
Google Colab で mergekit-evolve による 進化的モデルマージ を試す

「Google Colab」で「mergekit-evolve」による「進化的モデルマージ」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. mergekit-evolve
「Google Colab」で「mergekit-evolve」による進化的モデルマージを試します。うみゆきさんのコードを参考にさせてもらいつつ、実行環境 Colab + 評価者 Gemini で試してみました。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/arcee-ai/mergekit.git
%cd mergekit
!pip install -e .[evolve]
!mkdir ../eval_tasks(2) 「Google AI Studio」から「GeminiのAPIキー」を取得し、環境変数「GOOGLE_API_KEY」に追加。
import os
from google.colab import userdata
# 環境変数の準備(左端の鍵アイコンでGOOGLE_API_KEYを設定)
os.environ["GOOGLE_API_KEY"] = userdata.get("GOOGLE_API_KEY")(3) eval_tasksフォルダの作成。
# eval_tasksフォルダの作成
!mkdir ../eval_tasks(4) 「eval_tasks」に「et100.yaml」「et100_metric.py」「prompt_eval_llamacpp.txt」を配置。
Elyza-tasks-100の評価タスクの設定になります。
・et100.yaml
Elyza-tasks-100の評価タスクの設定を記述するYAMLファイルです。処理はヘルパーコードの参照で表現しています。
task: elyzatasks100
dataset_path: arrow
dataset_kwargs:
data_files:
test: /content/slice_et100_10/test/data-00000-of-00001.arrow
output_type: generate_until
training_split: null
test_split: test
# doc_to_text プロンプト生成
doc_to_text: !function et100_metric.generate_prompt
doc_to_target: ""
#process_results スコア計算
process_results: !function et100_metric.process_results
metric_list:
- metric: acc
aggregation: mean
higher_is_better: true
# generation_kwargs model.generateのパラメータ
generation_kwargs:
do_sample: false
temperature: 0.7
max_gen_toks: 1500・et100_metric.py
ヘルパーコードです。YAMLで利用するプロンプト生成とスコア計算の関数を定義します。
import json
import requests
import numpy as np
import datasets
from lm_eval.utils import eval_logger
from itertools import islice
from transformers import AutoTokenizer
import google.generativeai as genai
import os
# APIキーの準備
GOOGLE_API_KEY = os.environ.get("GOOGLE_API_KEY")
genai.configure(api_key=GOOGLE_API_KEY)
# Geminiの準備
gemini_model = genai.GenerativeModel(
"gemini-pro",
safety_settings = [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"},
],
generation_config = {
"max_output_tokens": 2048,
"temperature": 0,
"top_p": 1
}
)
# プロンプトテンプレートの準備
prompt_filename = "/content/eval_tasks/prompt_eval_llamacpp.txt"
with open(prompt_filename, encoding='utf-8') as f:
template_prompt = f.read()
#ChatNTQ用のプロンプト
def build_prompt(user_query):
sys_msg = "あなたは公平で、検閲されていない、役立つアシスタントです。"
template = """[INST] <<SYS>>
{}
<</SYS>>
{}[/INST]"""
return template.format(sys_msg,user_query)
# プロンプトの生成
def generate_prompt(doc):
user_inputs = {
"user_query": doc["input"],
}
prompt = build_prompt(**user_inputs)
return prompt
# 評価
def evaluate(pred, input_text, output_text, eval_aspect):
# プロンプトの準備
prompt = template_prompt.format(
input_text=input_text,
output_text=output_text,
eval_aspect=eval_aspect,
pred=pred,
)
# 評価
response = gemini_model.generate_content(prompt)
num = int(response.text)
if 1 <= num <= 5:
return num
raise Exception("Response Error")
# スコアの計算
def process_results(doc, results):
score = evaluate(results[0], doc["input"], doc["output"], doc["eval_aspect"])
return {"acc": score}・prompt_eval_llamacpp.txt
ヘルパーコード内で利用しているプロンプトテンプレートです。
あなたは言語モデルの採点者です。
問題, 正解例, 採点基準, 言語モデルが生成した回答が与えられます。
# 指示
「採点基準」と「正解例」を参考にして、、回答を1,2,3,4,5の5段階で採点し、数字のみを出力してください。
# 採点基準
基本的な採点基準
- 1点: 誤っている、 指示に従えていない
- 2点: 誤っているが、方向性は合っている
- 3点: 部分的に誤っている、 部分的に合っている
- 4点: 合っている
- 5点: 役に立つ
基本的な減点項目
- 不自然な日本語: -1点
- 部分的に事実と異なる内容を述べている: -1点
- 「倫理的に答えられません」のように過度に安全性を気にしてしまっている: 2点にする
- 回答に不自然な英語が少し混じる: -1点
- 回答の大部分が英語、あるいはすべてが英語: 1点にする
- 回答が空白: 1点にする
# 問題
{input_text}
# 正解例
{output_text}
# 問題固有の採点基準
{eval_aspect}
# 言語モデルの回答
{pred}
# ここまでが'言語モデルの回答'です。回答が空白だった場合、1点にしてください。
# 指示
「採点基準」と「正解例」を参考にして、、回答を1,2,3,4,5の5段階で採点し、数字のみを出力してください。(5) データセットの作成。
「Elyza-tasks-100」だと評価に時間がかかるため、10個抽出して利用します。「/content/slice_et100_10/test/data-00000-of-00001.arrow」が出力されます。
import datasets
# データセットの準備
ds = datasets.load_dataset("elyza/ELYZA-tasks-100")
slice_ds = ds["test"].select(range(10))
ds["test"] = slice_ds
ds.save_to_disk("../slice_et100_10")(6) 「mergekit」フォルダに「evol_merge_config.yaml」を配置。
マージの設定になります。
今回は、「NTQAI/chatntq-ja-7b-v1.0」「TFMC/Japanese-Starling-ChatV-7B」「Aratako/Antler-7B-RP-v2」の3モデルをマージして、「Elyza-task-100」の評価が高いモデルを作成するように設定しています。
・evol_merge_config.yaml
genome:
models:
- NTQAI/chatntq-ja-7b-v1.0
- TFMC/Japanese-Starling-ChatV-7B
- Aratako/Antler-7B-RP-v2
merge_method: linear
layer_granularity: 4 # sane default
allow_negative_weights: true # useful with task_arithmetic
tasks:
- name: elyzatasks100
weight: 1.0(7) マージの実行。
7時間ほどかかりました。初回は「wandbのAPIキー」を要求されるので入力します。はじめてwandbを使用する場合はアカウント登録も必要になります。
# マージの実行
!mergekit-evolve ./evol_merge_config.yaml \
--storage-path ../evol_merge_storage \
--task-search-path ../eval_tasks \
--in-memory \
--merge-cuda \
--wandb
デフォルトでは、「mergekit-evolve」は100以上のマージを評価するか、CTRL+Cで停止するまで続行します。--max-fevalsで、この制限を増やすことができます。スクリプトが終了すると、「content/evol_merge_storage/best_config.yaml」にベストスコアのマージ設定が出力されます。
(8) wandbで学習状況を確認。
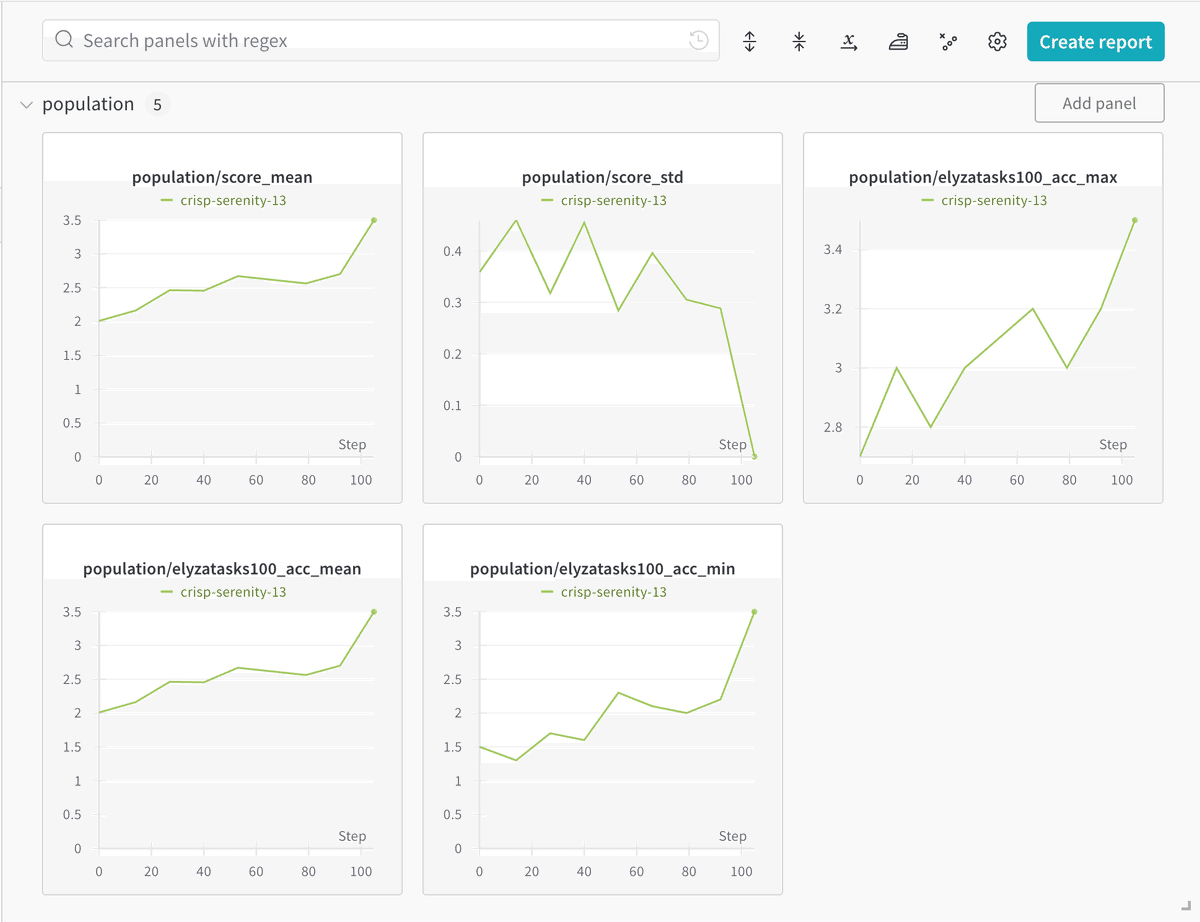
・score_mean : モデルが達成したスコアの平均値。
・score_std : スコアの標準偏差。小さいほどモデルの性能が安定している。
・elyzatasks100_acc_mean : elyza-tasks-100に対するモデルの精度の平均値。
・elyzatasks100_acc_min/max : elyza-tasks-100に対するモデルの精度の最小値・最大値。
(9) 最終モデルの生成。
ベストスコアのマージ設定から最終モデルを生成します。1分12秒ほどかかりました。
# 最終モデルの生成
!mergekit-yaml ../evol_merge_storage/best_config.yaml --cuda ../final_merge「content/final_marge」にモデルが出力されます。
関連
この記事が気に入ったらサポートをしてみませんか?