LLMでTransformer 論文以降の進化系統

トランスフォーマー(Transformer)モデルの登場以降、自然言語処理(NLP)において多くの進化が見られました。以下にその進化の系統図を示します:
Transformer (2017)
Vaswaniらによって発表されたこのモデルは、自己注意(Self-Attention)機構を用いることで文脈全体を捉えることが可能となり、NLPの分野に革命をもたらしました。
BERT (Bidirectional Encoder Representations from Transformers, 2018)
Googleによって開発されたBERTは、Transformerのエンコーダーを双方向に適用することで、文脈の理解を一層深めました。これにより、様々な言語タスクで顕著な成果を上げることができました。
GPT (Generative Pre-trained Transformer, 2018)
OpenAIによるGPTは、事前学習と微調整を組み合わせることで、広範な応用が可能なモデルを実現しました。GPTはデコーダのみを使用し、次に来る言葉を予測する形で学習されます。
RoBERTa (A Robustly Optimized BERT Pretraining Approach, 2019)
BERTの事前学習手法を改良し、より長いトレーニング、より大きなバッチサイズ、マスクされた言語モデリングの最適化に焦点を当てました。
T5 (Text-To-Text Transfer Transformer, 2019)
GoogleのT5はすべてのNLPタスクをテキスト生成問題として扱うことを目指し、多様なデータセットでの事前学習を通じて高い汎用性を実現しました。
XLNet (2019)
Transformer XLの進化形として開発されたXLNetは、パーマネントシャッフルを利用してBERTの制約を克服し、より一般化されたモデルを実現しました。
これらは、Transformerモデル以降の代表的な進化形の一部に過ぎませんが、これらのモデルはさまざまな改良を経て、より精度の高い予測や、より広範なタスクへの応用が可能になっています。それぞれが持つ独自のアプローチは、NLPのさらなる発展に貢献しています。
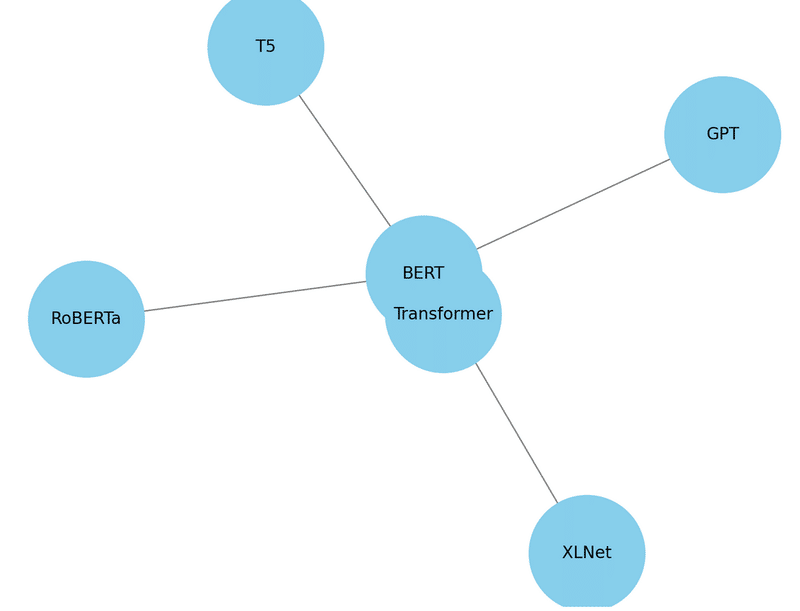
1から6のモデル間の依存関係は、各モデルがどのようにして前のモデルから影響を受けたか、そしてどのようにしてそれを発展させたかに焦点を当てて解説することができます。以下にその関係性を示します:
Transformer
基礎となるモデルであり、自己注意機構と位置エンコーディングが特徴です。この基本構造は後の多くのモデルで採用されています。
BERT
Transformerのエンコーダ構造をベースにして、双方向のコンテキスト理解を可能にしたモデルです。BERTはTransformerの自己注意機構を利用しつつ、マスク付き言語モデルと次文予測を取り入れることで新たな学習手法を導入しました。
GPT
Transformerのデコーダ部分を拡張して構築されており、生成タスクに特化しています。BERTとは異なり、一方向の予測に焦点を置いていますが、基本的なアーキテクチャはTransformerに由来しています。
RoBERTa
BERTの直接的な改良版であり、BERTが導入した技術をさらに洗練させ、事前学習プロセスを改善しました。特に、ダイナミックなマスキングや長期間の学習などが導入されています。
T5
BERTやGPTのような以前のモデルから影響を受けつつ、すべてのNLPタスクをテキスト対テキストの問題として統一的に扱う新たなアプローチを導入しました。Transformerのエンコーダーとデコーダーのフルセットを使用しています。
XLNet
BERTのアイデアを引き継ぎながら、パーマネントシャッフルという新しい技術を導入することで、単語の順序に依存しないより一般的なモデルへと進化させました。XLNetはTransformerの自己注意機構を利用していますが、BERTの双方向性をより動的な形で解釈しています。
これらのモデルは、それぞれが前のモデルのアイデアを取り入れつつ、新たな課題への解決策や改良を加えることでNLPのフィールドを進化させてきました。
この記事が気に入ったらサポートをしてみませんか?