
スーパーとりんさま alpha2の日本語大規模言語モデル性能をはかる

現在稼働中の「スーパーとりんさま alpha2」で新たに対応した指示チューニングと、開発者向けAPIを用い、W&Bの方式で日本語推論性能の評価を行いました。
テストのメニューおよびフォーマットはW&B「LLMのJGLUEによる日本語タスクベンチマーク」に基づいています。
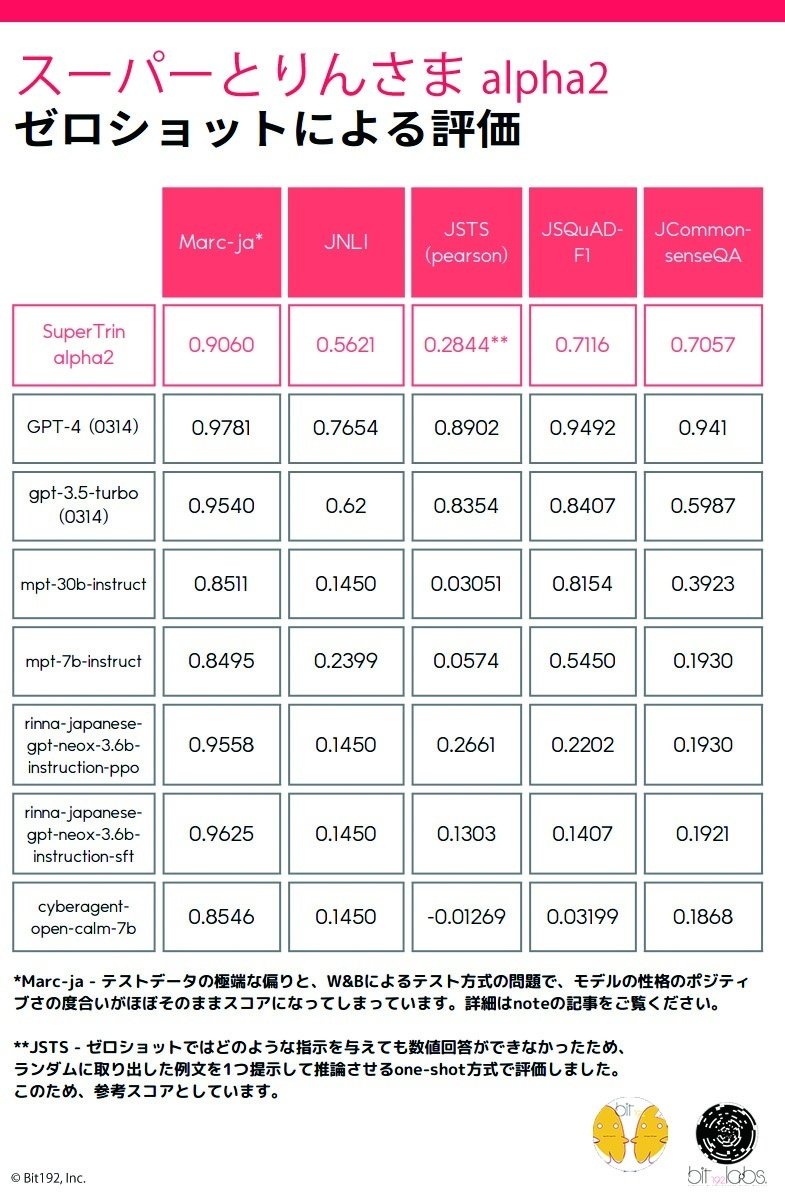
ベンチマーク結果
JNLI、JSQuAD-F1、JCommonsenseQAの3つのカテゴリにおいて、zero-shotでGPT-3.5 Turboに次いで世界3位のスコアを記録しました。うちJCommonsenseQAではGPT-3.5 Turboを大きく上回るスコアとなっています。
3カテゴリの平均スコア
GPT-4 (0314) - 88.52%
GPT-3.5 Turbo (0314) - 68.64%
スーパーとりんさま alpha2 - 66.25%
詳細スコア
注記
☆ MARC-ja
W&Bの評価方式に従いましたが、そもそも肯定的なレビューのサンプルが否定的なレビューのサンプルに対して異常に多く、MARC-jaのスコア=モデルのポジティブバイアスになってしまっています。現状では、ベンチマークとしては意味をなしていません。
☆ JNLI
フォーマットに従い、英語で回答させています。
☆ JSTS
ゼロショットではどのような指示を与えても数値回答ができなかったため、ランダムに取り出した例文を1つ提示して推論させるone-shot方式で評価しました。このため、参考スコアとしています。また、JSTSは2つの短文間の相関度を0~5の浮動小数で答えるテストですが、モデルが数値を返さなかった場合の回答はW&Bに従い2.00として処理しています。
テクニカルな所見
「テストセットのジャンルが短い文章に対する評価に偏りすぎている」という課題は英語のテストセットにもありますが、JGLUEによる日本語のテストはこの現象が特に顕著です。
実際に大規模言語モデルを扱う上では数千から数万文字に及ぶ文章を読ませて要約や推論を行わせるケースが多々ある一方、長い文章に対して一貫した論理を保って出力ができるかどうかは現状の日本語テストセットでは全く判断できません。
今回、試験で使用した「スーパーとりんさま」は4096トークンまでの推論に対応しており、GPT-3.5-0314は4096(16k版は16384)、GPT-4-0314は8192(32k版は32768)まで対応していますが、これらのテストセットにおいて、少なくともゼロショットでは約128~200トークン以上に対応したアテンションは意味がありません。もし、意図的にベンチマークスコアに特化するのであれば、一般的なBERTモデルのように256~512トークン程度まで絞って訓練すれば、パラメータ数比で最良の結果が得られるはずです。
このことから、「AIのべりすと」においては、テストセットの評価はあまり重要視しておらず、小説コーパスやブックコーパスに対するvalidation lossが下がっているかどうかを訓練中は基準とし、最終的には短文・長文をそれぞれ読ませた上での実地試験を重ねてモデルを評価しているのが実情です。
一般的なテストセットにおいて評価できるファクターは大きく分けて「常識的な問題やロジック/算数の問題が解けるかどうか」と、「自然言語によって与えられたタスク(指示)に対応できるかどうか」の2つがあると考えられます。ただし、JSTSのような数値操作タスクは、英語コーパスはともかく日本語のコーパスにおいては非常にまれなので、一般的なデータセットではまず対応できません。日本語においても優秀な成績を残しているGPT-3.5やGPT-4においては、機械翻訳によってベースの指示チューニングセットを多言語に翻訳しているとみられますが、特にGPT-4においては口語的になると途端にロジックが飛んだり、完全に壊れたような出力になってしまうことがあります。
MARC-ja、JNLIのような選択方式の問題はサンプルの偏りや、モデルの英語性能も影響してきてしまうのがテストとしてみた時に気になるところです。
一般的に、小さな(特に、レイヤーの少ない)モデルほど、構文のわずかな差によって大きくテストの評価が変わってしまいます(数百億パラメータクラスのモデルで、なおかつ充分なユニークトークンで訓練されていればある程度の差異を飲み込むことができます)。現状、日本語のモデルは7B以下のコンパクトサイズのものが主流であり、この点に強く留意する必要があります。
英語をおもな評価対象とするモデルにおいても、GPT-3.5、GPT-4やClaudeといった良質のモデルは単にテストセットの点数が高いかどうかだけでなく、人間によるフォーカステスト等を行って「出力されるフォーマットや内容が人間にとって気持ち良いか・役に立つと感じるかどうか」というファクターを重視しているようです。これは既存のテストセットだけでは、ほぼ見通すことのできない部分です。
「スーパーとりんさま alpha2」は現在のところ、サブスク会員のみ利用できます(将来的に全員利用可能にする予定です)が、開発者向けAPIはアカウント(無料)を持っていれば利用できます。お試しください。
https://ai-novel.com/account_api.php
この記事が気に入ったらサポートをしてみませんか?