
【Python】プレイリスト内から動画情報を抽出する方法【備忘録】

ご無沙汰してました。
今回なのですが、『Vtuber・Vsinger音楽動画観測記録』を毎週アップされているmikan itoさんよりご依頼もあり、作成した、「Youtubeプレイリスト内の動画情報の抽出」をする方法について備忘録として書いていきたいと思います。
稚拙乱文ではありますが、あくまで個人の備忘録のような感覚なものなのでご了承ください。
1.概要
プレイリスト内に登録されている動画から以下の9要素を抽出するプログラムとなっております。
①チャンネル名
②公開日
③動画タイトル
④動画URL
⑤再生数
⑥コメント数
⑦高評価(評価数が隠されているものは「-1」で表示されます)
⑧低評価(現在では低評価を表示できないため「-1」が返されます)
⑨概要欄
この9要素をエクセルシートにcsv形式で書き出します。
2.コード
ソースコードは以下の通りになります。
一部ソースコードは「 こちら 」を利用し、依頼内容及び必要情報などのすり合わせを行い、調整をかけております。
以下のソースにつきましては、このままコピーしていただき、必要なパッケージにつきましては、適宜pip installを実行してください。
from googleapiclient.discovery import build
import json
import openpyxl
import re
import datetime
from datetime import date
from openpyxl.styles import Font
# 初期化
def initYoutube(API_KEY):
API_SERVICE_NAME = "youtube"
API_VERSION = "v3"
return build(API_SERVICE_NAME, API_VERSION, developerKey=API_KEY)
# プレイリストIDを渡して動画IDリストを得る
def getIdListFromPlaylist(id_,youtube):
nextPageToken = 'start'
response = []
while(nextPageToken is not None):
if(nextPageToken == 'start'):
search_response = youtube.playlistItems().list(
part= 'snippet',
playlistId=id_,
maxResults = 50,
).execute()
else:
search_response = youtube.playlistItems().list(
part= 'snippet',
playlistId=id_,
maxResults = 50,
pageToken = nextPageToken
).execute()
if('nextPageToken' in search_response):
nextPageToken = search_response['nextPageToken']
else:
nextPageToken = None
for item in search_response['items']:
response.append(item['snippet']['resourceId']['videoId'])
response.reverse()
return response
# YoutubeのAPIを使用し統計情報を取得する
def getCountDetails(id_, youtube):
#50件に分割
idLists = split_list(id_,50)
response = []
for idList in idLists:
search_response = youtube.videos().list(
part= 'statistics,snippet',
id=idList,
).execute()
response.extend(search_response['items'])
return response
# 指定するワークシートからIDリストを取得して数値を更新する
def setCountDetail(ws,idList,youtube):
result = getCountDetails(idList,youtube)
row = 1
ws.cell(row,1).value = 'チャンネル名'
ws.cell(row,2).value = '公開日'
ws.cell(row,3).value = 'タイトル'
ws.cell(row,4).value = 'URL'
ws.cell(row,5).value = '再生数'
ws.cell(row,6).value = 'コメント数'
ws.cell(row,7).value = '高評価'
ws.cell(row,8).value = '低評価'
ws.cell(row,9).value = '概要欄'
row += 1
for item in result:
published = datetime.datetime.fromisoformat(item['snippet']['publishedAt'].replace('Z', '+00:00')).strftime('%Y/%m/%d')
ws.cell(row,1).value = item['snippet']['channelTitle']
ws.cell(row,2).value = published
ws.cell(row,3).value = item['snippet']['title']
ws.cell(row,4).value = 'https://www.youtube.com/watch?v='+item['id']
ws.cell(row,9).value = item['snippet']['description'];
#非公開等がある場合は-1を表示
ws.cell(row,5).value = int(item['statistics']['viewCount']) if 'viewCount' in item['statistics'] else -1
ws.cell(row,6).value = int(item['statistics']['commentCount']) if 'commentCount' in item['statistics'] else -1
ws.cell(row,7).value = int(item['statistics']['likeCount']) if 'likeCount' in item['statistics'] else -1
ws.cell(row,8).value = int(item['statistics']['dislikeCount']) if 'dislikeCount' in item['statistics'] else -1
#ws.cell(row,4).hyperlink = ws.cell(row,3).value
ws.cell(row,5).number_format = '#,##0'
ws.cell(row,6).number_format = '#,##0'
ws.cell(row,7).number_format = '#,##0'
ws.cell(row,8).number_format = '#,##0'
row += 1
# 配列を指定した個数ごとに分割
def split_list(l, n):
for idx in range(0, len(l), n):
yield l[idx:idx + n]
# YoutubeAPI用キーの提示
API_KEY = '#ここに所得したYoutube用のAPIキーを入れる'
FILENAME = 'Youtube'
youtube = initYoutube(API_KEY)
#「ワークシート名:プレイリストID」の辞書配列作成
playList = {
'Vtuber music':'#ここに抽出したいYouTubeプレイリストIDを入れる',
}
# Excelファイル新規作成
wb = openpyxl.Workbook()
for key in playList:
wb.create_sheet(key,0)
setCountDetail(wb[key],getIdListFromPlaylist(playList[key],youtube),youtube)
#タイムスタンプ付けて保存
dt_now = datetime.datetime.now()
wb.save(FILENAME+dt_now.strftime('_%Y%m%d_%H%M')+'.xlsx')利用したソースコードとの相違点は以下の通りになります。
こちらについて、元ソースコードでは、
①投稿日
②動画タイトル
③動画URL
④再生数
⑤コメント数
⑥高評価数
⑦低評価数
の7要素となっておりましたが、依頼の内容において追加したのは以下の通りとなっており、以下の部分的なソースをご覧ください。
# 指定するワークシートからIDリストを取得して数値を更新する
def setCountDetail(ws,idList,youtube):
result = getCountDetails(idList,youtube)
row = 1
ws.cell(row,1).value = 'チャンネル名'
ws.cell(row,2).value = '公開日'
ws.cell(row,3).value = 'タイトル'
ws.cell(row,4).value = 'URL'
ws.cell(row,5).value = '再生数'
ws.cell(row,6).value = 'コメント数'
ws.cell(row,7).value = '高評価'
ws.cell(row,8).value = '低評価'
ws.cell(row,9).value = '概要欄'
row += 1
for item in result:
published = datetime.datetime.fromisoformat(item['snippet']['publishedAt'].replace('Z', '+00:00')).strftime('%Y/%m/%d')
ws.cell(row,1).value = item['snippet']['channelTitle']
ws.cell(row,2).value = published
ws.cell(row,3).value = item['snippet']['title']
ws.cell(row,4).value = 'https://www.youtube.com/watch?v='+item['id']
ws.cell(row,9).value = item['snippet']['description'];
#非公開等がある場合は-1を表示
ws.cell(row,5).value = int(item['statistics']['viewCount']) if 'viewCount' in item['statistics'] else -1
ws.cell(row,6).value = int(item['statistics']['commentCount']) if 'commentCount' in item['statistics'] else -1
ws.cell(row,7).value = int(item['statistics']['likeCount']) if 'likeCount' in item['statistics'] else -1
ws.cell(row,8).value = int(item['statistics']['dislikeCount']) if 'dislikeCount' in item['statistics'] else -1
#ws.cell(row,4).hyperlink = ws.cell(row,3).value
ws.cell(row,5).number_format = '#,##0'
ws.cell(row,6).number_format = '#,##0'
ws.cell(row,7).number_format = '#,##0'
ws.cell(row,8).number_format = '#,##0'
ということで変更点は以下の要素となっております。
①投稿されたチャンネル名の出力
②チャンネル内に表示されている概要欄の表示
を追加し出力するようにしております。
この2点が追加された理由としては、
チャンネル名:チャンネル内から引退などがあり、動画が消える場合があるので、その保存のため。
概要欄:概要欄の内容を検索したい場合があるから。
という前者はまだわかりますが、後者は謎のような理由ではありましたが、とりあえず追加しております。
また、このCSVを利用し作成された統計が以下のツイートになります。
Vtuber・Vsingerのオリジナル曲・カバー曲観測記録用のYouTubeプレイリスト「2022_Cover3」がいっぱいになった データ抽出時点で合計17037本(short動画含む)
— ito (@HankeshiWorker) September 21, 2022
データを書き出してもらったのでデータを更新しました
あくまで私🍊が見た動画の本数なのでその辺はご理解ください#Vtuber #Vsinger https://t.co/QlKiW864Gh pic.twitter.com/uJzkNutEXM
毎日観測しているVtuber・Vsingerの音楽系動画のプレイリストから日付別の投稿本数と曜日別の投稿本数をまとめてみた
— ito (@HankeshiWorker) August 3, 2022
期間は2022/1/1~8/1
ただし最終の1週間はデータが完全じゃないです
データの抽出は島田シロさん(MtG_pact
)に協力いただきました
週ごとにまとめてるやつ↓https://t.co/NPdLH2cBo6 pic.twitter.com/jRR4ceuVLp
また、以下のツイートツリーに関しては、概要欄を抽出していた予想外の使い方です。
今途中ですが歌詞に時間が入ってるのをいくつか
— ito (@HankeshiWorker) August 16, 2022
19時(午後7時)https://t.co/bYpPnghr5l
2時 https://t.co/ydmy2CV4Ue
10時 18時 24時 https://t.co/dslvn4xFpL
3時 12時 https://t.co/Cn1vYFCQXx
2時 https://t.co/KJZfRI793T
6時 8時 https://t.co/QFgRpebqMg
上記の内容としては、歌詞内に時刻が入っている楽曲を知りたいという事でしたが、オリジナル楽曲の場合概要欄に歌詞が入っていることがあったため、数曲のピックアップが可能となったレアなケースだったりもしますが、概要欄の抽出に関しては、外字が入っている場合や環境依存文字がある場合に関しては、環境によっては表示できない場合があるので、こちらに関しては注意が必要かと思います。
3.まとめ
以上、PythonとYoutube Data APIを利用してデータを収集する方法でした。
また、Youtube Data APIを利用する際の注意点があり、こちらには1日のデータ要求数に限りがあり、Google Cloud Platform内にあるIAMと管理から割り当てにて確認できます。
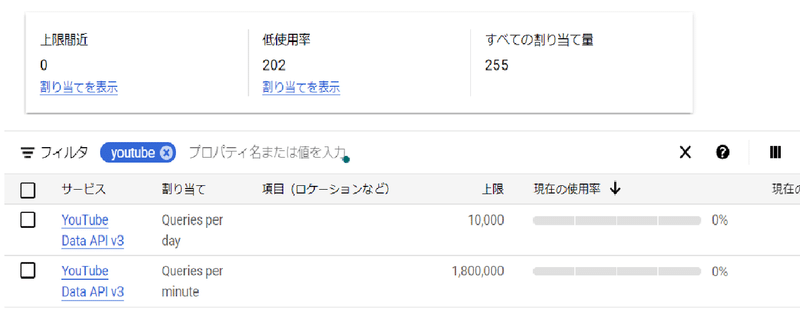
この割り当てが上限の際にリクエストを投げた場合、『quotaExceeded』が出た場合については、割り当て上限に到達したことを意味します。
今回のような利用の仕方をする場合、場合によってはすぐに上限に到達する場合があるので、ご注意いただければと思います。
4.おわりに
最後にちょっとした宣伝を。
本日このnoteの話題になったソースコードをご依頼いただいたmikan itoさんと共同にて運営させていただいているDiscordサーバをVtuber・Vsinger・Vliverのファンに向けて開放しています。
主に、創作やV全般の情報交換・布教などの場にできればと思っています。ご興味ありましたら是非覗いてみてください。
ライトユーザー多めですのであまりビビらずに入ってきてもらえればと思います。活動者の方も入っていただいても問題ありません。活動者専用のカテゴリ等も準備中です。詳細は下記のツイートとサーバの必読をご覧ください。
#Vtuber #Vsinger #Vliver ファン用Discordサーバやってます₍₍ (ง ˙ω˙)ว ⁾⁾
— ito (@HankeshiWorker) July 24, 2022
話題の動画・配信の話やちょっぴりマニアック話、ファンアート関連や配信のやり方関連などちょこちょこ面白そうな話もしてます。
ご興味あれば引用ツイへ
活動やってる方もどぞ(DM等の対策は各自でお願いします) https://t.co/yx2qdYiZpQ pic.twitter.com/7d51TK8Ial
遅筆乱文ではありましたが、最後までご覧いただきありがとうございます。
またいつ筆を執るかわかりませんが次回のnoteもご覧いただければ幸いです。
この記事が気に入ったらサポートをしてみませんか?