
[ChatGPT] 長文のボイスレコーダー文字起こしを読ませるTips

こんにちは、キン担ラボの本橋です。

TOMLプロンプトの記事にコメントを頂きまして、長文の書き起こしでChatGPTが受け付けてくれないケースがある、という事例を教えていただきました。
そこで今回は『ChatGPTに一度に渡せる文字数』に着目して調べてみました。
ChatGPT(GPT-3.5)が一度に受け付けてくれる文量は5000トークンくらい
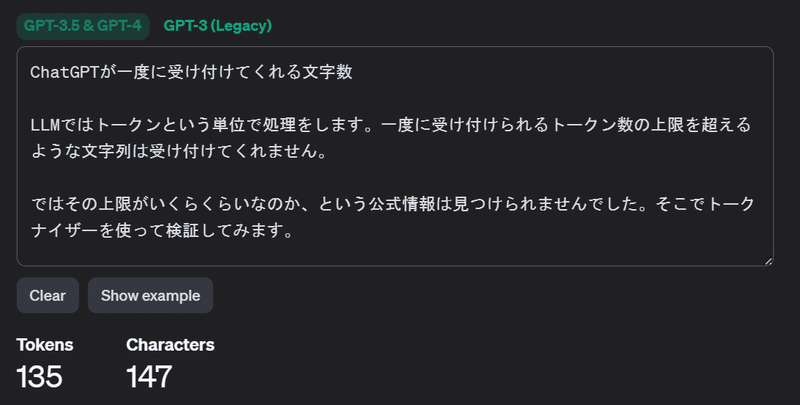
LLMではトークンという単位で処理をします。一度に受け付けられるトークン数の上限を超えるような文字列は受け付けてくれません。
その上限がいくらくらいなのか、という公式情報は見つけられませんでした。そこでトークナイザーを使って検証してみます。
(結論から言うと5000トークンを超えたあたりに閾値があるようでした)
Tokenizer
OpenAIが提供するトークナイザーのテスト用ページがあります。こちらのフォームに文字列を渡すとトークン数を算出してくれます。
普段使っているボイスレコーダー(DJI Mic)は、録音音声を30分ごとに区切ってファイル化します。普段はこの30分単位でWhisperに掛けて、一万文字くらいのテキストファイルを作成していました。
この一万文字を試しにトークナイザーにかけてみたところ、10000トークンくらいでした。GPT-4であれば受け付けてくれますが、GPT-3.5ではエラーになります。
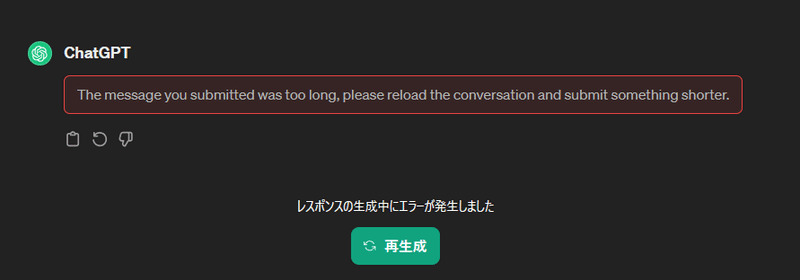
ドキュメントを見ると、gpt-3.5系のモデルでは出力が4096トークンまでとのことでした。
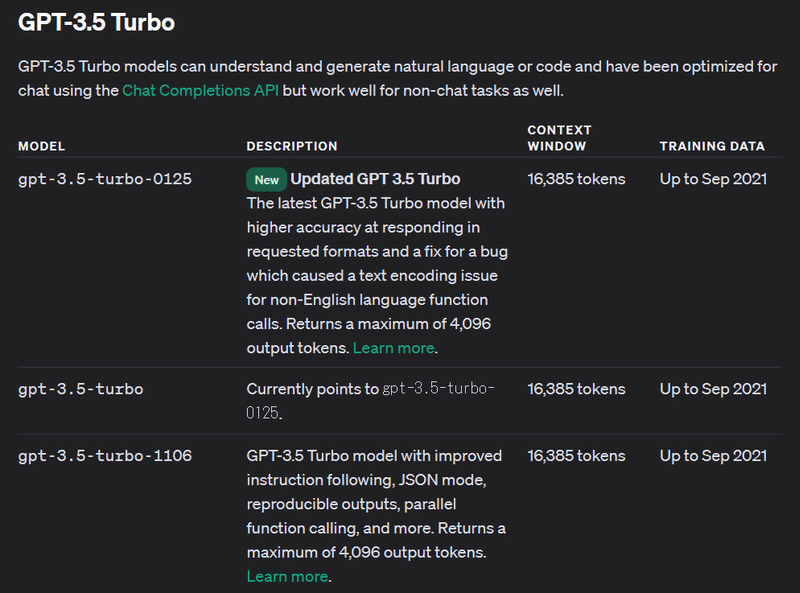
入力については見つからなかったのでGPT-4に聞いてみたところ、公開情報は無いとのこと。

4096トークンくらいみたいよ、とのことでした。
トークン数5400~6000くらいが上限らしい
では試してみます。
6000トークンくらいまで削ってみましたが、これはエラーです。
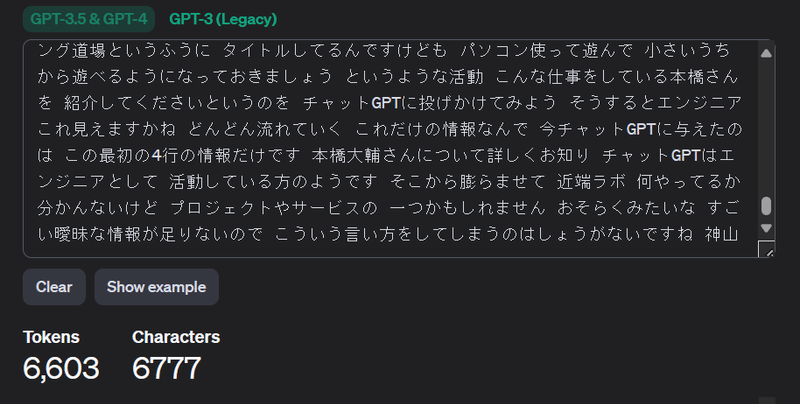
5000台まで削ったら通りました。

6000台ギリギリを攻めたらエラー

5400~6000トークンの間くらいに境目があったようです。このあたりで深追いはやめておくことにします。
GPT-3.5を使う場合は、トークン数5000を目安にすると良い
以上の調査結果から、GPT-3.5を使う場合は、トークン数5000くらいを目安に区切ると良いかと思います。ちなみにGPT-4を使ったところ2万トークンくらいまでは受け付けてくれていました。
このあたり、英語と日本語でも扱いが異なりそうです。今回の実験結果は参考程度に受け取っておいてください。
トークンとは何か
ではこのトークンというのは何なのでしょうか?
外形的には、トークナイザーを使うとトークン分割後の姿を見せてくれます。
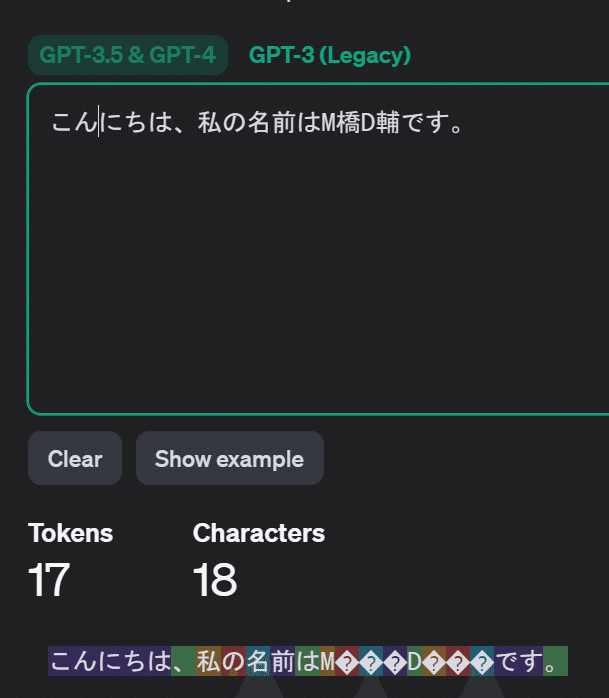
「こんにちは」で1トークン、「です」も1トークンでした。形態素単位ですね。
「私」「の」「名」「前」「は」あたりはそれぞれ1文字1トークンです。
"M橋D輔"のあたりでは「M」「D」は1文字1トークンですが、「橋」「輔」は1文字あたり3トークンとなっています。
この様子から分かることは、よく出現する単語や形態素は1トークンが割り当てられ、そこそこ出現する文字にも1トークンが割り当てられ、頻出とまでは言えない日本語の漢字なんかは3トークンで表現するわけですね。
トークン分割のアルゴリズムは、おそらくですが学習元のコーパスから統計的に求めているのではないかと思います。
リクエスト数の上限
ここまで調べたらせっかくなのでリクエスト数の上限も見てみます。
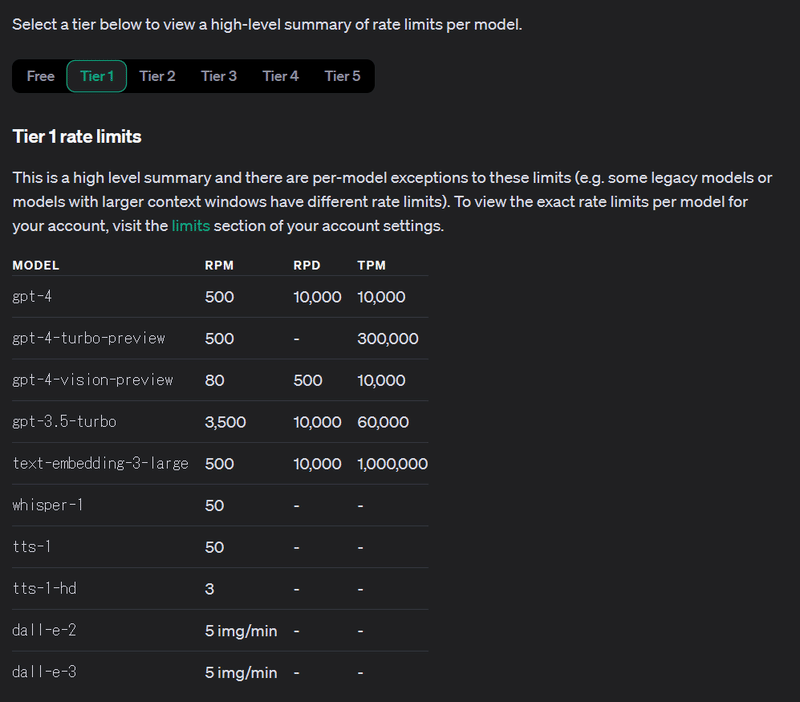
RPM、RPD、TPMはそれぞれ以下の通りです。
RPM - requests per minute
1分間あたりのリクエスト回数
RPD - requests per day
1日あたりのリクエスト回数
TPM - tokens per minute
1分間あたりのトークン数
TPD - tokens per day
1日あたりのトークン数
IPM - images per minute
1分あたりの画像数
上限はTier別に決められています。Tierというのはこれまでに支払った利用料の合計と期間で決められているようです。自分のティアがいくつか、というのはOpenAIのアカウントページにあるLimitsから見ることができます。

ティア3の上限は以下の通り。

gpt-4-turboを使えば1分間あたり60万トークンまで受け入れてもらえるようです。なお注釈として、人によってレートリミットは異なるかもよ、とも書いてありました。
普段の使い方
参考になるかはわかりませんが、僕の普段の使い方は以下のとおりです。
DJI Micで録音する
自動的に30分区切りで音声ファイルが作成される
ファイル単位でWhisperAPIに投げてtxtを作成する
ChatGPTに投げてブログの下書きや講演要約のmarkdownを作成する
noteに貼り付けたりpythonのpandocでWord化して利用する
わりと最近になって気づいたのですが、markdown形式のテキストをnoteにコピペすると見出しや箇条書きを反映させてくれます。
それと仕事ではGoogle Workspaceを使用しているので、Google Document形式にしたいときはpythonのpandocを使ってお手軽Word化をして貼り付けたりもしています。
このあたりの日常業務の流れも今度書いてみようと思います。
ボイスレコーダーを活用しよう
ボイスレコーダーに音声を吹き込むのは慣れが必要です。でも一旦慣れてしまえばとても快適です。キーボードを打つ代わりに頭の中で文章をタイプして、漢字変換キーを押す代わりに読み上げるようなイメージです。
ソロバンの達人は頭の中にソロバンをイメージして計算するため物理的な制約を受けずに高速計算できるそうで、戦後すぐくらいまではコンピューターより高速に計算できたそうです。(コンピューターと言っても電動の機械式計算機でしたが)
それはさておき、キーボード入力に慣れている我々世代はともかく、将来的に音声入力が主流になるのは間違いありません。「キーボード入力できるんですね、すごーい!」とか言われかねない時代に備えて今から音声入力を練習しておきましょう。
録音はスマホでもよいですが、僕は車の運転中に一人で喋って記録を取っていることが多いため、ボイスレコーダーを使っています。DJI Micが最高に使いやすいです。
初代が安くなっていたら初代もありだと思います。僕が買ったときは5万円くらいだったマイクx2のセットが今見たら37,400円、25%OFF。
Whisperとボイスレコーダーの音声入力ライフをお楽しみください!

この記事が気に入ったらサポートをしてみませんか?