
同時に2つの文章を話せる言語を作ってボカロPになった

寝覚め
人工言語の制作で最も重要なものがコンセプトで、当時、2023年夏の僕の主なそれが、以下の3つだった。
①複数の文章を同時に話せる言語を作りたい
②ない創作ジャンルを提唱したい
③めちゃくちゃキモいVOICEVOXの使い方をしたい
細かく言えば、助動詞の数を増やして文法のほとんどを担わせてみたいなどもあるが、上の3つが主なそれだ。特に①は2021年7月の着想から長らく保留されていて、さっさと形にしたいものだった。実際に動画が投稿されるまで2年以上かかっている。実働制作期間は1ヶ月くらいなので、この空隙はたんなる怠惰の産物にすぎない。
「複数の文章を同時に話す言語」を実現するにあたって最もシンプルなのが、手話やアイトラッキングを構造に取り込んだ仕組みだ。そういった単純な重複度を上げていくことで、おそらくある程度の重複度までは、単位時間あたりの情報量が増えていく(ただし、一つの文章に構造を取り組んだ方が情報量が増える条件などは全く不明である)。他の要素としては、ピッチ、リズム、アクセント、音量や音声スペクトルといった、音楽的な要素を取り込むものも考えられる。いわゆる声調言語ではそういう音楽的要素のいくつかを孕んでいるし、ソルレソルやエアイエアはピッチとアクセントに関するほとんど純粋な言語だ。口笛を使用した自然言語もそれなりの数が存在している。(そういえば、手指の動作だけでなく表情を音素に含んでいる日本手話なども、そういった点で声調言語的な構造かもしれない。)
ただし既存のこれらは1つの文章を作る為にそういった構造を用いているのであって、複数の文章を同時に話しているわけではない。僕が作りたいのは、非声調言語とソルレソルを同時に話す、とか、母音の長短を持たない言語による会話のなかで短母音と長母音でモールス信号的な通信を同時に行う、みたいなものだ。それと、今回の完成形は音声ファイルを想定していたので、手話などの視覚的な要素を含む制作案は最初に排除された。

次に棄却されたのが母音の長短による重複だ。モールス信号を考えれば明らかなように、一重複あたりの情報が少なすぎる為、最終的な単位時間あたりの情報量はそこまで増えない(情報量が多ければいいというわけでもない)し、並列するほかの文章の情報量との差が大きくなりすぎてしまう。要は綺麗でない。
(ところで、関節1つの状態についてモールス信号的な単純な重複をしていくみたいなことをすればほとんど際限なく重複度を上げることができるが、全身をぐねぐねさせながらのコミュニケーションは、あまりにもキショい)
こうして選ばれたのが、「非声調言語とソルレソルを同時に話す」式の二重言語だ。ある程度広く音域をとったり、容易に判断できるなかで1オクターブを細かく分割したりすれば、発音部分と音程部分の情報量に差が出過ぎないであろうことも魅力だった。
こうして初の人工言語制作が始まり、終わった。
以下、実際の制作工程を追っていく。が、ここで話したいことや重要なことはそれではないし需要もなく、なんといっても面白くない為、過度に具体的または瑣末なことは省略される。また、制作からこの記事を書くまで期間が空いているなどして、添付画像のうちいくつかは再現にすぎず、実際の作業ファイルではない。
音素の設定
まず最初に決めたのが音程部分に使える音域だ。取り敢えずオクターブの分割は身近で使いやすい12平均律で決めてしまった。 スケールを固定したらもっと楽しくなるのかもしれないが、次の理由で音域を広げすぎることもできないので、音程部分の情報量が少なくなりすぎてしまう。今回は取り敢えず12半音を順番に割り振っていくことにした。
「オクターブを広げすぎることができない」について、フォルマントの関係でC6以上の高音になると母音の判別が困難になってくるというのは一般に知られている(実際に出してみるとF6でも意外と分かる気もするが……)し、低音のほうでそういった話は聞いたことはないが、G1以下を母音を保持したままモーダルボイスで綺麗に出すのは明らかに困難(フライ系を使ってはいけないというわけではないが……)と思われるため、十分に役割を果たせるのは、広くとっても4オクターブ程度になる。自然と、音程にはC2~C6の48半音を使用するということになっていった。
次に発音部分について、ここで、子音の数を$${C}$$、母音の数を$${V}$$としたときに、
$${( C + 1 ) \times ( V + 1 ) = 48 \times (X+1)}$$
を満たす$${( C,V,X )}$$の組み合わせを考える。この3変数はすべて$${\mathbb{N}}$$に含まれ、1ずつ足されているのはゼロ子音、ゼロ母音などそれ自体が存在しない部分の組合せだ。そして、$${X}$$が半音の少なさ、音程部分の濃度の低さを解消する為に発音部分へと干渉を仕掛けるパーツXの数である。音程がつくのは1音節である為、普通の文章と同じスピードで音声に乗るには、48半音では少なすぎるのだ。この式が満たされていれば、ある文章を構造的に殆ど過不足なく48半音に変換することができる。
結論からいうと、$${( C,V,X )=(23,7,3)}$$となった。弁別性のために$${V}$$を大きくしすぎることもできず、$${V < 5}$$だと薄すぎる。$${C<20}$$でも薄めだが、音声のアウトプットとしてVOICEVOXを利用する事情で$${C}$$を大きくしすぎることもできない。いま12平均律で模索していることを踏まえながら、VOICEVOXで再現できそうな音素を羅列して眺めれば、自然と$${( C,V,X )=(23,7,3)}$$に辿り着いた。つまり、子音の数は23個、母音の数は7個、Xの数が3個だ。
発音部分
前述の通り、今回使用するのはVOICEVOXという日本語を読み上げるツールの為、日本語にない音は基本的に再現することができないが、「音源の制作」で後述する方法によって、以下のような音素で発音部分を作っていくことになった。母音はゼロ母音を合わせて8つ、子音はゼロ子音を合わせて24つになっているのも確り確認できる。

音程部分の干渉によって子音と母音の間に j, w, h がついて、それぞれ硬口蓋化、唇音化、帯気音化の調音変化を起こす。これがXの正体になった。音声にする場合は硬口蓋化してもわかりにくい ki や c 、帯気音化してもわかりにくい x などはやや大袈裟に強調してあげるなどすると親切だ。以上が使用する発音となり、以下のようなしくみで、ゼロを含んだ子音+母音を音程+調音変化に転写することができる。
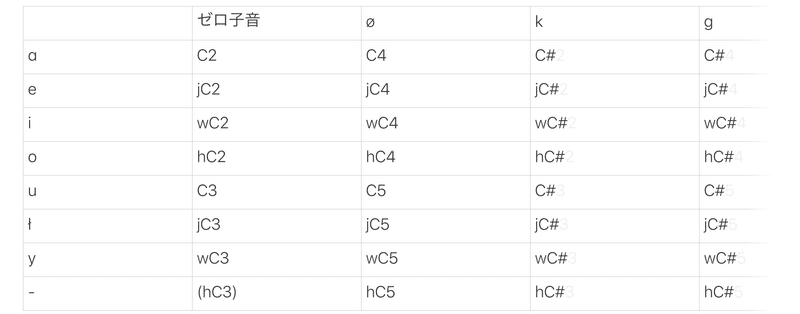
つまり、「ka」という文章と「ge」という文章を同時に話すには、「ge」を音程部分に変換するとjC#4であるから、「kja」をC#4の高さで言えばいいということだ。逆に「ke」をC#3にして、「ge」をC#3の高さで言う、というのも同じことだ。気の向いた方を音程にすれば良いし、ハミングで喋ったりすることもできる。
音程部分
ある音節βαがありβを子音、αを母音とした場合、βにつくマークが音階名、αにつくのがオクターブを表すとすると、音程部分の表記は以下のようになる。

以上の表記をIPAで説明すると、例えばf̊ja̤なら無声唇歯摩擦音+硬口蓋化+非円唇広母音をC#2 の高さで、š̽y̰tなら無声歯摩擦音+ 円唇前舌めの狭母音 + 無声歯茎破裂音(閉音節)をE5の高さで、という感じに喋っていけばよい。
また、今回の音域はC2~C6なので第1、第7オクターブとC6以外の第6オクターブは未使用だが、音程部分の情報量を増やしたいと思ったら使えば良いし、逆に、情報量を減らしたいとか、話者の音域が足りない、とかを思えば第2オクターブを捨てるなどの調節が可能である。ただし、音域を変更した場合には発音部分を音程部分に転写する仕組みにも微調整が必要になってくる。
発音部分の表記体系についてはiPhoneのキーボード、English (Japan)にあるものの中だけでラテン文字転写を構成した。øやłも長押しが必要だが打鍵できる。
音程部分に使うダイアクリティカルマークの添付にはIPAキーボードなどが別途で必要。

しかしこれは飽くまで転写というていだ。本来なら、こういった発音と音程をわかりやすく表記できる専用の表記体系をつくったほうが凝っている。が、ラテン文字転写でも十分な利便性、インパクト、美しさは持っているとの判断で、今回は後回しにすることにした。
(それに関して1番手っ取り早いのはハングルタイプだが、音階も含めて要素が非常に多く、かなり複雑になると想定される。ハングルで可能な組合せ総数はたしか10⁴通りくらいだったはずだが、今回は10⁵くらいだ。そういった場合の追加要素案として、文字の色やフォントを利用するのも無視はされない。特に母音は7つなので、ソルレソルがそうであったように、ここでいう虹の7色に合わせるというのもできる。また、表記体系は別に2次元縛りじゃなくてもよいので、多胞体を使うという予定もあった。シュレーフリ記号を適切に拡張したものをパラメータごとに動かして、なんらかの方法で存在しない図形を避ける、みたいな方法があれば、膨大な組み合わせを規則的な形で実現できるかもしれない。かもしれないだけ。非常に面倒。やはり後回しにすることにした。)
文法の設定
ここでは特筆すべき文法を挙げていく。特筆すべきでないものは挙げない。
尾音
ある文章を音程部分に変換するとき、約物や単語の切れ目は発音部分に干渉する。「ka ki.」という文章と「ge go.」という文章を同時に話すときに後者を音程部分に変換するとjC#4, hC#4であるから、合成した「kja khi.」をC#4, C#4の高さで言えばいいというわけではなく、geとgoの間にあるスペース、goの後にあるピリオドをそれぞれ尾音のaとeに置き換え、「kjaa khie.」をC#4, C#4の高さで言う、というのが正しい合成になる。これで音程変換後も元の文章の情報を失わずにいるのだ。
このような音節の最後につく音を尾音とよぶことにする。韻尾や終声のノリだが、子音に限らない。今まで「子音+母音」という呼び方を続け、「音節」と呼ばなかったのもこれの存在によるものである。尾音のメインの役割は音程部分になる文章における約物等読まない部分の存在を示すことだが、他にも発音部分の数字や節の開始終了、修飾、強調など、構造的にかなり重要なポストについている。
詳しくいうと、文章「As Bt C.」はBの位置に含まれる文章が節であり、単語「DnC」はDがCを修飾して1つの単語を作っているなど(複合語は前置修飾で結合する)である。
なお、現在使用されている尾音は17種で、その内訳は7種の母音+10種の無声子音である。有声子音の内破音は必要にならなかった。
数字
数字の読みは一意性を持たない。たとえば6を読むときでは、
6=kł
=6*1=kłøeka
=6^1=kłøika
=1*6=kaøekł
=2*3=keøeki
=2+2+2=keøakeøake
=2*(1+2)=keøeskaøaket
=1+1+1+1+1+1=kaøakaøakaøakaøakaøaka
etc……
といったふうな読み方が考えられる。数値が最終的にあっていればなんの問題もない。s-tは節を示す尾音だと説明したが、上の例でわかるように計算に於ける括弧の役割も果たす。これは直感的で嬉しい。
上の6の例でわかっただろうが、ø+母音が演算子で数式を構成していく。単体の数字はkaで1、keで2、kiで3、koで4、kuで5、kłで6、kyで 7、gaで8、……、ćyで154、と続く。子音+母音のうち演算子になるøを除いたものだ。
演算子øαはøaで足し算、øeで掛け算、øiで冪乗、øoでテトレーション、øuでペンテーション……と続いていく。したがって、3音節で表せる最大の数はクヌースの矢印表記法でćyøyćy=154↑↑↑↑↑154(デカい)ということになる。一応言っておくと、もちろん、それ以下の数が全て3音節以内で表されるというわけではない。グラハルは3↑↑↑↑3=kiøłkiだが、グーゴルプレックスは10^10^100=giøigiøišeだ。計算の優先度も演算子に依存する。
なお、本編中の音程部分2フェーズ目2文目、
ćygł typiric giøikoc nłdyc ćiøešec xeruśa.
を変換すべきところ
ćygł typiric giøekoc nłdyc ćiøešec xeruśa.
を音程に変換したものになっているのはミスで、
10000=10^4であるべきところが400=10*4になってしまっている。(数字の前の単語の最後と数字の単語の最後についている閉音節のcは数字の開始/終了を表す尾音。)
文法ミスは他にもあるかもしれない。見つけ次第ここに載せていくが、頑張ってミスを探そうとすることは恐らくないので、もう見つからないかもしれない。
助動詞
わざわざ見出しを立てるほどではないかもしれないが、やりたかったことの1つなので言及する。この言語は助動詞にできそうなものを助動詞にしており、接続詞も助動詞に含まれているほか、日本語の古典や諸外国語を参考にして、更に固有のものも混ぜ、かなり豊富なニュアンスを一手でつけることができる。→「nytytagyćyńłtyxami」(持っていない筈だったが)のnytytagyćyńłtyは打消過去推測当然逆接の助動詞で、これはもちろんny+ty+tagy+ćy+ńłtyであって基本パーツから容易に推測可能である。同様にして他の単語も、最後の子音がšなら知覚に関連する、などというふうにある程度分割が可能であり、やや推測しやすいようにはなっている。
今回説明するものは以上だが、当然他にも、エスペラント的な単語の品詞で最後の母音が変わるしくみ、対応する第一子音と第二子音を入れ替えることで対義語になるしくみ、8種類の格、代名詞、約物、接頭辞・接尾辞など、細かいものはもっと沢山ある。それがなければ言語にはならない。
吟風と合成
ここからがものの生まれはじめる工程、所定の文法にしたがって、単語を作り、文章を作っていく。今回は2つの文章を同時に話す言語の為、文章は同程度の長さを持つものが2つ必要になる。それができたら、片方を音程に変換してひとつの文章に合成する。
さて、文章が2つできた。
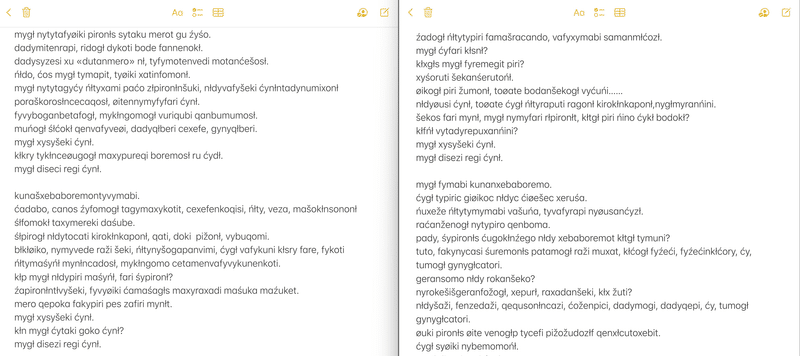
子音+母音を音程+調音変化に変換するプログラムを組んで、

実行して、

音程を文章に合成して、新たな創作ジャンル「二重詩」の詩が完成。

ピッチ情報を例のダイアクリティカルマークに変換してもう片方へ合成するだけでもかなり時間がかかった。既に二度とやりたくない。
音源の制作
この工程で使用するソフトはVOICEVOXだ。VOICEVOXは日本語の音声を合成音声が読み上げるツールなので、日本語にない音は基本的に再現できない。しかし、子音・母音の長さを個別で調節する機能が付いている為、「ん」と「げ」を入力して、nとgの長さをいい感じに調節してやれば、通常では組み込まれていない「ŋe」に近い音を出すことができる。同様にして、「θ」を「th」→「たは(たふ)」、「æ」を「ae」→「あえ」というふうにひらがなに転写していく作業を行なっていく。ただし、「!」はそういった手法でも再現できないので、「t」や「k」で代用したあと、音源の該当部分へ「!」音を添えるなどする。かなり力業だが、思ったより違和感はない。
では、文章をひらがなに近似して(「は」はそのまま読ませると「wa」で発音してしまい修正が面倒なので「歯」で読ませたりする)、

子音の長さの調節などして、音程をもたない音源が完成。

次に、VocalShifterを使用し、文章に合わせて素音源のピッチを調整していく。ほぼ全ての音節にピッチ補正をかける必要があり、これも中々の手間である。やっていることとしては、事前にリズムだけ合わされているびっくりチキンに歌を歌わせているのと近いが、スケールもメロディーも元となる音源もないので、音楽初心者が聴覚を失った状態で一度も聴いたことのない歌の楽譜をみてびっくりチキンを補正するような作業だ。リズムを合わせる必要がなくて本当に良かった。

こんな感じの操作をひたすら繰り返していって、音声が完成する。
完成
音声だけだと味気ないので、ドラム等の楽器とノイズと効果音と字幕と翻訳を添え、ymm4でいい感じの動画を作って完成。

噪音でない音程を持つ楽器はことばになってしまう為、このような雑音が伴奏になる。動画はフレームレートの上げ過ぎで何度かPCがクラッシュしたが、最終的には伴奏と動画の何れも文章・音声のカオスさに沿ったカオスさにすることができた。強いていえば、少しイラストをサボりすぎたのが反省点か、今みると使い回しが多すぎるし、雑だ。

よおし完成だ、聴いてみよう、うん?これは……現代音楽…………
━━━━━━こうして僕はボカロPとしてデビューを果たしたのだ。
『ぼくらはなにを云っているんだ / 春日部つむぎ』
この記事が気に入ったらサポートをしてみませんか?