
JAT (Jack of All Trades) の概要

以下の記事が面白かったので、簡単にまとめました。
・Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent
We are proud to release the first open-source multi-modal, multi-task and multi-domain model! Called JAT. A crucial step for generalist agents. What started out as an open reproduction of GATO with @QGallouedec, @ClementRomac and myself, has evolved into a far greater project. pic.twitter.com/pAtgBZeKVs
— Edward Beeching (@edwardbeeching) April 22, 2024
1. JAT (Jack of All Trades)
「JAT」 (Jack of All Trades) は、ジェネラリストエージェントの推進を目的とするプロジェクトです。このプロジェクトは、視覚と言語 (vision-and-language) のタスクと意思決定 (decision-making) のタスクの両方を実行できるTransformerを学習する 「Gato」の再現としてはじまりました。
「Gato」のデータセットのオープンバージョンの構築からはじめ、マルチモーダルTransformerをその上で学習し、連続データと連続値の処理に関して「Gato」にいくつかの改善を導入しました。
このプロジェクトの成果は、次のとおりです。
・エキスパートRLエージェントのリリース
さまざまなタスクに対応する多数のエキスパートRLエージェントです。
・JATデータセットのリリース
ジェネラリストエージェント学習用の最初のデータセットです。エキスパートエージェントによって収集された何十万もの軌跡が含まれています。
・JATモデルのリリース
ビデオゲーム、ロボット制御、シンプルなナビゲーション環境でのコマンド理解と実行などが可能なTransformerベースのエージェントです。
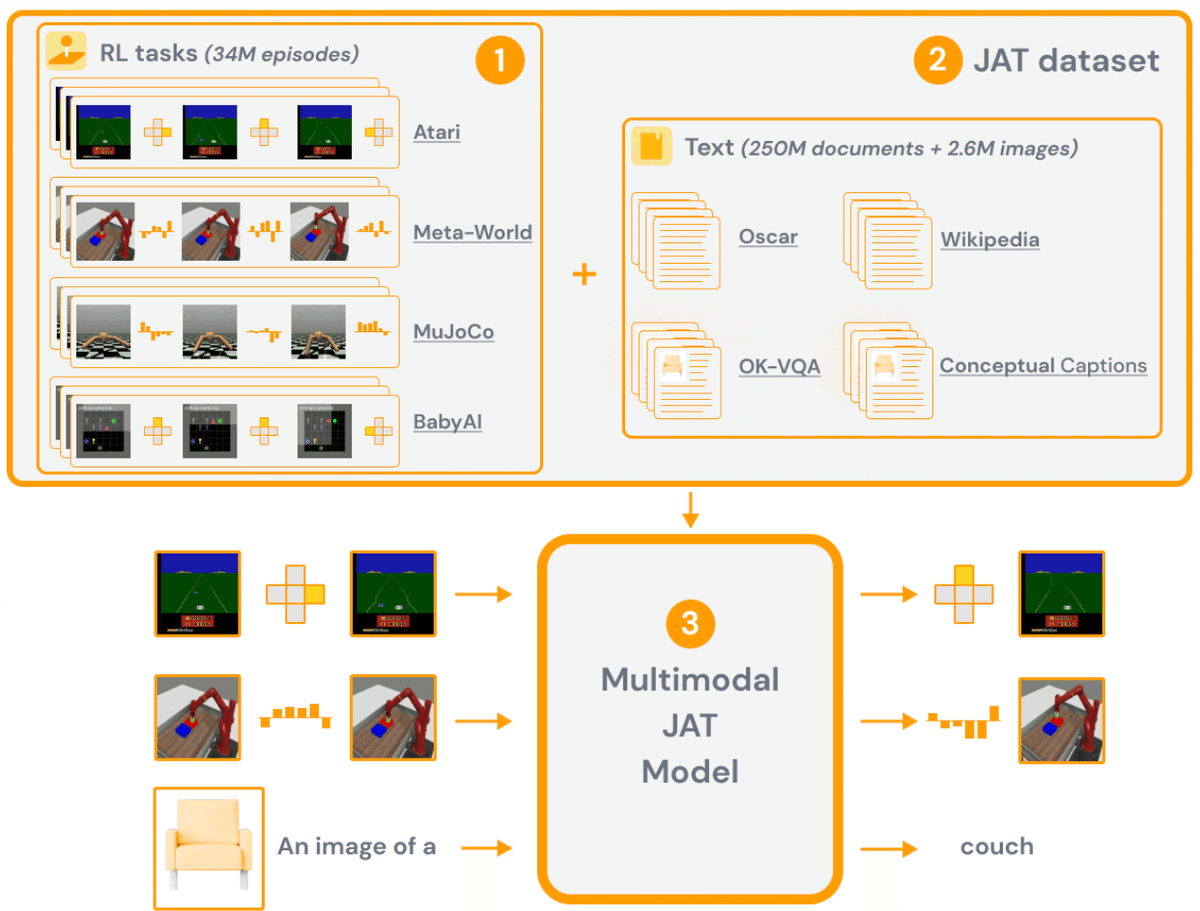
2. データセットとエキスパートのポリシー
2-1. エキスパートのポリシー
RLには従来、単一環境での学習ポリシーが含まれていました。これらのエキスパートポリシーを活用することは、多用途のエージェントを構築するための真の方法です。「Atari」「BabyAI」「Meta-World」「MuJoCo」など、性質や難易度が異なる幅広い環境を選択しました。これらの各環境について、最先端のパフォーマンスに達するまでエージェントを学習します。
学習したエージェント「エキスパートエージェント」と呼ばれ、HuggingFace Hubにリースしています。JATデータセットのカードにすべてのエージェントのリストが書かれています。
2-2. JATデータセット
「JATデータセット」には、エキスパートエージェントによって収集された何十万ものエキスパートの軌跡が含まれています。このデータセットを使用するには、他のデータセットと同様にHuggingFace ハブからロードするだけです。
from datasets import load_dataset
dataset = load_dataset("jat-project/jat-dataset", "metaworld-assembly")
first_episode = dataset["train"][0]
first_episode.keys()
dict_keys(['continuous_observations', 'continuous_actions', 'rewards'])
len(first_episode["rewards"])
500
first_episode["continuous_actions"][0][6.459120273590088, 2.2422609329223633, -5.914587020874023, -19.799840927124023]2-3. JAT エージェントのアーキテクチャ
「JAT」のアーキテクチャは、「EleutherAI」の「GPT-Neo」を使用したTransformerに基づいています。「JAT」の特徴は、本質的に逐次的な意思決定タスクを処理するように構築された埋め込みメカニズムにあります。 観測の埋め込みと行動の埋め込みを、対応する報酬とともにインターリーブします。各埋め込みは、(報酬に関連付けられた) 観察または行動のいずれかに対応します。

「JAT」はこの情報をどのようにエンコードするのでしょうか? データの種類によって異なります。データ (観察または行動) が画像の場合 (Atari の場合のように)、「JAT」はCNNを使用します。 連続ベクトルの場合、「JAT」は線形レイヤーを使用します。 最後に、離散値の場合、「JAT」は線形投影レイヤーを使用します。予測するデータのタイプに応じて、同じ原理がモデルの出力にも使用されます。予測は因果関係にあり、観測値を1タイムステップずつシフトします。このように、エージェントは以前のすべての観察と行動から次の行動を予測する必要があります。
さらに、NLPおよびCVタスクを実行できるようにエージェントを学習できたら楽しいだろうと考えました。これを行うために、エンコーダーにテキストと画像データを入力として受け取るオプションも与えました。 テキストデータの場合は「GPT-2」トークン化戦略を使用してトークン化し、画像の場合は「ViT」タイプのエンコーダーを使用します。
データのモダリティが環境ごとに変わる可能性があることを考えると、「JAT」 はどのように損失を計算するのでしょうか? 各モダリティの損失を個別に計算します。画像および連続値の場合は、MSE 損失が使用されます。 離散値の場合は、クロスエントロピー損失が使用されます。最終的な損失は、シーケンスの各要素の損失の平均です。
3. 実験と結果
157の学習タスクすべてについて「JAT」を評価します。10エピソードを集めて合計報酬を収録します。読みやすくするために、結果をドメインごとに集計しました。
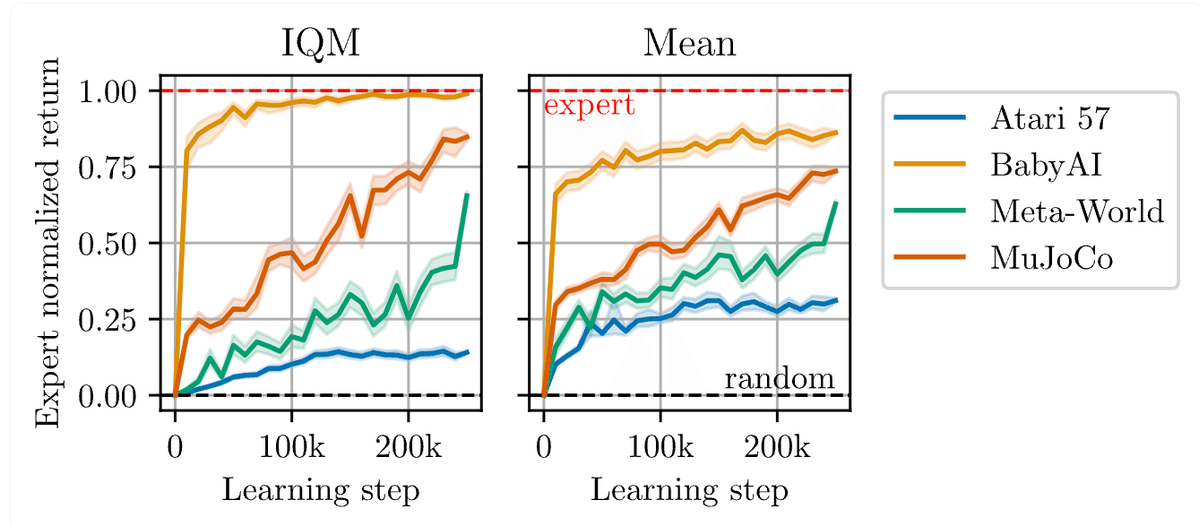
これらの結果を 1 つの数字にまとめると 65.8% となり、4つのドメインにわたる「JAT エキスパート」と比較した平均パフォーマンスになります。これは、「JAT」が非常に幅広いタスクで専門家のパフォーマンスを模倣できることを示しています。
・Atari 57 の場合、エージェントはエキスパートのスコアの 14.1% を達成。これは人間のパフォーマンスの 37.6% に相当。21試合で人間のパフォーマンスを上回る。
・BabyAI の場合、エージェントはエキスパートのスコアの 99.0% を達成したが、わずか1つのタスクでエキスパートの 50% を超えることができなかった。
・Meta-World の場合、エージェントは専門家の 65.5% を達成。
・MuJoCo の場合、エージェントはエキスパートの 84.8% を達成。

最も印象的なのは、「JAT」がすべてのドメインに対して単一のネットワークを使用してこのパフォーマンスを達成していることになります。
4. 観測値を予測することの利点
RLエージェントを学習するときの主な目標は、将来の報酬を最大化することです。 しかし、エージェントに将来何を観察するかを予測するように依頼したらどうなるでしょうか? この追加のタスクは学習プロセスに役立ちますか、それとも妨げますか?
この質問に関しては 2 つの反対の意見があります。一方で、観察を予測する方法を学ぶことで環境をより深く理解し、より良い、より迅速な学習につながる可能性があります。一方で、エージェントの主な目的から気をそらし、観察と行動予測の両方において平凡なパフォーマンスをもたらす可能性があります。
この議論に決着をつけるため、観測損失と行動損失を組み合わせた損失関数を用いて実験を行いました。κを用いて2つの目的のバランスをとります。
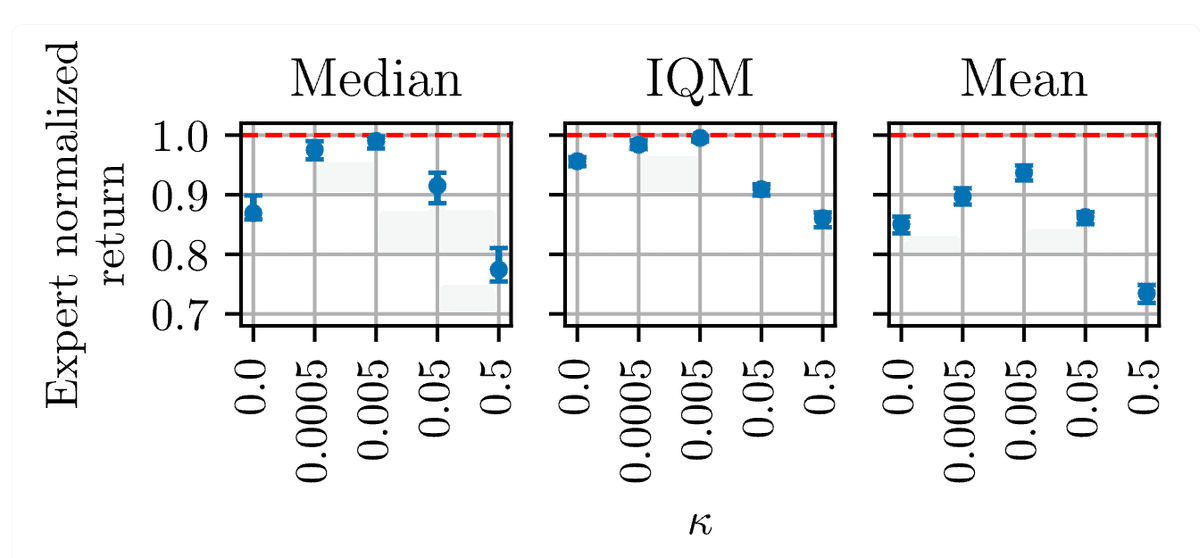
その結果は注目に値するものでした。 κ が高すぎる (0.5) 場合、観測値を予測するという追加の目的が学習プロセスを妨げるようです。しかし、κ が低い場合、学習への影響は無視でき、エージェントのパフォーマンスは、観測予測が目的の一部ではない場合に得られるパフォーマンスと同様でした。
ただし、κ=0.005 付近でスイート スポットが見つかり、観測値を予測する学習によってエージェントの学習効率が実際に向上しました。観察予測を学習プロセスに追加することは、バランスが正しく取れている限り有益であることを示唆しています。この発見は、そのようなエージェントの設計に重要な意味を持ち、学習効率の向上における補助目標の潜在的な価値を強調しています。
したがって、次回RLエージェントを学習するときは、将来何が観察されるかを予測するよう依頼することを検討してください。 パフォーマンスの向上と学習のスピードアップにつながる可能性があります。
関連
この記事が気に入ったらサポートをしてみませんか?