal");
float v = Input.GetAxis("Vertical");
var dicreseActionsOut = actionsOut.DiscreteActions;
dicreseActionsOut[0] = 0;
if (h < -0.5f) dicreseActionsOut[0] = 1; // 左
if (h > 0.5f) dicreseActionsOut[0] = 2; // 右
if (v > 0.5f) dicreseActionsOut[0] = 3; // 上
if (v < -0.5f) dicreseActionsOut[0] = 4; // 下
}
// フレーム毎に呼ばれる
public void Update()
{
// リアル時のみ
if (this.connectType == ConnectType.Real) {
// リアルキューブとシミュレータキューブの位置と向きを同期
foreach (var c in cm.cubes)
{
this.cube.transform.position = this.mat.MatCoord2UnityCoord(c.x, c.y);
this.cube.transform.rotation = Quaternion.Euler(0, c.angle + 90, 0);
}
}
}
}(2) 「CubeAgent」を以下のように設定。

7. Decision Requesterの追加
「DecisionRequester」は、強化学習エージェントの行動決定タイミングを設定するコンポーネントです。
(1) Hierarchyウィンドウで「Cube」を選択し、「DecisionRequester」を追加。
(2) 「DecisionRequester」を以下のように設定。

8. 学習
学習を行う手順は、次のとおりです。
(1) 「ml-agents-release_19フォルダ」直下の「./config/HelloToio.yaml」に 学習設定ファイルを作成。
・HelloToio.yaml
behaviors:
HelloToio:
# トレーナー種別
trainer_type: ppo
# 基本設定
max_steps: 500000
time_horizon: 1000
summary_freq: 10000
keep_checkpoints: 5
# 学習アルゴリズムの設定
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
# ニューラルネットワークの設定
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
# 報酬の設定
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0(2) Pythonの仮想環境で学習コマンドを実行。
高速に学習を回すとキューブへ送る命令が間に合わないので「--time-scale=1」を指定する必要があります。
$ mlagents-learn config/HelloToio.yaml --run-id=HelloToio-ppo-1 --time-scale=1(2) UnityエディタでPlayボタンを押す。
学習が開始します。
Step: 10000. Time Elapsed: 183.130 s. Mean Reward: 0.162. Std of Reward: 0.369. Training.
Step: 20000. Time Elapsed: 332.511 s. Mean Reward: 0.214. Std of Reward: 0.410. Training.
Step: 30000. Time Elapsed: 488.165 s. Mean Reward: 0.222. Std of Reward: 0.416. Training.
:
Step: 170000. Time Elapsed: 2619.922 s. Mean Reward: 0.891. Std of Reward: 0.312. Training.
Step: 180000. Time Elapsed: 2774.181 s. Mean Reward: 0.915. Std of Reward: 0.279. Training.
Step: 190000. Time Elapsed: 2919.990 s. Mean Reward: 0.929. Std of Reward: 0.257. Training.今回の学習環境では、180000ステップほどで、「Mean Reward」がほぼ9.0になります。十分学習できたら「Control+C」で学習を終了してください。「./results/HelloToio-1/HelloToio.onnx」に学習済みモデルが出力されます。
9. 推論
推論を行う手順は、次のとおりです。
(1) 学習済みモデル「HellloToio.onnex」をプロジェクトのAssetsに配置。
(2) HierarchyウィンドウでCubeを選択し、「BehaviorParams → Model」に「HellloToio.onnex」をドラッグ&ドロップ。
(3) Hierarchyウィンドウで「Cube」を選択し、Inspectorウィンドウの「CubeAgent → Connect Type」に「Simulator」を指定。
(4) Playボタンを押す。
10. 実機での推論
実機での推論の手順は、次のとおりです。
(1) プレイマットを敷き、toioキューブを電源を入れて配置。
(2) Hierarchyウィンドウで「Cube」を選択し、Inspectorウィンドウの「CubeAgent → Connect Type」に「Real」を指定。
(3) Playボタンを押す。
11. 関連
「toio」と「ML-Agents」を使って、サッカーを学習させた例は、以下で紹介しています。