
GPTsの作り方|Knowledgeの設定方法を解説

「GPTsのKnowledgeって何?」
「Knowledgeの設定方法が分からない」
「思ったようにKnowledgeから出力されない」
本記事ではこのような方を対象に、GPTsにおけるKnowledge設定の基本ついて書いています。
■本記事で分かること
GPTsにおけるKnowledge設定の基本
■本記事の信頼性
私は、本業でChatGPTなどのAIツールを活用して効率化を実現。ほぼ毎日定時で帰宅し、家族との充実した時間を確保している「なおき」といいます。
ITやプログラミングと無縁の体育系で文系出身の私でもできるKnowledgeの設定方法をわかりやすく説明できるよう頑張りますので、よろしくお願いします。
この記事を読み終える頃には初心者の方でもKnowledgeを活用したGPTsを作れるようになることが目標です。
また、2024年1月10日、OpenAIはGPT Storeを開設しました!
これにより、自分の作ったGPTsをGPT Storeで公開し、収益化できるチャンスが到来しています。
Store開設当初から世界中で約300万個以上のGPTsが作成されていると言われていますが、2024年1月現在では開設したばかりで、その存在もほとんどの人は知りません。
実際、私の職場の人は「ChatGPT…?( ゚д゚)ポカーン」状態です。
世界の方々が作る便利なGPTsを使って自分の業務を効率化したり、収益をアップすることもできると思います。
でも、使う側ではなく、作って売る側、すなわち収益の源泉であるGPTsを作ることができれば、莫大な収益をあげることができるかもしれません!
実際に、2022年のApp Store経済圏の売上は約150兆円で、その90%以上が開発側の売上になっています。
App Storeのデベロッパは、2022 年にApp Store経済圏で合計1.1兆ドルの売上を記録」売上の90パーセント以上は、Appleに手数料が支払われることなく、デベロッパの収益となります」
ぜひ、Knowledgeを設定した自分だけのGPTsを作成して、収益化のチャンスをモノにしましょう!
1.GPTsの概要
GPTs(GPT Builder)とは、「ChatGPT特有の『自然言語処理』を使用して、オリジナルのチャットAIを作ることができる」ものです。
自然言語処理って何かというと、
いわゆる「普通の会話」です。
私は関西出身の転勤族なのでエセ関西弁で話しますが、そんな感じの会話でもAIとして適切な答えを返してくれます。
では、オリジナルのチャットAIを作ると何がいいのか?
一言でいうと「自分の仕事や趣味に最適化したAIが何かと助けてくれる」ことだと思います。
例えば、自動化したい作業の補佐、膨大な資料から知りたい情報だけを抽出、写真撮影のコツや英語学習の進め方を教えてくれるだけでなく、実際に解決してくれるデキる奴ということです。
そのポテンシャルは凄まじくて、ホームページの自動作成、ロゴマークの自動作成、データの自動収集、大量の論文から情報を要約するなど、今まで人力で疲弊しながらやっていたことが一言でできるようになっています。
GPTs(GPT Builder)をうまく使えれば、普通に会話するだけで自分のやりたいことや知りたいことを教えてくれて、更に解決してくれるようなチャットAIを作ることができるようになる(当然、限界はありますが)と考えていただければ良いかと思います。
これ以降、Knowledgeの使い方の本題に入っていきますが、GPTsの基本的な使い方が分かっている方を前提として話を進めます。
前提が分からない!という方は「GPTsの基本と使い方」を👇の記事で紹介しているので参考にしてください!
2.GPTsのKnowledgeの使い方
では、さっそく本題のKnowledgeの使い方について解説していきます。
2.1 Knowledgeとは?
「このデータの中身を参照してね!」と、事前にGPTにデータを渡しておく機能です。
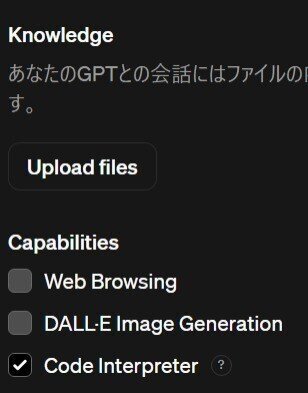
次の画像赤枠内がConfigure画面のKnowledgeの場所です。
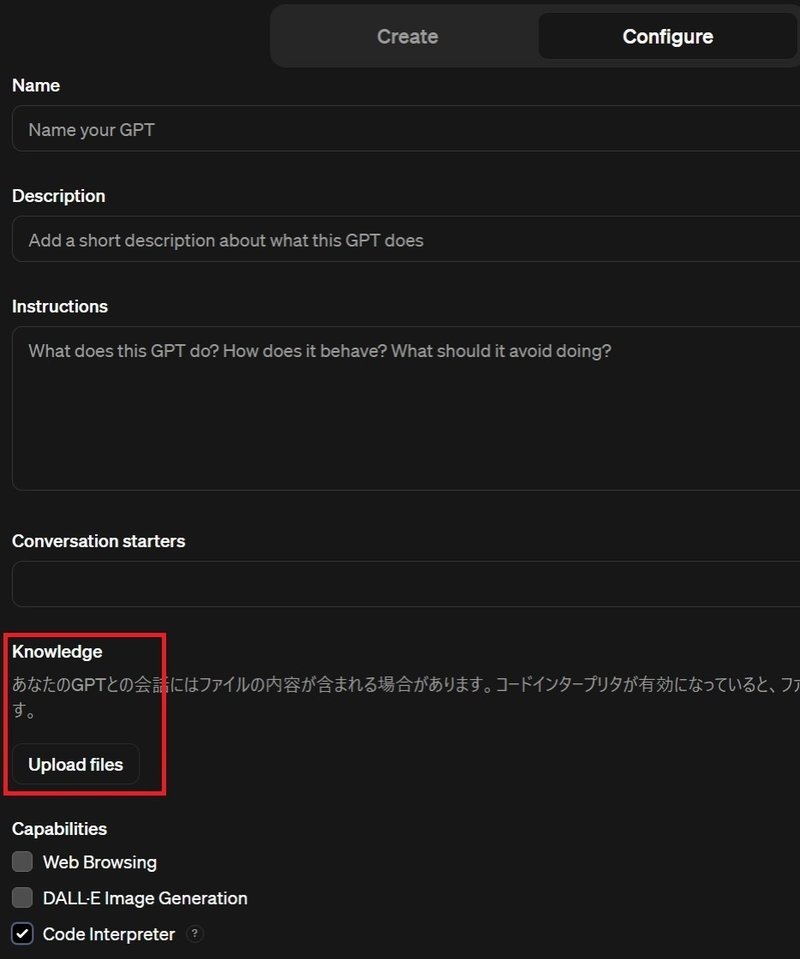
この「Upload files」とある場所をクリックすればデータをGPTs上にアップロード、すなわち、「データを事前に渡すこと」ができます。
ただし、事前に渡すデータについてはデータサイズとトークンに注意が必要です。
最大で渡せるファイルのサイズは 512 MB 、2,000,000 トークン以下です (ファイルを添付すると自動的に計算されます)。
トークンってざっくり言うと、文章量とか文字列ですかね。
ちなみに、ChatGPTは英語のほうが強いので、日本語のデータよりも英語のデータのほうが読み込むトークン数が少なくなります。
(大まかな目安として、1トークンは英語のテキストで約4文字または0.75語)
このため、knowledgeで使うとなると当然英語の方が多い文章量を読み込めるということです。
ちなみに、knowledgeを使ってデータを渡してみるとこんな感じです。
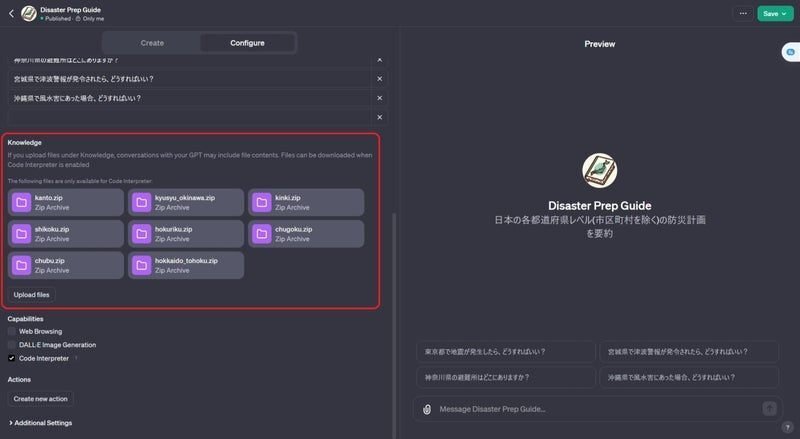
上の画像は、データ量の規制を知らずにアップロードしまくった結果、作成を断念したやつです…
また、渡せるファイルの種類は下記URLを参考にしてください。
OpenAI プラットフォーム
色んな方が書いているブログや記事を見ると、「txt形式」のファイルが一番読み込みも早く、誤作動も生じにくそうです。
まぁこんな感じで「この資料読んどいて!」と渡しておいて、後で「これってなんやっけ?」と聞けば「これは〇〇ですよ。」と教えてくれるようなイメージです。
これの何がすごいかというと、今までのChatGPTは同じチャットの中でも会話が長くなったり、文章量が多くなると、以前の会話内容を忘れて出力することがありました。
しかし、Knowledgeを使うと、ただのGPTが「事前に渡したデータは絶対忘れずに働いてくれる。」という記憶力がすごい人になれるのです。
2.2 Code Interpreterの設定
Knowledgeにファイルをアップロードできたら、次はCode Interpreterにチェックを入れて下さい。
「Code Interpreter」とは、プログラミング言語である「Python(パイソン)」のコードを記述して実行できるようになる機能です。
Code Interpreterを使うと、様々なデータのファイル処理を自動で実行し、データ解析などを実施してくれます。
これにより、事前にKnowledgeでアップロードしたデータを自動で解析し、出力してくれるようになります。
ただ、Code Interpreterは万能ではありません。
GPTの仕組みは「大体同じ意味合い(ベクトル)のある文章はどれ?」というベクトル検索を実行するため、長大な文章資料で項目名やファイル名が全然整理されていなければ、ベクトルがよく分からなくなり、必ずしも望んだ結果が得られない可能性があります。
このような点を踏まえると、Knowledgeに渡すデータは
データサイズが軽く、トークン数を超えないこと
データ内容が簡潔に体系立てて整理されていること
データの種類が多い場合は分類整理を確実に行うこと
上記の点は精度の高い出力を目指す場合の必須条件であると言えるのではないでしょうか。
3.GPTsのKnowledge実践例
ここまでの内容が理解できた方は、Knowledgeの使い方についてほとんど理解できていると思います!
あとは、実際に自分で作ってみて思ったような出力ができるか確認していくのが一番の近道ですが、実践例を紹介するので参考にしてくださいね!
ちなみに
実践例の最後の方で『効率よくKnowledgeのデータを集める方法』を紹介しますので、これも是非あわせてご覧ください!
3.1 ファイルのアップロードとCode Interpreterの設定
まずは、GPTを作成する画面に遷移して、Configure画面でKnowledgeに事前に渡したファイルをアップロードしてください。
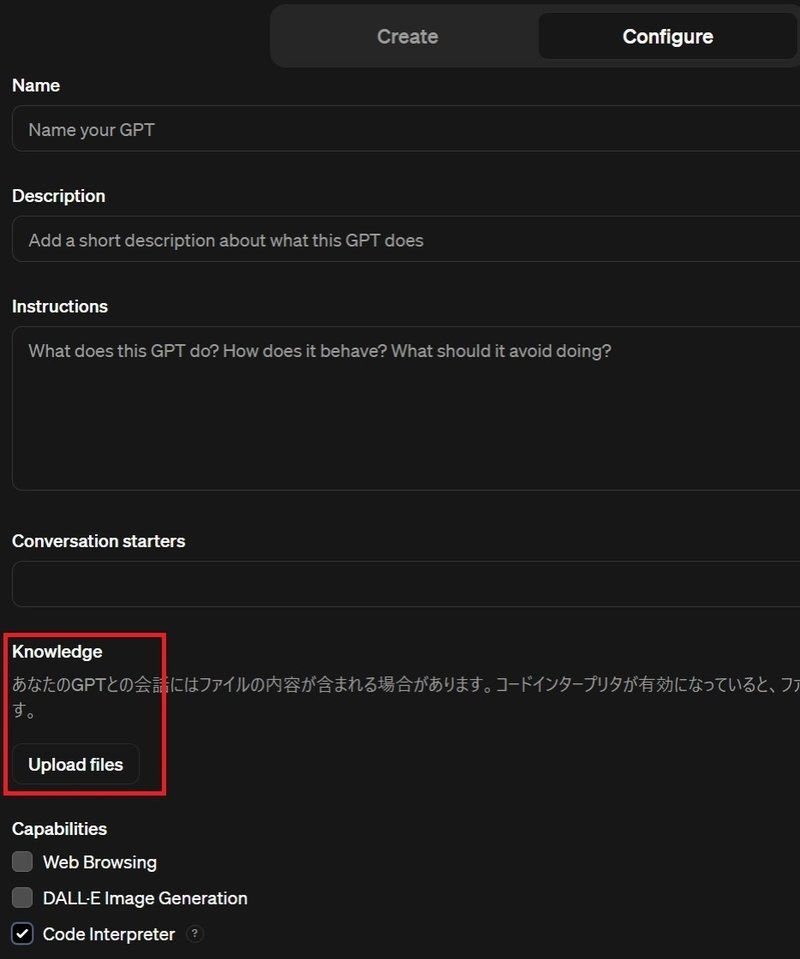
アップロードできたら、Code Interpreterにチェックを入れるのを忘れないようにしてください。
実は、すでにこれでKnowledgeの設定は終わっています。
実際に動作を確認してみると…
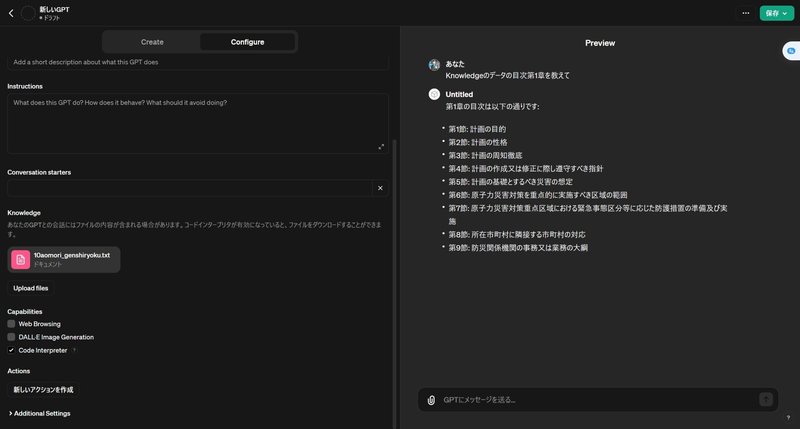
今回、私は「青森県の原子力防災計画」をtxt化したものをアップロードしましたが、「目次の第1章を教えて」と聞くと、完璧に出力してくれました。
単一のファイルであれば、これだけの設定で完璧な出力が期待できます。
これは以下のような事例で最も効果を発揮するのではないでしょうか?
読む気の起こらない社内マニュアルの中から何かを探したい場合
極厚辞書などの中からピンポイントで何かを探し当てたい場合
過去の経緯をさかのぼってまとめたい場合
皆さんの豊富な知識や経験を組み合わせるとさらに多くの効果的な使い方が生まれそうですね!
3.2 Instructionsなどの入力
次に、GPTの名前、概要、使用方法(Instruction)を入力してください。
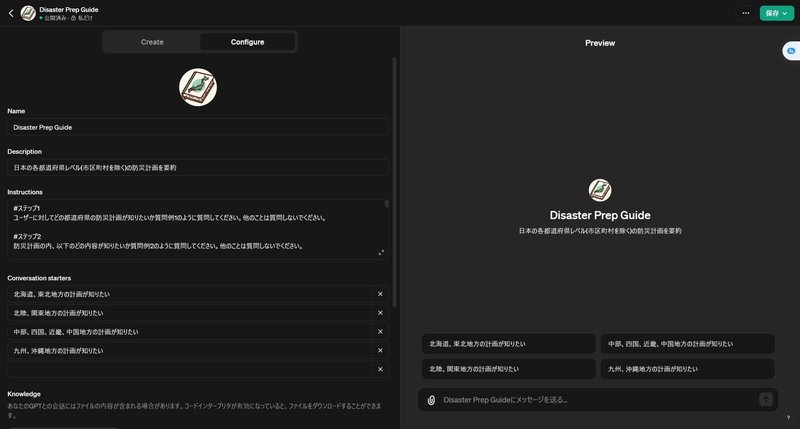
今回、私は「Japan Disaster Prep Guide」という「日本の各都道府県レベル(市区町村を除く)の防災計画を要約」してくれるGPTを作ってみました。
以下は実際に設定した名前、概要、使用方法(Instruction)です。
【Name】Japan Disaster Prep Guide
【Description】日本の各都道府県レベル(市区町村を除く)の防災計画を参照できます。まずは、調べたい地方を選んでください。
【Instruction】
#ステップ1
Conversation startersで選択された地方に基づき、「#地方一覧」を参考にして自動的にステップ2に移行してください。
#ステップ2
ユーザーに対してどの都道府県の防災計画が知りたいか「#質問例1」のように質問してください。他のことは質問しないでください。
#ステップ3
各種計画の内、どの災害に応じた計画が知りたいか「#質問例2」のように質問してください。他のことは質問しないでください。
#ステップ4
・ステップ2とステップ3で選択された項目に基づき、「#キーワード」を含む計画をKnowledgeのUpload filesの中から必ず検索してください。
・もし、該当する計画がない場合、「選択された都道府県には該当する計画がありません」と答えて下さい。
#ステップ5
・該当する計画が見つかったら、自動的に該当計画の中にある目次を列挙して、「#質問例3」のように何が知りたいか質問してください。
#ステップ6
・ユーザーの質問に基づき、計画内の該当する目次の節と節の中に記載のある文章を要約せず正確に出力してください。
・出力内容がまだ残っている場合、「他にも節が残っています。知りたい場合、『つぎ』と入力してください」と言ってください。残っていない場合は「この項目内に記載のある事項は以上です。他に知りたいことはありますか?」と言ってください。
#その他
国内外の利用者に対応するため、質問された言語で回答してください。
#地方一覧
・北海道、東北地方:北海道、山形県、福島県、秋田県、青森県、宮城県、岩手県
・関東地方:東京都、栃木県、埼玉県、神奈川県、茨城県、群馬県、千葉県
・北陸地方:富山県、石川県、新潟県、福井県
・中部地方:長野県、三重県、愛知県、岐阜県
・近畿地方:和歌山県、奈良県、兵庫県、京都府、滋賀県、大阪府
・中国地方:島根県、山口県、広島県、岡山県、鳥取県
・四国地方:愛媛県、徳島県、香川県、高知県
・九州、沖縄地方:福岡県、鹿児島県、熊本県、宮崎県、長崎県、大分県、佐賀県、沖縄県
#質問例1
A:北海道
B:青森県
C:岩手県
D:秋田県
E:山形県
F:福島県
G:宮城県
#質問例2
A:地震
B:津波
C:風水害
D:原子力
E:火山
F:大規模事故
G:本編、基本計画
#キーワード
災害の種類に応じた防災計画ごとに以下のいずれかのキーワードが計画のファイル名に含まれています。
・地震:jisintsunami,sinsai,jishin,jisin,nankaitorafu,jisinshiryou
・津波:tunami,tsunami,jisintsunami,tsunamishiryou
・風水害:huusuigai,huusuigaishiryou
・原子力:genshiryoku,genshiryokushiryou
・火山:kazan,kazanshiryou
・大規模事故:daikibojiko,jiko,daikibijiko_siryou,jikotou,kasaijiko
・本編、基本計画:kihonkeikaku,bousaikihonkeikaku,bousaikeikaku,sousoku,chiikibousaikeikaku,honpen,ippan
#質問例3(章が大見出しの場合)
A:第1章 総則について
B:第2章 原子力災害事前対策について
C:第3章 緊急事態応急対策について
D:第4章 原子力災害中長期対策について
E:何の章があるか教えて
#質問例3(部が大見出しの場合)
A:第1部 総則について
B:第2部 災害予防計画について
C:第3部 災害応急・復旧対策計画について
D:資料編について
E:何の部があるか教えてInstructionを見ていただけると分かるように、今回は添付したデータの量が非常に多い(47都道府県の各防災計画)ため、Code Interpreterで検索させる範囲を狭めていくようなステップを設定しています。
データ量が多くなる人は以下の点に留意が必要です。
ステップが多すぎるとユーザーが使いづらく感じる。
ステップが少なすぎると検索範囲が広くなるため、出力精度の悪化、出力速度の低下を招く。
この部分はKnowledgeを使用する上で、「妥協点をどのあたりに設定するか」という、まずは制作側の判断になるでしょう。
もし、GPT Storeで販売することになった場合はユーザー評価などから改善していく必要がありそうです。
実際に今回作ったGPTの動作確認をすると、なかなかうまく出力されないことが分かります。
これは、データの中身、特に目次部分が体系立てて整理されていないことが原因であると考えられますが、今回はお試しということで妥協します(笑)
とりあえず、市役所の防災担当職員の方々など、普段から防災計画に携わっている方が他県の計画を参考にする際などに使えるものにはなっているのではないでしょうか?使うか知らんけど(;´∀`)
ここに作成したGPTのリンクを貼っておくので、興味のある方は使ってみてください。
そして、ここからは更にKnowledgeを効率的に作っていきたい!という方に向けて、「PDFデータの自動収集方法」と「PDF等のデータを自動でtxt化する方法」などについても解説してきます!
ちなみに、私はPython言語が読めません
少しかじろうと思ったのですが、2児の父となり、30歳を超え、フルタイムで働く私には無理で挫折しました…
いかに定時で帰宅しても子供を寝かしつければ21時過ぎ
時間も金も体力もありません
そんな方でも一瞬でできてしまう便利な時短術を紹介するので、興味のある方は是非ご覧ください!
今ならXで紹介してくれた方に特別価格『980円』でご覧いただけます!
ここから先は
この記事が気に入ったらサポートをしてみませんか?